 高通AI Hub:轻松实现Android图像分类
高通AI Hub:轻松实现Android图像分类
上一篇博文“Qualcomm AI Hub介绍”。高通AI Hub为开发者提供了一个强大的平台,以优化、验证和部署在Android设备上的机器学习模型。这篇文章将介绍如何使用高通AI Hub进行图像分类的程式码开发,并提供一个实际的例子来展示其在Android平台上的应用。
程式码介绍
高通AI Hub支持多种机器学习框架,如TensorFlow Lite、Quancomm AI Engine Direct和ONNX Runtime,并能够将训练好的模型转换为优化的on-device执行格式。开发者可以通过AI Hub的模型库,选择适合自己应用需求的模型,并进行相应的优化。此外,AI Hub还提供了详细的on-device性能分析工具,帮助开发者了解模型在实际设备上的运行情况。
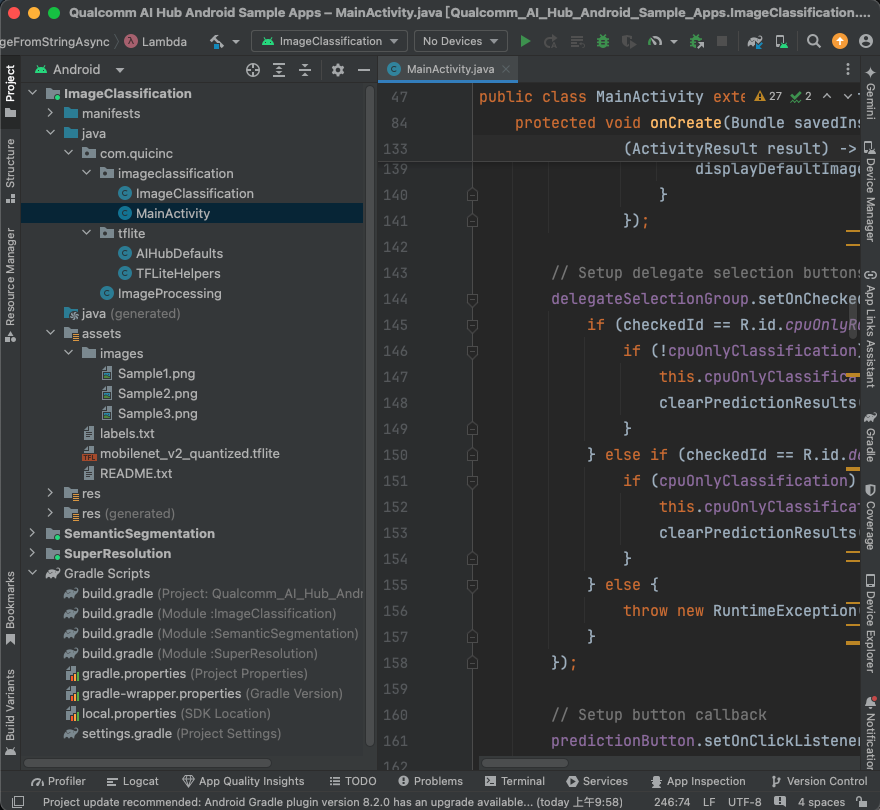
于官方提供的Github ai-hub-apps进行下载,使用Android Studio开启app/android,就可以看到ImageClassification、SemanticSegmentation及SuperResolution,本篇博文介绍ImageClassification程式码的部分及执行,使用Android Studio开启专案画面如下图:
ImageProcessing.java:
里面有一个静态方法 resizeAndPadMaintainAspectRatio,其功能是调整图片大小,同时维持图片的宽高比(Aspect Ratio)。如果图片无法完全符合给定的输出尺寸,则会加入填充区域(padding),使得最终输出的图片符合要求的宽度和高度。
TensorFlow Lite (TFLite) 的辅助工具,用于为 TensorFlow Lite 模型建立解译器(interpreter)和相应的硬件加速委派(delegate),例如 GPU 或 NPU。主要功能是根据指定的硬件加速选项,自动尝试为 TFLite 模型分配不同的硬件委派来优化推论性能。
CreateInterpreterAndDelegatesFromOptions
用于根据指定的优先级顺序,创建 TFLite 解译器并分配硬件加速委派。它会根据委派的优先顺序来尝试分配不同的委派类型,如 GPU 或 NPU,并在无法使用时降级至 CPU 运算(例如使用 XNNPack 提供的 CPU 加速)。
CreateInterpreterFromDelegates
此函式实际上是根据之前创建的委派来生成解译器。主要负责配置 TFLite 解译器的参数,例如 CPU 线程数和是否使用 XNNPack 作为后备计算选项。若解译器创建失败,则会记录失败原因并返回 null。
CreateDelegate
此函式根据指定的委派类型(如 GPUv2 或 QNN_NPU)创建对应的硬件委派。每一个委派都有对应的函式进行初始化,例如 CreateGPUv2Delegate 或 CreateQNN_NPUDelegate。
CreateGPUv2Delegate
这个函式负责创建和配置 GPUv2 委派,它会将 GPU 设定为最大性能模式,允许使用浮点精度 FP16 进行计算,来提升 GPU 运行效率。
CreateQNN_NPUDelegate
此函式负责为支持 Qualcomm NPU 的装置创建 QNN 委派,根据装置支持的硬件类型来选择使用 DSP 或 HTP 来加速推论计算。
ImageClassification.java:
基于 TensorFlow Lite 的影像分类器,用来从给定的影像中推测出最有可能的物件类别。主要的功能包括模型的加载、预处理影像、推论以及后处理推论结果,并且能够返回处理时间等性能资讯。
ImageClassification
功能:从指定的模型和标签路径中创建影像分类器。
参数:
context:应用程式的上下文。
modelPath:模型文件的路径。
labelsPath:标签文件的路径。
delegatePriorityOrder:指定计算单元优先顺序(例如 GPU、CPU 等)。
preprocess
功能:将输入的影像预处理为模型可以接受的格式。
步骤:
检查影像尺寸是否符合模型的输入要求,必要时进行缩放。
根据模型的数据类型(如 FLOAT32 或 UINT8)转换影像数据。
postprocess
功能:将模型输出的结果转换为可读取的标签(类别)。
步骤:
读取模型的输出。
根据预测值选出信心最高的几个结果(TOP-K),并转换为对应的标签名称。
predictClassesFromImage()
功能:对给定的影像进行分类,返回最有可能的类别。
步骤:
进行预处理(preprocess)。
使用解释器进行推论。
后处理输出结果(postprocess)。
返回分类结果。
findTopKFloatIndices() 和 findTopKByteIndices()
功能:从模型输出的数据中找出信心最高的 K 个结果,分别处理 float 和 byte 类型的输出。
实现:使用优先伫列(PriorityQueue)来追踪最大值,并返回这些最大值对应的索引。
MainActivity.java:
使用 TensorFlow Lite 来进行影像分类。它主要负责初始化 UI 元件、管理影像选择与处理、并进行模型推论。如果执行时发生图像读取错误问题,需要在loadImageFromStringAsync函式做调整:
// try (InputStream inputImage = getAssets().open("images/" + imagePath))
try (InputStream inputImage = getAssets().open( imagePath))
模型及App执行
TFLite模型:
模型部分可以依据AI Hub提供的Image Classification选项的TFLite模型,下载自己所需的模型,并放置于ImageClassification/src/main/assets档案夹底下,修改Android Studio内的 gradle.properties,修改:classification_tfLiteModelAsset=xxxxxxx.tflite
程式运作:
高通AI Hub提供的Android程式码,除了在高通提供相关芯片的开发板上执行,也可以在拥有高通芯片的手机上执行,实机测试是使用小米11手机。
执行结果如下方Gif动画,App最下方Image透过下拉式选单选择内建的三张图片或相簿图片,选择完成后上方会出现选择的图片,按下RUN MODEL按钮即可开始推论,当然也可以选择CPU Only体验一下没有硬件加速的推论时间,而All Hardware则会使用QNN_NPU + GPUv2 + XNNPack等硬件加速。

小结
本篇博文就到这里,通过高通AI Hub Android开发者可以更轻松地将先进的AI模型集成到他们的应用中。高通AI Hub的文档和模型库提供了丰富的资源,帮助开发者探索和实现AI领域的应用。
参考
ai-hub-apps
AI Hub Image Classification
Q&A
问:如何获取高通AI Hub Model的ImageClassification模型?
答:您可以访问高通AI Hub的GitHub页面或官方网站,这里提供了模型的开源代码和安装指南。
问:部署模型时需要注意哪些性能和精度问题?
答:在部署模型时,您需要考虑模型的延迟、记忆体使用等性能指标,以及模型在特定设备上的精度。高通AI Hub提供了性能指标和优化指南,帮助您选择最适合您需求的模型。
问:如果在部署过程中遇到问题,该如何解决?
答:如果在模型部署过程中遇到性能、精度或其他问题,您可以通过高通AI Hub的支持Slack 提交问题。此外,您也可以参考官方文档中的疑难解答部分。
问:高通AI Hub Model可以在哪些设备上运行?
答:高通AI Hub Model支持在多种设备上运行,包括但不限于Snapdragon 845, Snapdragon 855/855+, Snapdragon 865/865+, Snapdragon 888/888+等多款芯片组的设备。
登录大大通网站阅读原文,提问/评论,获取技术文档等更多资讯!
-
高通
+关注
关注
76文章
7465浏览量
190617 -
Android
+关注
关注
12文章
3936浏览量
127392 -
开发板
+关注
关注
25文章
5049浏览量
97445 -
Qualcomm
+关注
关注
8文章
673浏览量
52107 -
tensorflow
+关注
关注
13文章
329浏览量
60535
发布评论请先 登录
相关推荐
ASTRA AI Hub详细介绍
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测-迅为电子

RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
计算机视觉怎么给图像分类
高光谱成像光源 实现对细微色差的分类

高通AI Hub支持骁龙X系列,赋能Windows PC终端AI
OpenAI发布图像检测分类器,可区分AI生成图像与实拍照片
高通AI Hub助力开发者解锁终端侧AI潜力
高通发布AI Hub平台和Wi-Fi7芯片, 助力开发人员构建AI模型和多终端用例

高通推出全新AI Hub,使AI推理速度最高提升4倍
高通AI Hub为开发者开启卓越终端侧AI性能
MWC2024:高通推出全新AI Hub及前沿多模态大模型
IoT Hub是什么?IoT Hub的应用场景
利用AI实现自动图像标注不是梦






 工商网监
工商网监
评论