 经典图神经网络(GNNs)的基准分析研究
经典图神经网络(GNNs)的基准分析研究

本文简要介绍了经典图神经网络(GNNs)的基准分析研究,发表在 NeurIPS 2024。
文章回顾了经典 GNNs 模型在节点分类任务上的表现,结果发现过去 SOTA 图学习模型报告的性能优越性可能是由于经典 GNNs 的超参数配置不佳。通过适当的超参数调整,经典 GNNs 模型在 18 个广泛使用的节点分类数据集中的 17 个上超越了最新的图学习模型。本研究旨在为 GNNs 的应用和评估带来新的见解。

论文题目:Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification
论文链接:
https://arxiv.org/abs/2406.08993
代码链接:
https://github.com/LUOyk1999/tunedGNN
引言节点分类是图机器学习中的一个基本任务,在社交网络分析、生物信息学和推荐系统等多个领域中具有广泛的高影响力应用。图神经网络(GNNs)已成为解决节点分类任务的强大模型。 GNNs 通过迭代地从节点的邻居中聚合信息,这一过程被称为消息传递,利用图结构和节点特征来学习有用的节点表示进行分类。尽管 GNNs 取得了显著的成功,但研究指出它们存在一些局限性,包括过度平滑、过度压缩、对异质性缺乏敏感性以及捕获长距离依赖的挑战。 最近,Graph Transformer(GTs)作为 GNN 的替代模型受到越来越多的关注。与主要聚合局部邻域信息的 GNNs 不同,Transformer 架构通过自注意力层可以捕获任意节点对之间的交互。GTs 在图级任务(如涉及小规模图的分子图分类)上取得了显著成功。 这一成功激发了尝试将 GTs 应用于节点分类任务的努力,特别是在大规模图上,以应对 GNNs 的上述局限性。尽管最新的 GTs 取得了令人鼓舞的成果,但观察到许多此类模型在显性或隐性层面上仍然依赖于消息传递来学习局部节点表示,将其与全局注意力机制结合以获得更全面的表示。 这促使我们重新思考:消息传递 GNNs 在节点分类中的潜力是否被低估了?虽然已有研究在一定程度上解决了这一问题,但这些研究在范围和全面性上仍存在局限性,例如数据集数量和多样性有限,以及超参数的考察不完整。 在本研究中,我们全面重新评估了 GNNs 在节点分类中的表现,使用了三种经典的 GNNs 模型—— GCN、GAT和 GraphSAGE ——并在 18 个真实世界的基准数据集上进行了测试,包括同质性、异质性和大规模图。 我们考察了 GNNs 训练中的关键超参数对其性能的影响,包括 normalization、dropout、residual connections 和 network depth。主要发现总结如下:
经过适当的超参数调整,经典 GNNs 在同质性和异质性图中的节点分类任务中均能取得高度竞争力的性能,甚至在节点数量达百万量级的大规模图上也是如此。值得注意的是,经典 GNNs 在 18 个数据集中有 17 个超越了最先进的图学习模型,表明 GTs 对比 GNNs 所宣称的优势可能是由于在 GNNs 评估中超参数配置不佳
我们的消融研究对 GNNs 节点分类中的超参数提供了见解。我们验证了:
Normalization 对于大规模图至关重要
Dropout 一致地表现出积极影响
Residual connections 在异质性图上可以显著增强性能
在异质性图上,较深的层数可能更适合 GNNs
方法介绍
2.1 数据集概述
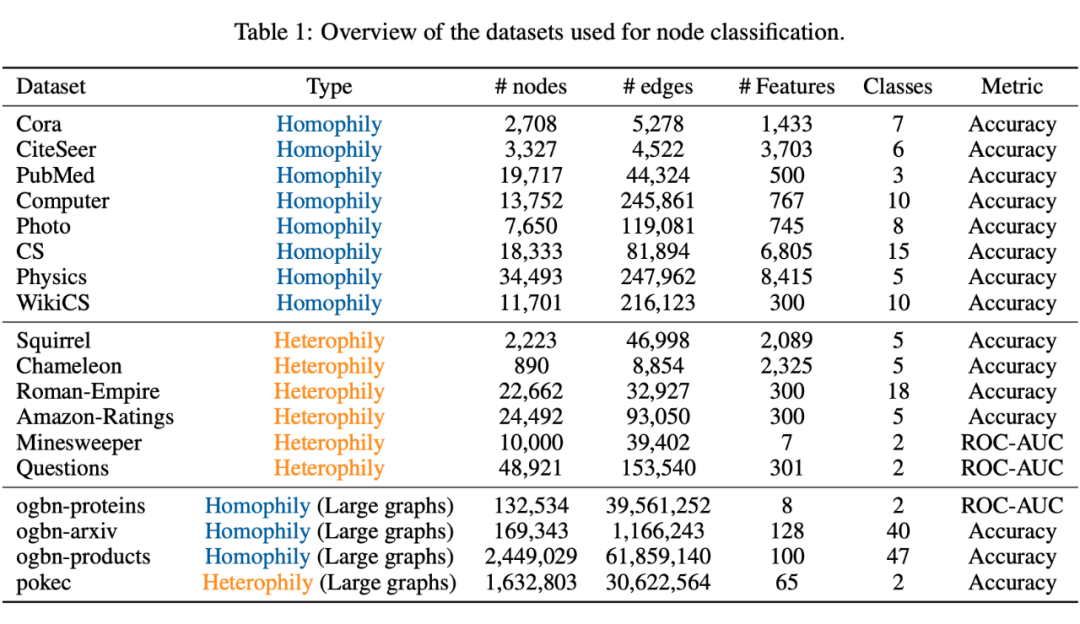
同质性图:Cora、CiteSeer 和 PubMed 是三种常用的引用网络[1]。我们遵循传统的半监督设定[2]来划分数据集。此外,Computer 和 Photo 是公共购买网络[3],CS 和 Physics是公共作者网络[3],我们采用训练/验证/测试划分为 60%/20%/20% 的标准[4]。我们还使用了 Wiki-CS [5],该数据集是由计算机科学论文组成的引用网络,我们使用[5]的划分。
异质性图:Squirrel 和 Chameleon 是两个 Wikipedia 特定主题的页面网络[6]。我们采用异质图基准测试[7]中的新的数据集划分。此外,我们还使用 Roman-Empire、Amazon-Ratings、Minesweeper 和 Questions 四个异质性数据集[7],这些数据集的划分和评估指标遵循其来源[7]的标准。大规模图:我们使用了由 Open Graph Benchmark(OGB)[8]发布的多个大规模图,包括 ogbn-arxiv、ogbn-proteins 和 ogbn-products,节点数量从 0.16M 到 2.4M 不等。此外,我们还分析了社交网络 pokec [9]的性能表现。
2.2 超参数设置
我们的重点在于经典 GNNs 模型(GCN、GraphSAGE、GAT)与最先进的图学习模型的比较。我们对经典 GNNs 进行了超参数调整,并与 Polynormer [4] 的超参数搜索空间保持一致。同时,所有基准baselines也在相同的超参数搜索空间和训练环境下重新训练。
2.3 关键超参数在本节中,我们概述了 GNNs 训练中的关键超参数,包括 normalization、dropout、residual connections 和 network depth。这些超参数在不同类型的神经网络中被广泛应用,以提升模型性能:
Normalization:在每一层激活函数之前使用 layer normalization(LN)或 batch normalization(BN),可以减少协变量偏移,稳定训练过程并加速收敛。
Dropout:在激活函数之后对特征嵌入使用 dropout 来减少隐藏神经元间的共适应,有助于降低 GNNs 中消息传递的共适应效应。
Residual Connections:通过在层之间引入 residual connections,可以缓解梯度消失问题,增强 GNNs 的表现力。
Network Depth:尽管深层网络能够提取更复杂的特征,但 GNNs 在深度上面临独特挑战,如过度平滑等。因此,大多数 GNNs 采用较浅的结构,通常包含 2 到 5 层。然而,我们的实验发现如果搭配上 residual connections,GNNs 可以拓深至 10 层的网络。
实验结果
3.1 主要发现
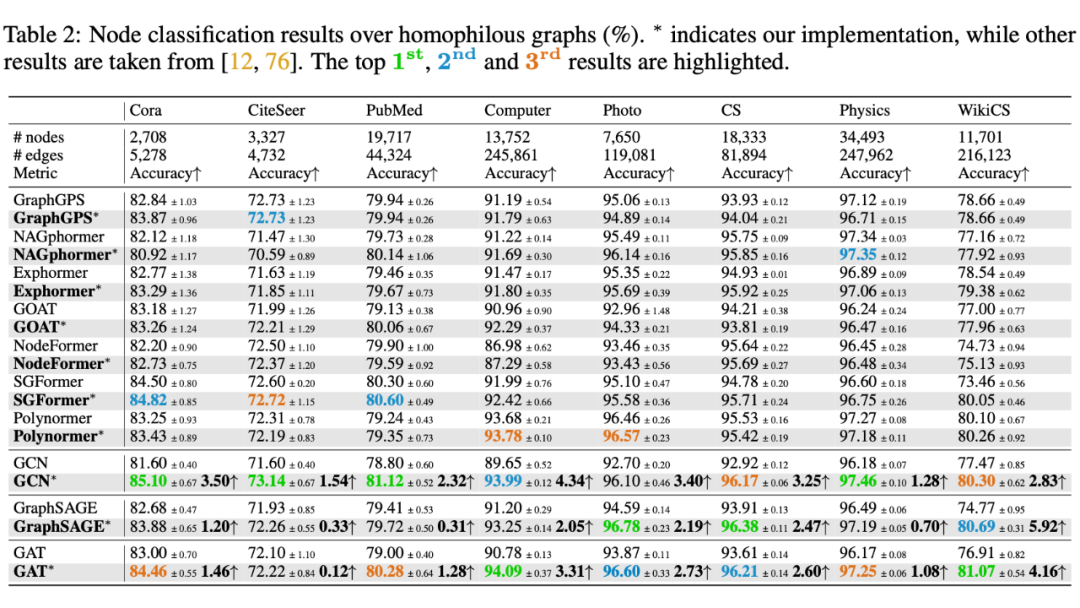
关于同质性图的观察:经典 GNNs 在同质性图的节点分类任务中,仅需对超参数进行轻微调整,便能够具备很强的竞争力,且在很多情况下优于最先进的 GTs。
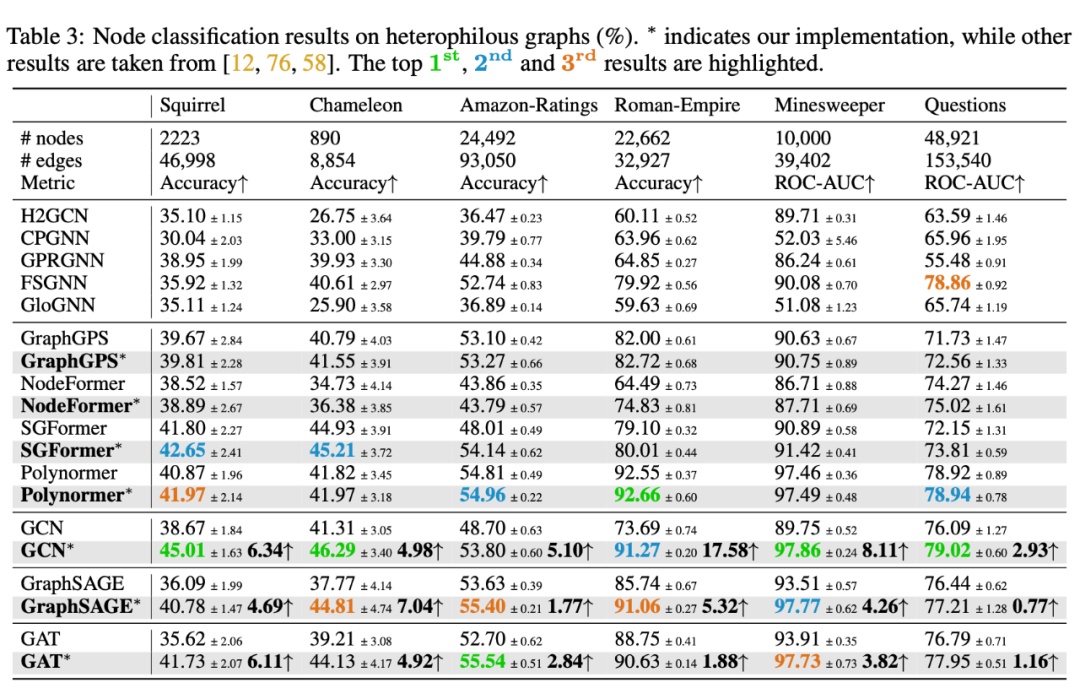
关于异质性图的观察:我们的参数调整显著提高了经典 GNNs 在异质性图上的先前最佳结果,超越了为此类图专门设计的专用 GNNs 模型,甚至超过了 SOTA GTs 架构。这一进展不仅支持了[7]中的发现,还进一步强化了其结论,即经典 GNNs 在异质性图上也是强有力的竞争者,挑战了它们主要适用于同质性图结构的普遍假设。
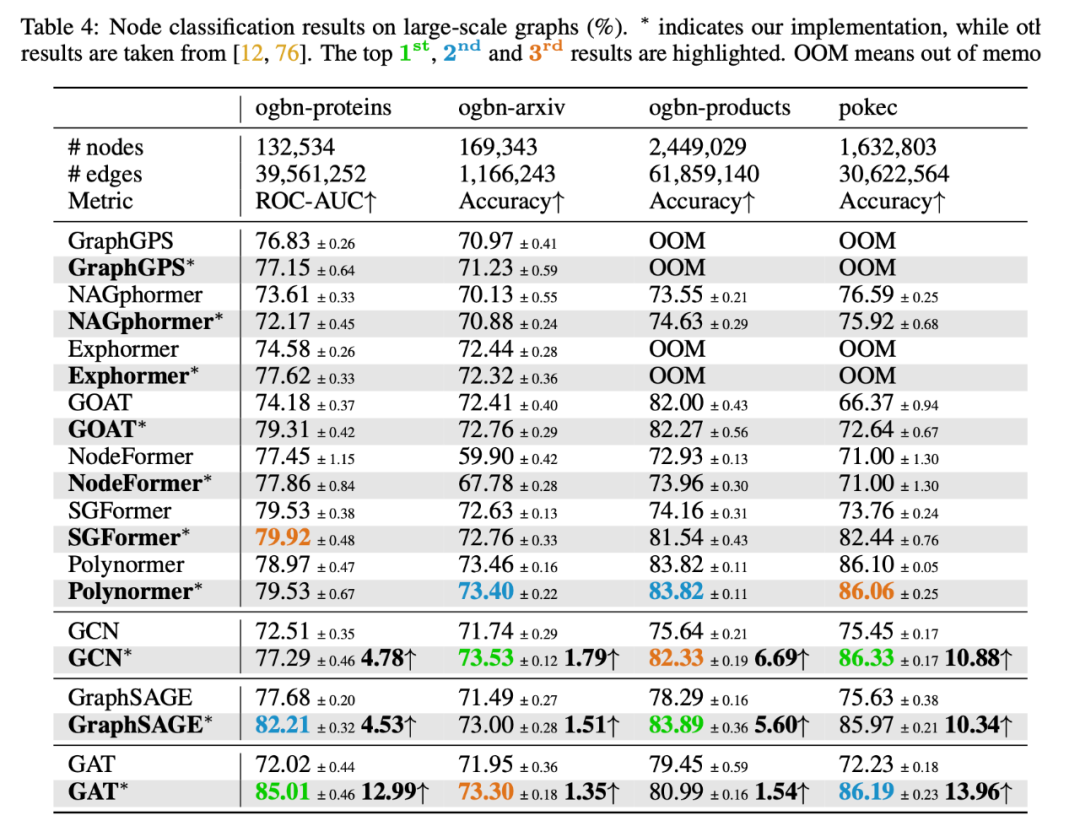
关于大规模图的观察:我们的参数调整显著提升了经典 GNNs 的先前结果,在某些情况下准确率提升达到了两位数。它们在这些大规模图数据集(无论是同质性还是异质性)中取得了最佳结果,甚至超过了最先进的 GTs。这表明消息传递在大规模图上学习节点表示仍然非常有效。
3.2 消融分析
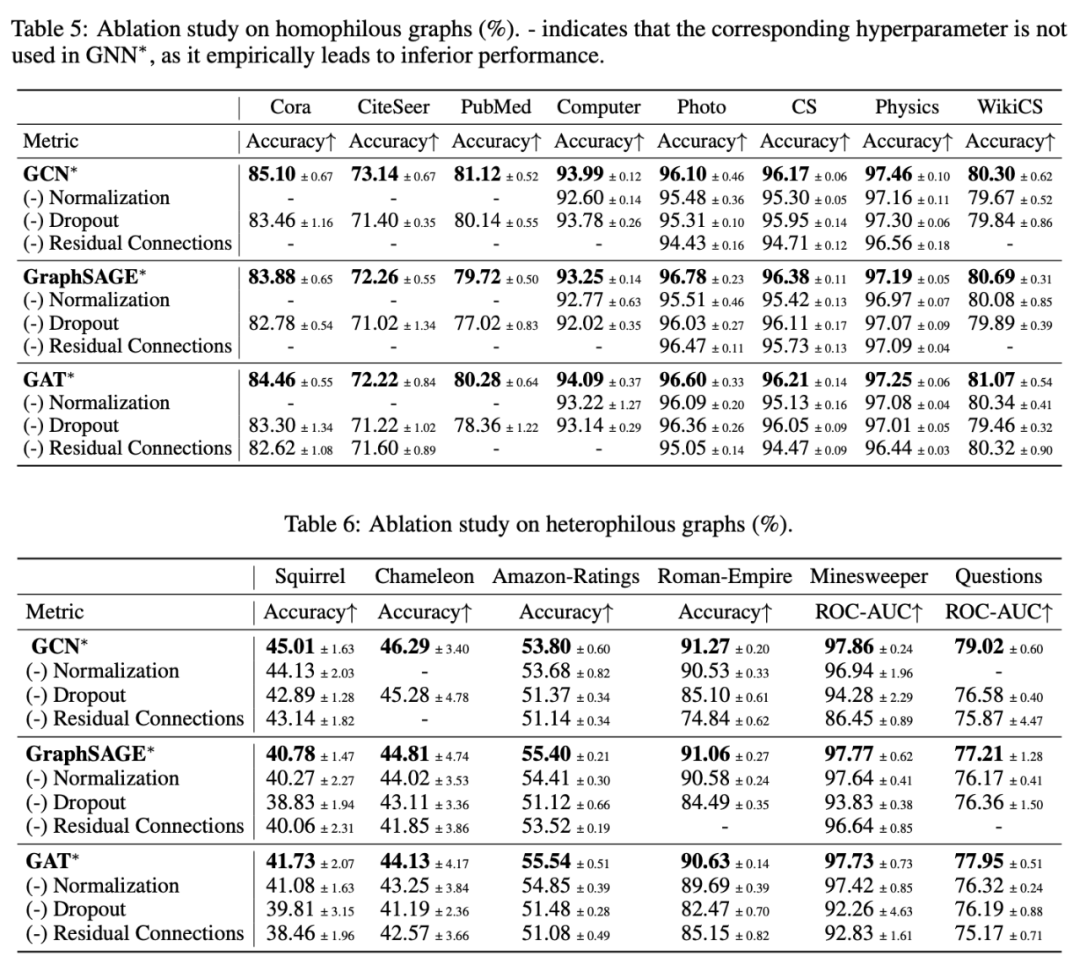
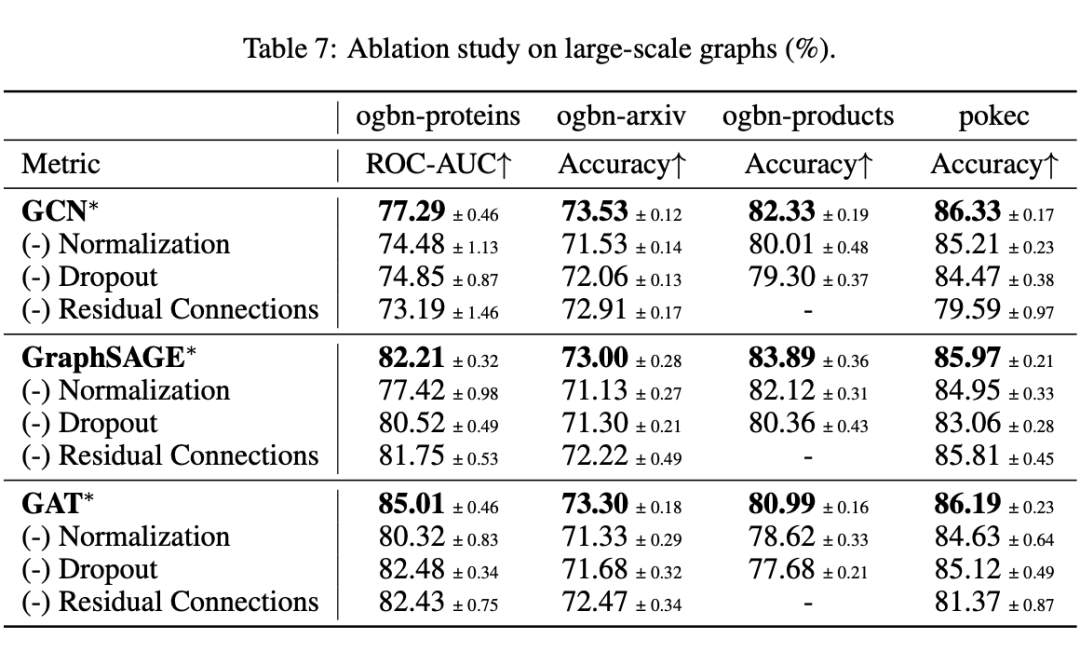
消融观察 1:Normalization 在大规模图的节点分类中非常重要,但在小规模图中则不太显著。
消融观察 2:Dropout 对于节点分类始终是必要的。
消融观察 3:Residual Connections 能够显著提升某些数据集上的性能,且在异质性图上的效果比同质性图上更为显著。 消融观察 4:更深的网络通常在异质性图上带来更大的性能提升,相较于同质性图表现更为明显。
总结我们的研究对经典 GNNs 模型在节点分类任务中的有效性进行了全面的重新评估。通过广泛的实证分析,我们验证了这些经典 GNNs 模型能够在各种图数据集上达到甚至超越最先进图学习模型的性能。
此外,我们的全面消融研究提供了关于不同 GNNs 超参数如何影响性能的见解。我们希望我们的研究结果为 GNNs 的应用和评估带来新的见解。
-
神经网络
+关注
关注
42文章
4845浏览量
108341 -
机器学习
+关注
关注
67文章
8570浏览量
137390
原文标题:NeurIPS 2024 | 全面重新评估!经典GNN是强有力的节点分类基线模型
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于神经网络的负载机械速度估计器实现方案

为什么 VisionFive V1 板上的 JH7100 中并存 NVDLA 引擎和神经网络引擎?
神经网络的初步认识

CNN卷积神经网络设计原理及在MCU200T上仿真测试
NMSIS神经网络库使用介绍
在Ubuntu20.04系统中训练神经网络模型的一些经验
CICC2033神经网络部署相关操作
液态神经网络(LNN):时间连续性与动态适应性的神经网络
神经网络的并行计算与加速技术
无刷电机小波神经网络转子位置检测方法的研究
神经网络专家系统在电机故障诊断中的应用
神经网络RAS在异步电机转速估计中的仿真研究
六相永磁同步电机串联系统控制的两种方法分析研究
基于FPGA搭建神经网络的步骤解析




评论