 19位国际顶尖学者联袂撰写《重新审视边缘人工智能:机遇与挑战》
19位国际顶尖学者联袂撰写《重新审视边缘人工智能:机遇与挑战》
本文转自:边缘计算社区

19位欧美顶尖学者联合撰写的重磅论文,由边缘计算社区倾力翻译完成,如有不足之处,敬请指正。本论文首发于 IEEE Internet Computing:
《Revisiting Edge AI: Opportunities and Challenges》
(重新审视边缘人工智能:机遇与挑战)
发表日期:2024年7-8月
期刊卷号:第28卷,第49-59页
DOI:10.1109/MIC.2024.3383758
本文深度剖析了边缘人工智能(Edge AI)的最新发展动态,全面探讨了当前的机遇与挑战,为产业界与学术界提供了重要的指导性洞见。
以下是翻译全文,共计 10280 字。重新审视边缘人工智能:机遇与挑战
边缘人工智能(Edge AI)是一种创新的计算范式,旨在将机器学习模型的训练和推理移至网络边缘。该范式带来了极大的潜力,可以通过诸如自动驾驶、个性化健康护理等新服务显著改善我们的日常生活。然而,边缘智能的实现面临诸多挑战,比如模型架构设计的约束、已训练模型的安全分发与执行,以及分发模型和训练数据所需的高网络负载。本文总结了边缘AI的发展关键节点,分析当前的挑战,并探讨将人工智能与边缘计算结合的研究机遇。
边缘计算的重要转变
边缘计算是一种重要的范式转变,通过将数据处理更靠近数据源,正在重塑互联网和应用的格局。这一战略性演进有望提升效率、响应速度,并更好地保护隐私。从以云为主的解决方案起步,如今越来越多的应用正在沿着计算连续体向边缘设备靠近。虽然过去对边缘设备的定义有多种不同解释,从用户终端设备到小型本地化数据中心,但边缘设备的总体特性是相似的:靠近用户并在本地处理数据。
尽管近年来边缘解决方案的普及度有所提高,但其部署速度仍然相较于云市场的增长显得相对较慢。这可以归因于建设和管理分布式基础设施的高成本,以及相比于仅为云构建应用,开发边缘应用的相对复杂性。
人工智能(AI)的兴起及其对训练数据的巨大需求,使得利用边缘设备进行训练和推理成为一个显而易见的后续发展趋势。机器学习(ML)应用对大量数据的需求,确实使得在边缘进行数据训练和推理相比于云为中心的方式更加高效且合理。此外,在靠近边缘或直接在边缘对ML模型进行训练和推理,还为终端用户带来了显著优势,包括更好的数据隐私保护和更快的响应时间。
然而,将人工智能与边缘计算相结合也带来了更多挑战,尤其是由于边缘设备的资源限制和可用性。这些局限性在与稳健且无处不在的云基础设施相比时显得尤为明显。然而,像自动驾驶这样的应用场景,不仅需要低延迟的响应,还要求以极高的速率处理高维数据,这鲜明地展示了边缘智能的必要性。在此类安全关键型应用中,哪怕是几毫秒的延迟都至关重要,这使得获取数据源和模型决策的最小延迟变得至关重要。同样地,将学习和推理引入边缘将催生新的创新型和实用型应用,例如机器人技术、沉浸式多用户应用(增强现实)以及智能医疗保健,从而彻底变革我们的生活方式。
在探索人工智能(AI)与边缘计算协同发展的过程中,解决边缘计算与智能融合所带来的独特挑战至关重要。尽管边缘智能具有巨大的潜力,但其发展受到资源限制的影响,特别是在计算和存储资源方面,这与传统云基础设施的能力形成了显著对比。由于这些局限性,保护数据安全和确保快速响应时间仍然是重大挑战。在许多情况下,当前的边缘计算解决方案在这些方面仍落后于纯云计算。
边缘基础设施通常部署在物理可访问的地点,无法受益于云计算中使用的基于边界的保护措施。为了使边缘计算真正成为现有纯云解决方案的有力补充,未来的研究需要聚焦于边缘智能的安全性、可用性和效率。本文不仅回顾了过去十年来边缘人工智能的发展历程,还对不同利益相关方的观点进行了批判性分析,并概述了这一领域中的迫切挑战以及令人兴奋的未来研究方向。
边缘AI的十年历程
边缘智能作为边缘计算范式的演化而出现,其根源可以追溯到2000年代,主要是由云计算在处理本地设备生成的日益增长的数据方面的局限性所驱动。边缘计算分散了数据处理,将其推向网络边缘的数据源。这种接近性减少了数据必须传输的距离,从而减少了延迟并节省了带宽。此外,边缘计算通过本地处理敏感数据,减轻了中央服务器的数据负载并增强了隐私保护功能。边缘计算与云计算可以相辅相成,形成所谓的计算连续体。边缘计算解决即时的本地化处理需求,而云计算则在大规模数据存储和复杂计算任务中不可或缺。
边缘AI的兴起
边缘智能是边缘计算的进一步范式转变,通过整合人工智能(AI)以增强网络边缘的处理能力。这种整合不仅进一步降低了延迟,还减轻了中央服务器的带宽需求,同时带来了额外优势,例如通过联邦学习等分布式机器学习方法提升隐私保护,以及通过本地自治和去中心化控制提高系统韧性。
边缘智能广泛应用于多个领域,包括智慧城市、医疗保健、自动驾驶和工业自动化,这些领域对低延迟和本地数据处理有着关键需求。这一趋势因5G网络的日益普及以及未来6G网络所承诺的高带宽连接能力而进一步加速,这些技术为边缘智能应用提供了必要的高速连接。图1展示了人工智能从云端集中式训练和推理模式向边缘人工智能解决方案转变的过程,并以两个典型用例(自动驾驶和互联健康解决方案)说明了其中的挑战和机遇。
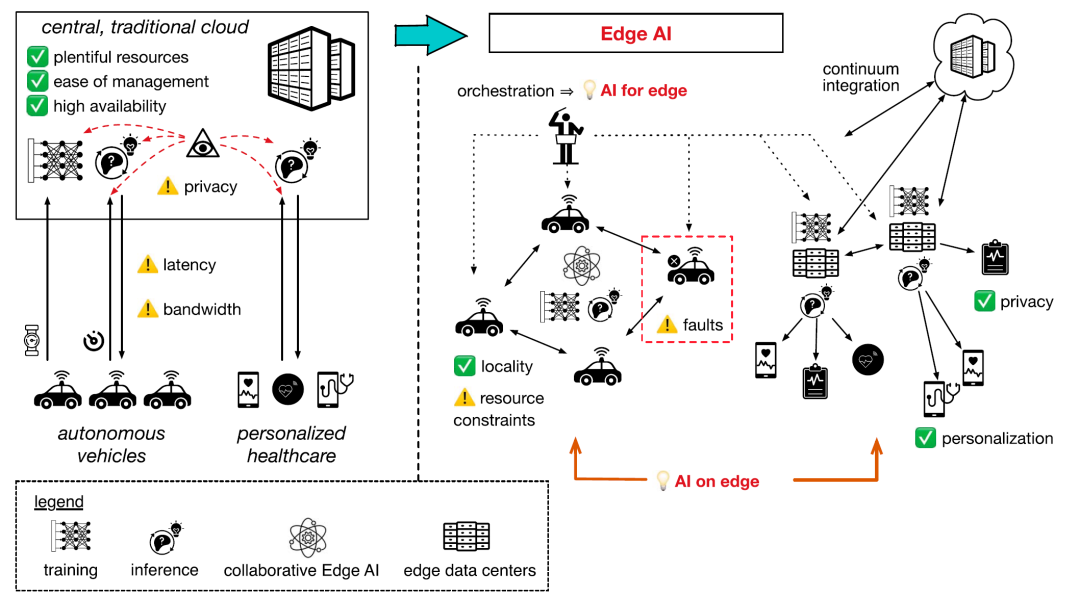
图1.展示了从云端集中式人工智能(左)向边缘人工智能(右)的转变,以及针对两个典型目标应用——自动驾驶车辆和个性化医疗保健——所面临的相关挑战和机遇。
边缘AI的现状
当前的边缘智能研究可以分为两个主要子领域:边缘上的AI(AI on edge)和为边缘服务的AI(AI for edge)。前者聚焦于适应去中心化、异构性以及机会性边缘环境的人工智能方法;后者则专注于利用这些方法为计算连续体带来益处。
边缘上的AI(AI on edge)得益于机器学习算法(尤其是深度学习)的进步,以及这些算法在资源受限设备上执行的优化。轻量级神经网络的开发以及模型剪枝和量化等技术在使复杂AI模型能够高效运行于边缘设备上方面起到了关键作用。在图1中,边缘上的AI使得模型的训练和推理能够直接在边缘进行,这可以通过边缘设备之间的直接交互以协作形式完成,也可以利用靠近这些设备的本地边缘服务器实现。
一个显著的趋势是分布式机器学习技术的兴起,用于在多个边缘设备上训练和推理AI模型,同时保护数据隐私。例如,联邦学习允许在无需集中数据的情况下进行协作模型训练,这与边缘计算的分布式特性相契合,并回应了日益增长的数据安全和隐私问题。
为了在边缘进行大规模AI模型的推理而无需通过剪枝或量化来压缩模型,可以将这些模型拆分为多个子模型,从而在多个可能是异构的边缘设备上分布式协作执行。另一种方法是探索自适应计算技术,其中推理成本取决于数据的复杂性。此外,分层推理也被提出,通过利用大规模与小规模神经网络结构之间的协作,以在基于边缘的推理场景中平衡准确性、能效和延迟。
为边缘服务的AI(AI for edge)在将人工智能与边缘计算架构相结合方面取得了显著进展,提升了边缘设备执行复杂数据处理和决策任务的能力,同时为计算连续体中资源的智能编排铺平了道路,如图1所示。
事实上,除了技术进步之外,当前边缘智能的发展趋势还受到对能源效率和可持续性的日益关注的影响。研究人员和从业者正在积极探索减少边缘AI系统能源消耗的方法,这对于边缘AI的广泛部署尤为关键,特别是在电力供应受限的环境中。必要的进展包括开发能源感知算法以及硬件优化等,以减少系统的能耗负担,推动边缘AI的可持续发展。
除了对边缘上的AI(AI on edge)和为边缘服务的AI(AI for edge)的特性描述外,我们还观察到了不同的提供模式差异。许多边缘计算的应用是多层架构的延伸,这些架构将处理任务沿着从传感器到执行器、应用领域的协调(例如生产车间)以及云服务的连续体进行转移。边缘计算通过在这一连续体上合理布局处理任务,提供了应对通信负载和延迟需求的机会。因此,我们将边缘AI视为工业应用中的一种重要现象。
谁应该关心?
随着智能城市和工业自动化等越来越复杂和数据驱动的应用的出现,过去十年中边缘计算和边缘人工智能的重要性显著提高。然而,不同的利益相关者对这些范式及其相关技术有着不同的观点。在下文中,我们介绍了四个利益相关者的视角:社会和工业的需求由开发者转化为解决方案,而这些解决方案受到政府设定的政策和法规的约束。理解这些利益相关者的个体视角,对于塑造未来的研究方向并促进边缘AI的稳健发展至关重要。
图2 提供了社会、政府、工业和开发者对边缘AI不同挑战的关注点概览。该图表被视作为一种整体趋势的解读。
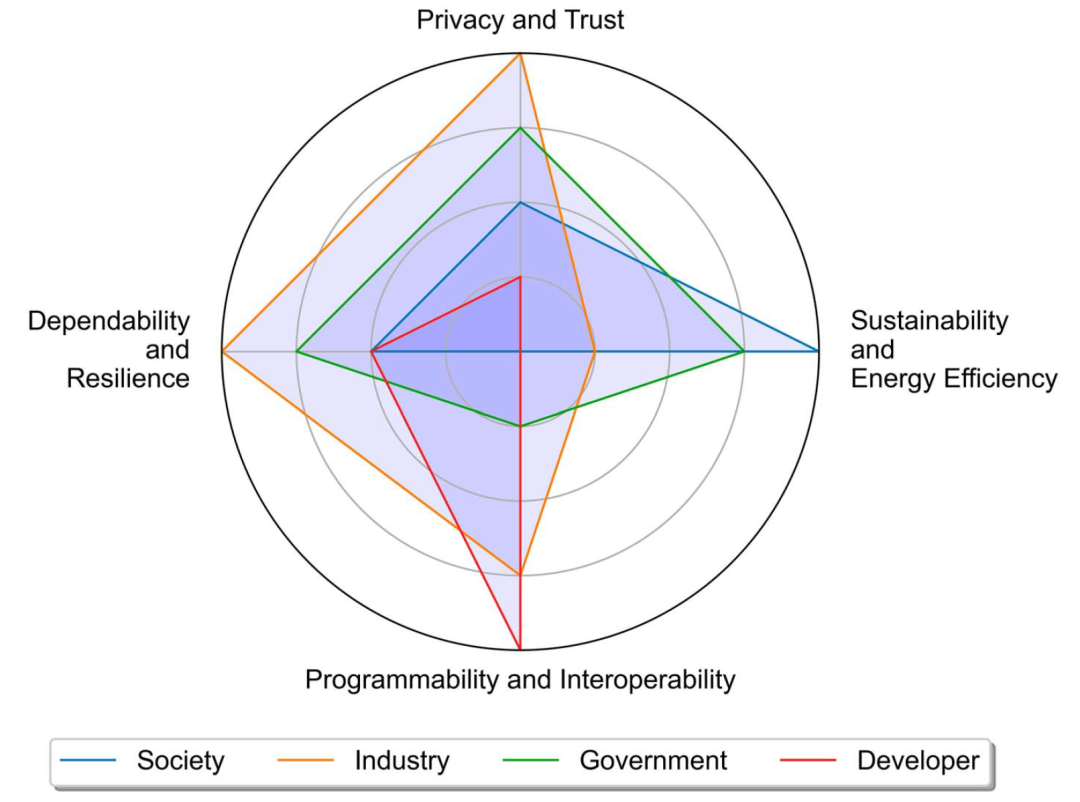
图2. 社会、政府、工业和开发者视角的需求。符号的深浅程度表示每个需求对相应利益相关方视角的重要性(颜色越深表示需求越高)。
社会视角(人们的日常生活)
从社会角度来看,人们对边缘 AI 的兴趣主要集中在其实际应用上,而非底层技术创新。边缘人工智能在自动驾驶车辆和智能家居等领域的应用更容易引起关注。尽管普通用户,特别是没有技术背景的用户,可能无法察觉基于云和基于边缘执行之间的延迟差异,但应用的可访问性及其对日常生活的影响将更加显著,因为这将实现更丰富的交互和更复杂的应用。尤其在欧洲,隐私是一个非常重要的方面,这与边缘计算和边缘AI密切相关。
工业视角
从工业的角度来看,可以将边缘 AI 的相关方分为两类:边缘AI的消费者和边缘AI的提供者。
边缘AI的消费者
对于边缘AI的消费者而言,可靠性和保障性是决定未来是否使用边缘智能的关键因素。由于云和边缘服务提供商众多,信任多个系统和服务的可靠运行变得困难。此外,系统故障的责任归属问题变得更加复杂,难以明确将故障归因于具体的组件或服务提供商,从而限制了追责的可能性。
尽管可以通过使用诸如AWS Wavelength这样的云边结合提供商来缓解这一挑战,但使用单一提供商可能会显著影响边缘计算的一些优势,尤其是在系统稳健性和数据保护方面。与社会视角类似,数据保护对于工业视角也至关重要。这包括保护边缘处理过程中的数据、确保边缘网络提供商的可信性,以及保护知识产权(即开发的边缘应用和训练的AI模型)。
边缘AI的提供者
对于边缘AI的提供者来说,商业案例的可行性是决定边缘AI成功的关键因素。过去,电信行业已经从语音服务提供商转型为数据服务提供商,如今,他们可能再次转型成为计算服务提供商。特别是在移动网络领域,电信运营商是支持将计算能力靠近用户并为其提供低延迟AI服务的自然候选者。然而,如果需要非通用模型,这将导致用户模型向边缘的迁移和部署。至今,这是否是一个可行的商业案例仍不明确。
潜在应用的数量(例如辅助驾驶、老年人支持、实时翻译服务等)非常可观,但需要一个合理的商业模式来证明对电信基础设施进行此类扩展的必要性。此外,众多云和边缘提供商及其相互连接性使得确保消费者期望的系统可靠性变得困难。同样,满足消费者对数据保护和可信性的需求也是一个挑战。
边缘AI解决方案的提供者还可以利用边缘AI来改进其服务,但这可能再次面临解决方案可靠性的问题。其中一个重要方面是考虑消费者应用在边缘上的运行,确保用于改进操作的功能不会干扰这些应用的正常运行。
政府视角
政府对边缘AI的看法是多方面的,涵盖了诸如执行道德和负责任的使用、保护公民隐私(呼应社会关切)、保护公司知识产权、建立必要的基础设施、通过共同标准促进互操作性以及通过合法拦截监控数据交换等方面。不同政府的优先事项排序各不相同。值得注意的是,欧洲国家已经是隐私法规(如通用数据保护条例GDPR)和安全法规(如《欧盟网络韧性法案》)方面走在前列,这些国家可能会更加重视边缘AI的伦理使用以及隐私和安全的保护。最后,政府部门可以通过资金支持和政策法规推动边缘智能的发展,从而在各自的国家内实现新的服务和应用。
开发者视角
从开发者的角度来看,编程的便捷性对于采用边缘人工智能(Edge AI)至关重要,尤其是在创建分布式应用时。理想情况下,开发者在解决边缘AI的常见问题(如用户和数据的移动性、分布式协调以及同步)时应付出最小的努力。因此,为了让开发者更容易使用边缘AI,有必要提供一个编程框架,以简化边缘AI应用的开发和配置。这包括管理计算和存储资源、自动化部署模型的水印处理、处理传感器数据的分发,以及为量子计算和神经形态计算等新范式提供编程抽象。
总结与研究视角
研究视角结合了上述所有视角,形成了一个整体性观点,旨在通过未来研究解决当今边缘人工智能(Edge AI)面临的部分问题。诸如Rausch等人和Nastic等人的多项研究已提出了针对边缘AI的编程模型,使得训练和推理可以以去中心化的方式进行,其中一个例子是联邦学习范式。
虽然数据的本地化和相应的去中心化可以被视为对数据隐私的积极影响,但对边缘设备的信任有时可能会受到限制。因此,围绕数据隐私保护的额外挑战仍需解决,目前已经有多种想法在被研究中。这些研究包括同态加密的应用、在硬件安全执行环境中对任务相关数据进行设备端过滤,以及确保对边缘AI解决方案信任的相关研究。在这些主题上的研究成果可以为政府在边缘处理系统的监管提供宝贵的参考意见。
当前研究的挑战与机遇
边缘人工智能(Edge AI)为在本地设备中嵌入智能提供了一种变革性的方法。然而,它也面临着资源限制、安全与隐私、可持续性以及能源危机等方面的挑战。同时,边缘AI在实时数据处理、效率提升以及个性化体验等方面带来了显著的机遇。
构成人工智能的算法正逐步应用于越来越多优秀的用户服务中。多项已发表的研究分析了这种应用的实现方式及其技术潜力。这引发了一系列关于理解边缘AI挑战和机遇的问题,以下将重点探讨当前最突出的几个方面。
资源限制
边缘设备的特点在于其计算和存储资源有限。相比云端应用可以利用包括CPU、GPU,甚至现场可编程门阵列(FPGA)在内的多种计算设备,边缘设备通常仅配备少量硬件加速器,并且这些加速器往往针对特定的应用或使用场景设计。此外,边缘设备的计算能力、内存和存储都受到严格限制,这进一步制约了在边缘设备上进行模型训练和推理的可能性。
这一问题在边缘AI解决方案的应用中尤为显著,因为机器学习模型通常依赖专用硬件,并需要大量内存和存储支持。此外,数据交换通常是关键环节,但也受限于可用的网络带宽。因此,需要开发机制来限制交换信息的数量,不仅是与中央基础设施之间的交换,还包括边缘设备之间的数据交换,例如通过信息驱动的优先级排序来优化交换效率。
由于边缘设备的推理位置并非总是预先确定的,从强大的集中式设备到资源受限的边缘设备都有可能,因此需要多个机器学习模型来适应不同场景的需求。每种部署环境都有其独特的限制和要求,无论是边缘设备上的实时处理,还是在强大计算平台上的全面分析。为此,开发者通常需要根据不同的部署场景调整和优化模型,以确保整个应用场景中的效率和有效性。需要自动化机制来支持这种适配,使得边缘AI解决方案能够无缝集成到各种场景中,满足每个部署环境的特定需求和限制,同时尽可能保持最佳性能。
隐私与信任
确保可靠性、安全性、隐私性以及伦理完整性是建立边缘AI应用和连接系统可信度的关键。这一点尤为重要,因为边缘设备处理敏感数据,若发生数据泄露,后果可能十分严重。
建立信任的关键在于安全的处理与存储机制,结合强大的加密技术和严格的访问控制。尽管边缘设备资源有限,但AI模型必须保持可靠性和准确性,同时具备抵御对抗性攻击的能力。有时,使用硬件支持的可信执行环境被认为是一种解决方案,但这种方法在性能和集成方面也面临一系列挑战。此外,AI决策的透明性和可解释性在关键应用中变得日益重要。遵守如GDPR(通用数据保护条例)之类的法规,确保数据隐私和安全,也是边缘AI需要解决的关键问题。
可持续性与能源效率
日益增长的AI应用需求凸显了创建高能效和可持续的边缘AI算法的重要性。高级AI,特别是深度学习,消耗了大量能源,这对可持续发展提出了挑战。在边缘AI中,平衡性能与能源效率至关重要。尽管实现更高的准确性可能看起来是最终目标,但必须认识到,每一次对准确性的微小提升通常都需要显著增加能源消耗。这种权衡在某些超高准确性并非关键的场景中尤为明显。在这些情况下,为了获取微不足道的准确性提升而分配过多的能源资源可能既低效又对环境不可持续。因此,开发者和研究人员必须谨慎评估提升准确性所需的必要性及其带来的能源消耗。
另一个重要方面是可再生能源对能源网的重要性不断提升。由于大多数可再生能源依赖于环境条件(例如太阳能电池需要阳光),因此在某些时候,例如在一个阳光充足且风力强劲的炎热夏日,电力会变得充裕。在这种情况下,尽管节约能源仍是边缘AI面临的一个重要挑战,但另一个关键挑战是利用能量过剩时段执行一些非时间关键的计算(如模型训练)。在能源过剩时进行这些计算有助于平衡能量生产高峰,并弥补大多数可再生能源波动性带来的问题。此外,地理分布式的能源需求可以缓解某些地区(如美国北弗吉尼亚和荷兰阿姆斯特丹)大型数据中心集中的供给问题。由于当前的能源储存能力有限且效率低下,这种方式可以大大提高电网和边缘设备的效率。
在关注运行期间的能源消耗的同时,部署边缘设备的生产和生命周期也同样是一个重要挑战。设计更耐用、可升级和可回收的设备对改善边缘AI解决方案的环境足迹至关重要。此外,实施鼓励节能AI的政策以及对设备制造和处置的环境影响进行监管也是不可或缺的。
可编程性与互操作性
边缘AI涉及多种设备,如智能手机、物联网设备和工业机械,每种设备都有独特的限制。由于需要在各种硬件上高效协调服务,为边缘AI创建可编程框架是一项挑战。开发人员需要面对设备能力的复杂性,如CPU性能、GPU可用性、内存和能耗等方面的差异。这种复杂性使得在大规模场景(如智慧城市)中部署服务成为一项重大且持续的挑战。缺乏标准化工具进一步增加了开发难度,开发者往往需要使用不兼容的工具和平台,从而导致开发时间延长和集成问题。
边缘AI的可编程性挑战因互操作性的需求而进一步加剧,即需要在多种设备和系统(如传感器、智能手机和工业机械)上组合操作。这些设备尽管在操作系统、软件和硬件上存在差异,也需要无缝协作。一个关键问题是缺乏标准化的协议和数据格式,因此开发通用标准以实现高效通信变得至关重要。将边缘AI与现有系统集成时,往往会遇到不受支持的软件和硬件组件带来的问题。随着互联设备数量的增长,设备的可扩展性以及新设备的轻松集成变得既重要又困难。在实时处理场景(如环境监测、自动驾驶和工业4.0)中,减少互操作性造成的延迟至关重要。然而,在这种互联环境中高效管理资源,同时考虑整个系统中的可用资源,也是需要解决的关键挑战。
总之,统一的可编程框架对于高效部署边缘AI算法至关重要,能够确保服务协调、资源管理以及设备间的互操作性在整个系统中的有效运行。
可靠性与弹性
可靠性关注运行在边缘计算设备上的AI系统在进行AI决策时的可靠性、安全性和稳健性。这包括确保这些系统即使在充满挑战或不可预测的环境中,也能始终如一地表现出色且准确。这些系统在医疗保健和工业自动化等关键的网络领域中尤为重要,必须具备强大的设计和有效的故障切换策略以确保始终正常运行。开发的系统必须能够保护数据和AI模型的完整性,抵御各种威胁,具备处理更多数据的能力,并能够容纳更多设备或覆盖更广的地理区域。这些系统需要具备自主检测和解决故障的能力,并能适应不断变化的条件和新兴的威胁,从而实现可靠的运行。
除了可靠性,边缘AI的弹性对其始终可操作性也至关重要。弹性指的是在各种条件下,系统对安全攻击和中断保持可靠运行的能力。边缘设备需要对诸如极端温度和机械冲击等物理挑战保持稳健,同时维护数据的完整性和安全性。即使在网络条件较差的情况下,边缘系统也应能够通过替代通信技术或稳健的协议提供可靠的连接,或者在离线状态下继续运行,直到连接恢复。此外,这些系统需要具备容错能力,并可能需要备份解决方案。AI模型应能够适应不断变化的数据模式,而无需进行大规模的重新训练。随着边缘AI网络的扩展,可扩展性和可管理性变得尤为重要,同时还需高效的资源管理以应对整个系统中变化的工作负载。
可测量性
由于云-边缘连续体的独特特性(如分布式的训练和推理、共享资源)和不同边缘AI应用及连接系统的约束条件(如资源限制、实时性需求),定义通用的性能评估指标是一项挑战。特别是对于前文提到的那些当前难以测量和量化的挑战而言,定义准确的衡量指标对于相关领域的研究至关重要。
此外,边缘AI的一个重要挑战是如何在准确性、延迟、资源使用和隐私之间平衡这些权衡。这种平衡在整个连续体中尤为复杂。尽管仿真或模拟可以预测某些场景下方法的性能,但验证这些方法在真实环境中的有效性同样重要。在真实场景中开发基准评估框架并结合实际使用案例,仍然是一项未解决的挑战。这些基准必须依赖于通用的指标,以精确衡量和评估边缘AI的独特特性。
未来研究方向
在本节中,我们确定了一些最具前景的研究方向:将大型语言模型(LLMs)集成到边缘AI应用中、自主车辆的低延迟推理、聚焦于社会中的能源和隐私问题、增强边缘互操作性,以及推动边缘AI系统的信任与安全的进步。接下来,我们将详细阐述每个研究方向。
将大型语言模型集成到边缘AI中
将大型语言模型(LLMs)集成到边缘设备上的应用中代表了未来研究的一个激动人心的方向。传统上,LLMs因推理计算需求过高而主要局限于基于云的推理。然而,在边缘设备上运行LLMs则引入了一种全新的范式。如今,越来越多的边缘设备配备了节能的加速器。例如,苹果神经引擎(ANE)已被集成到iPhone中,谷歌的边缘张量处理单元(TPU)也作为嵌入设备的子模块提供支持。在这些边缘加速器上运行LLMs,为这些公司提供了推理“零成本”的优势,因为“成本”(主要指能耗)现在发生在终端用户的设备上。这种方法可能有利于对延迟要求较低的应用程序,例如社交媒体平台,在这些场景下即时响应并非关键需求。
然而,挑战在于如何将这些计算密集型模型调整到边缘设备的限制条件下,包括有限的处理能力和能耗效率。传统的学习技术,例如蒸馏、神经架构搜索,以及系统技术如量化和稀疏化,都是潜在的解决方案,但它们的有效性尚未被完全验证。评估LLMs的难度进一步增加了复杂性。因此,未来研究不仅应该专注于优化LLMs以适应边缘环境,还可以推动定制化硬件的创新,开发满足边缘设备功耗要求的解决方案。边缘计算在自主代理中的应用
自主代理对我们的社会正变得越来越重要,包括智能工厂中的自主机器人和自动驾驶车辆等。尽管首批自动驾驶汽车和自主机器人已被部署,这些代理目前仅能在持续的网络连接、特定区域或特定条件下运行。然而,即使在今天,大量的传感器(包括外部和车载传感器)已经生成了海量数据,这些数据可能会压垮传统的互联网基础设施。如果这些数据能够以低延迟共享,可以改善其他代理的行为,从而实现更高水平的自动化。
边缘计算可以对数据进行本地处理,减少需要通过网络传输的大量数据。这不仅提高了响应速度和操作效率,还支持在“网络盲点”进行实时决策,这对于代理的可靠运行至关重要。这不仅仅是一个“可有可无”的功能,而是必不可少的。多传感器输入、不同时间和环境下的感知、各种天气条件以及社会元素等因素不仅支持以边缘为中心的解决方案,还为边缘设备上的训练和推理方面的研究开辟了新的途径
聚焦社会中的能源效率与隐私
社会对能源消耗和隐私问题日益关注,这为边缘AI提供了独特的机遇。在边缘设备上进行本地处理可以通过将敏感信息留在设备内来确保数据隐私,从而实现隐私保护。此外,在边缘使用的线性功耗系统(如深度嵌入式部署中),通信成本(如Wi-Fi、蓝牙等)往往高于计算成本。因此,迫切需要开展研究以开发能够平衡通信开销与计算效率的节能边缘AI解决方案。这需要探索能量感知算法、可持续硬件设计,以及优化网络协议以实现能源节约。
低功耗广域网络(LPWAN)是一种有前景的方向,其通过降低吞吐量来换取功耗的减少。尽管这是一种在广泛的帕累托曲线中的设计选择,但如何开发既能降低生产成本的通用性解决方案,同时又能针对特定应用需求进行定制化,仍然是一个尚未解决的研究问题。
增强边缘AI的互操作性
随着边缘AI系统的普及,确保其可扩展性和互操作性成为一个新的且尚未充分探索的领域。一个悬而未决的问题是,不同的AI支持的边缘设备应如何进行互相通信。除了长期存在的去中心化与中心化、星型结构与环形结构的争论之外,一个令人振奋的研究方向是开发标准化协议和框架,以实现多样化边缘设备和系统的无缝集成。这包括创建通用数据格式和通信标准,以促进不同类型边缘设备(如传感器、可穿戴设备、智能手机、工业设备、自动驾驶车辆等)之间的高效交互,更重要的是实现设备间的自动发现。
边缘AI的演进还带来了与新兴的非冯·诺依曼架构(如量子计算和类脑计算)实现互操作性的需求。开发能够与传统计算系统有效通信和协作的协议和标准至关重要。这不仅涉及数据格式和通信协议的转换,还需要理解和协调不同非冯·诺依曼架构在处理和解释数据方式上的根本差异。例如,类脑计算系统通过模拟人脑神经结构实现极端并行性和能效,但其基于事件驱动且处理模拟数据(脉冲)。弥合这一差距对于创建真正互联的边缘AI生态系统至关重要,在该生态系统中,设备能够利用当前和未来计算范式的独特优势。推进边缘AI系统的信任与安全确保边缘AI系统的可信性和安全性至关重要,尤其是在它们逐渐成为关键基础设施和个人设备的重要组成部分时。未来的研究应重点开发强大的安全协议和加密方法,以保护边缘设备上处理的敏感数据。这包括增强边缘AI系统抵御网络威胁的弹性,并确保AI决策过程透明、可解释且符合GDPR等法规标准。然而,这带来了挑战,因为边缘设备有时缺乏可信环境,而可信环境对于保护隐私敏感数据至关重要。解决这些问题不仅可以提高边缘AI系统的安全性和可靠性,还能增强公众对其部署和使用的信任感。
结论
在本文中,我们回顾了边缘AI解决方案的历史和现状,从其作为边缘计算与AI相结合的起源,到其当前在资源受限的边缘设备上实现去中心化推理与训练的发展状态。我们重点探讨了当今边缘AI所面临的各种挑战和研究机遇,包括相关利益相关者在边缘AI领域的观点。最后,我们展望了该领域研究者未来的研究方向。
-
人工智能
+关注
关注
1791文章
47336浏览量
238696 -
机器学习
+关注
关注
66文章
8421浏览量
132702 -
边缘计算
+关注
关注
22文章
3094浏览量
49037
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论