 算力调度的基础知识
算力调度的基础知识
编者按
“算力调度”的概念,这几年越来越多的被提及。刚听到这个概念的时候,我脑海里一直拐不过弯。作为底层芯片出身的我,一直认为:算力是硬件的服务器和集群,他在某个地方,就是固定的;根本就不存在算力的调度,调度的应该是上层的业务软件。
经过跟行业众多朋友的交流和思考后,我逐渐能够理解“算力调度”所表达的意思。从业务的视角,客户关心的是业务本身,需要算力随时随地可用,而不需要关注承载业务的具体的硬件在哪里。当然,要实现不需要关注硬件,有许多工作要做,这就是“算力调度”要完成的事情,也就是说:“算力调度,不仅仅是调度”。
本篇文章,我们简单聊一聊算力调度,仅供探讨,欢迎私信交流。
1 计算任务的特征
1.1 计算任务的时间和空间特征
计算任务(Workload,也译作工作任务、工作负载等),是一个或一组相关的、运行中的应用程序。
站在软件运行的角度,根据运行时间的长短,我们可以把计算任务简单的分为两类,短期型任务和常驻型任务:
短期型任务指的是,任务开始执行,会在一定的时间内运行完成,结束后会释放计算资源。
常驻型任务指的是,没有外部强制关闭的话,任务会一直处于执行状态,不会结束。
从微观的看,某个特定的处理器,在其上运行的程序(线程)是分时调度的。这样,线程的资源占用不会大于1个CPU核。
但相对宏观的某个计算任务(一个进程或一组相关的进程),其占用的处理器资源既可以少于1个CPU核,也可以是多个CPU核,甚至多个CPU芯片、多台服务器的集群,直到成千上万台服务器的大集群。最典型的例子就是AI大模型训练,需要上千台服务器上万张GPU卡的计算集群来运行大模型训练的计算任务,并且一次计算任务运行会持续数十天。
串行和并行,会影响计算任务的时间和空间。串行,是以时间换空间;反过来,并行则是以空间换时间。
当计算资源有限而计算任务尺寸较大时,可以把计算任务拆分成许多小计算任务,然后这些小计算任务串行运行。虽然计算的时间会增大,但可以在较小规模的计算资源上完成计算。
反过来,当计算任务的运行时间非常长,我们也可以把任务拆分成短任务,这些短任务并行运行在不同的计算资源上,从而减少计算的时间。这也就是我们经常说的并行加速。
1.2 计算的两种形态

根据软件任务的尺寸和硬件服务器尺寸的匹配程度,可以简单的把计算分为两种类型:
第一种,一台硬件服务器处理很多件计算任务。
像云计算,通过虚拟化或容器的方式,可以把单台服务器分割成多份,每一个虚机或容器,就运行“一个计算任务”,一台服务器可以同时支持多个计算任务运行。
目前,AI推理的计算任务,通常也可以在一台服务器尺寸范围内完成。也因此,AI推理计算任务通常是基于云虚机或容器的方式来运行。
第二种,很多台硬件服务器处理一件计算任务。
如超级计算(HPC),超算的计算节点可以看做是一台计算机,然后超算实际上是这些计算节点组成的计算集群。超算的计算任务都比较大,通过并行占用所有计算资源的方式,达到快速计算的目的。
AI模型的训练的计算任务,尺寸非常大,所以把模型进行拆分,拆分成若干小的计算任务,并且这些小的计算任务之间的联系更加紧密,是一种紧耦合的关系。也因此,AI模型的训练,通常是千卡万卡,甚至更多GPU卡的高性能集群计算,各个需要计算节点之间需要高速(网络)互联通信。AI训练的计算架构,更接近HPC。
1.3 分布式解构
随着系统越来越大,单机计算已经非常的少见,集群计算已经成为主流。云计算模式,虽然某个具体的计算任务是放在一台计算服务器上去运行,而实际的情况很可能是——这个计算任务是某个巨服务解构拆分出的其中一个微服务。每个微服务聚焦做一个相对简单的事情,从而使得单个微服务可以在单机上以虚机或容器的方式运行。
那这样的话,计算岂不可以统一到一种形态?即单个计算任务需要多台计算服务器来承载其运行。这里的关键,是在于大计算任务解构拆分的不同小计算任务之间的交互耦合度。这样,根据交互耦合度和网络硬件实现,我们分为如下几个情况(耦合性依次降低):
IB高性能网络+内存一致性硬件加速。计算任务之间完全紧耦合,通常采用超级计算(HPC)模式。超算的各个节点之间主流是通过IB网络连接,但会在其上构建高效的内存一致性协议加速处理,从而使得整个超算连成一台计算机。
IB高性能网络。计算任务之间,联系紧密,数据量大,延迟敏感。计算机集群,通过IB网络连接。本质上仍然是多台计算机组成的计算集群,计算任务间靠点对点通信交互数据。典型案例如AI大模型训练。
RoCEv2高性能网络。计算任务之间延迟敏感,但联系紧密程度再低一些,通常可以选用RoCEv2的方式。RoCEv2在高性能、兼容性和低成本方面达成一个均衡。典型案例如EBS高性能块存储和分布式文件存储。
标准Ethernet网络。计算任务之间完全解耦,则通常采用标准以太网的方式。传统的云计算下,微服务解构的互联网业务通常采取此网络方式。
2 理想化的算力调度
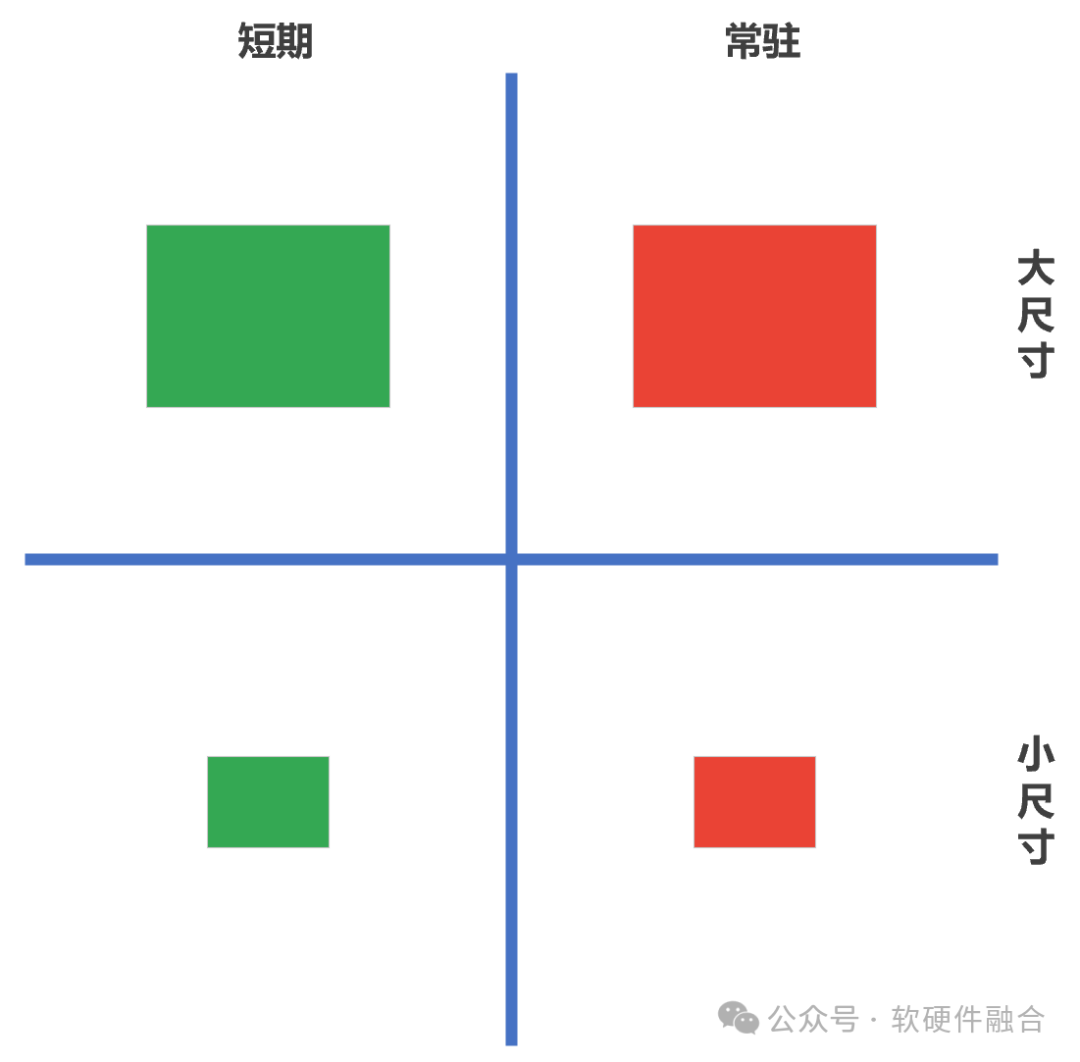
依据计算任务的时间和空间特性,相对应的算力调度方式也就分为四类:
短期的小尺寸计算任务。这是通常大家理解的算力调度,也是算力调度最简单的情况。
短期的大尺寸计算任务。超算或AI大模型训练的计算模式。
常驻的小尺寸计算任务。云计算常见的业务组织方式,是常驻的小尺寸计算任务。
长期的大尺寸计算任务。实际的互联网型业务系统。
这里,我们从计算的角度,谈一下计算方式的统一:
一个是,计算任务的解构(计算任务的弹性)。大尺寸的计算任务,可以拆分成若干个小尺寸的计算任务。从而使得计算任务能够匹配单个裸机的计算主机(裸机、虚拟机、容器等);
另一个,计算资源的池化(虚拟化)和再组合(计算主机的弹性)。计算主机可以从1/N个处理器核、扩展到多个处理器核,甚至扩展到M个计算节点。因为计算主机的弹性,从而使得计算主机既可以适配小尺寸的计算任务,也可以适配大尺寸的计算任务。
两者相向而行,并且均具有一定的(尺寸)弹性,从而能够尽可能的适配对方。
3 实际算力调度中的问题
3.1 问题一:静态调度和动态调度
静态调度:计算任务在初始运行时,分配计算资源时候的调度。一般来说,短期型的计算任务,通常只有静态调度,也即仅调度一次,运行结束后就立刻释放计算资源。
动态调度:计算任务在运行的过程中,受计算资源的各类情况变化的影响,计算任务需要(重新)调度到其他计算资源,也即我们通常理解的业务迁移。常驻型的计算任务通常会遇到这样的情况。
这里举一个动态调度的案例——跨云边端的高阶自动驾驶汽车:
初始的时候,车辆由驾驶员驾驶。此刻,其他乘车人员,可以在车上玩游戏、看电影、听音乐、刷短视频等等。这些计算任务都运行在车辆终端本地。
当开启自动驾驶时,本地算力不够。游戏、电影、音乐、短视频等计算任务,由于优先级较低,统一调度到边缘侧甚至云侧。而自动驾驶的计算任务,由于尺寸较大,通常也是由解构的若干微服务组成。其中优先级较高的少量微服务,运行在车辆终端本地;而优先级较低的大部分微服务,也和游戏等其他计算任务一样,运行在边缘侧甚至云侧。
解除自动驾驶后,自动驾驶相关微服务(计算任务)退出,并且释放本地和边缘、云端的算力资源。而游戏等其他计算任务再从边缘、云端,重新调度(迁移)到车辆终端本地。
3.2 问题二:任务的状态
无状态计算任务
如果是无状态的计算任务,的确可以随便调度。
但一个计算任务至少有两个状态,一个是计算任务的输入,一个是计算任务的输出。因此,任务调度会受输入源和输出目的的约束——不管调度到哪里,都需要能访问源数据和写入结果数据。
有状态计算任务
如果是有状态的计算任务,那么在运行的过程中,一方面是尽可能提高运行平台的高可用性,尽量减少调度;另一方面则当不得不调度的时候,运行现场需要和计算任务一起调度。
3.3 任务间的关联性
大任务拆分成小任务(巨服务微服务化),这些小任务间必然需要相互访问。那么在调度的时候,就需要考虑这一层约束:凡是有关联的计算任务,只能在一个集群(可网络访问)内调度。如果是跨集群,或者跨数据中心和云边端的计算任务,则需要考虑网络打通、访问延迟、访问权限等方面的问题。事情远不是理想化的算力调度那么简单!
因此,算力调度,此刻应该有两层:
第一层,是全局算力调度。为这个大任务,或者用户的若干大任务分配一个独立的计算集群,可以是跨数据中心、跨云边端的算力资源所组成的“虚拟”的集群。
另一层,则是用户在自己的集群内部,进行业务层次的算力再调度。
3.4 任务的计算平台要求
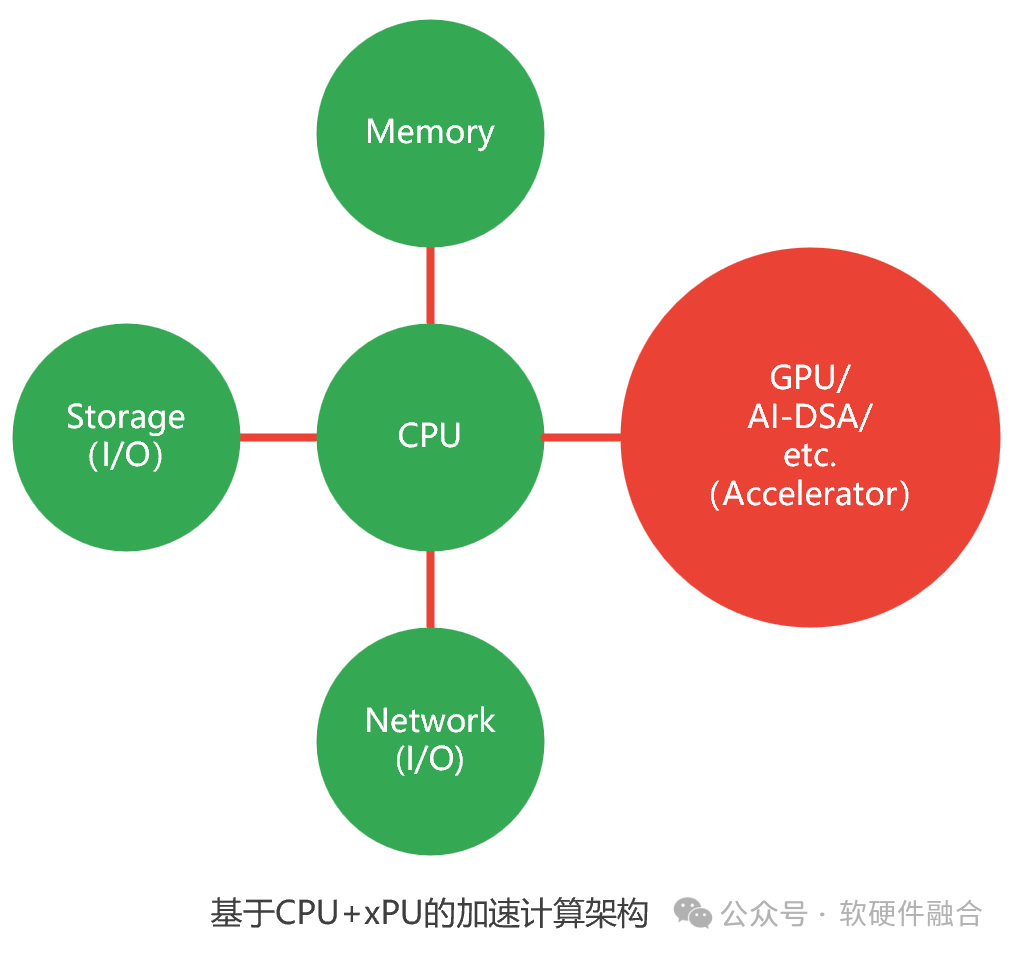
计算平台由如下部分组成:
CPU处理器。CPU是图灵完备的,可以自运行。
内存。计算数据暂存和数据共享的区域。
存储I/O。本地的存储通过片间总线,如PCIe;远程的存储需要通过网络。
网络I/O。网络主要用于外部通信。在集群计算和计算存储分离的场景下,网络的功能主主要是三个:
访问内网,东西向网络,作为集群内部不同节点间的网络通信,目前主要是IB;
访问远程存储,目前主要使用RoCEv2;
访问外网,南北向网络,作为集群外部的访问端口,目前主要是Ethernet。
一个或多个加速处理器:
从整个架构看,加速处理器是和CPU功能类似的计算部件。
其他加速处理器是非图灵完备的,均需要组成CPU+xPU的异构计算架构。从CPU软件视角看,加速处理器是跟网络和存储I/O类似的部件。
加速处理器,目前常用可以分为两类:GPU,通用的并行计算加速平台。DSA。领域专用加速器,DSA是完全专用(ASIC)向通用可编程性的微调。
因此,计算任务,在不同计算平台调度的时候,需要考虑平台的差异性:
CPU架构的差异性。CPU是x86、ARM还是其他架构;
网络和存储接口是否一致;
加速处理器的类型和架构是否一致。
目前,算力多样性已经成为困扰算力调度最大的问题。如何在多元异构算力平台上,实现统一调度,是目前算力中心发展要解决的重要问题之一。
4 宏观视角:多租户多系统的算力调度
计算的形态,从单机计算,走到了集群计算;并且,还在逐渐走进跨集群、跨数据中心、跨云边端的协同计算,甚至融合计算。宏观的看,一个计算系统,必然是数以万计的租户所拥有的数以百万计的大计算任务(业务系统)共存。这里的每个大计算任务,又会拆分成数十个甚至上百个小计算任务(微服务)。也因此,宏观的计算是:数以万计租户的数以亿计的计算任务,并行不悖的交叉混合运行在数十个甚至上百个云算力中心、数以千计的边缘数据中心,以及数以百万计的终端计算节点上。 从算力的视角,全局存在一个统一的调度系统,所有的计算任务都是统一的调度的。调度系统能完全考虑并满足所有计算任务的各种特性要求。 从业务的视角,调度通常是两层:
业务从全局调度系统获取自己的资源(第一层调度),组成自己的“虚拟”集群;
然后,业务的计算任务,在这“虚拟”集群里再进行调度。
全局调度为计算实例分配好资源之后,仍然可以动态调度(迁移),以保证计算实例的高可用。
业务从全局调度系统获取资源也是动态的,可增加,可减少。
5 算力调度的分层
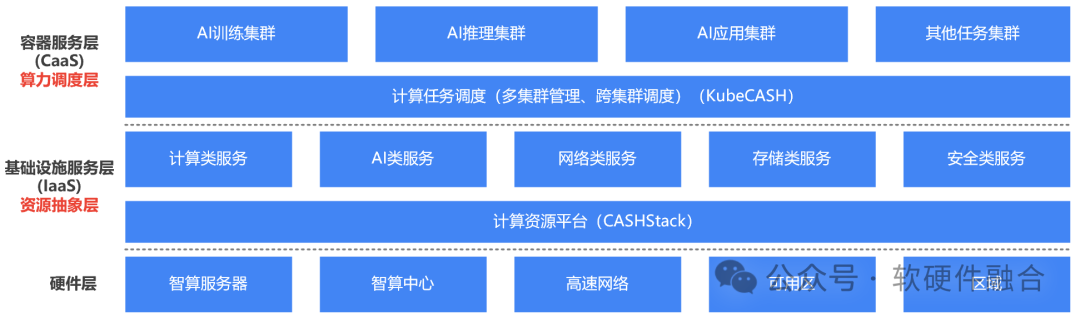
以容器和K8S容器管理为中心的云原生体系,越来越成熟,行业里出现了一个声音:“是不是传统IaaS虚拟化层就没有存在的必要了?” 我们的观点是:企业云场景,虚拟化的确没有必要(企业云规模小,没有必要那么复杂);但超大规模多租户的算力中心场景,IaaS层仍然非常有必要,也仍然非常有价值。 这样,在硬件之上,业务之下,存在两层抽象层:
第一层,资源抽象层。通过计算机虚拟化,对资源进行抽象和封装,以及资源的池化和弹性切分。目前,业界一些先进的解决方案,可以通过DPU的加持,实现虚拟化的零损耗,以及裸机和虚拟机的统一,既有裸机的性能又有虚机的高可用和弹性。因此,裸机和虚拟主机的相关劣势已经“不复存在”。此外,通过虚拟化,可以实现接口的抽象统一,从而减少多元异构算力带来架构/接口兼容性的问题。
第二层,算力调度层。容器化及云原生的核心优势,是以应用为中心:一次打包,到处运行。因此,通常是以容器为载体,以容器为基础调度粒度,从而实现算力的高效调度。
-
计算
+关注
关注
2文章
451浏览量
38861 -
调度
+关注
关注
0文章
53浏览量
10790 -
算力
+关注
关注
1文章
1012浏览量
14943
原文标题:聊一聊算力调度
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

算智算中心的算力如何衡量?

超算智算融合 南京信易达发布全新“智能算力融合平台”

算力基础篇:从零开始了解算力

大模型时代的算力需求
中科曙光入选2024算力服务产业图谱及算力服务产品名录
神州鲲泰亮相北京数字安全大会,以智能算力构筑数据安全的坚实底座

算力系列基础篇——算力101:从零开始了解算力






 工商网监
工商网监
评论