 利用VLM和MLLMs实现SLAM语义增强
利用VLM和MLLMs实现SLAM语义增强

语义同步定位与建图(SLAM)系统在对邻近的语义相似物体进行建图时面临困境,特别是在复杂的室内环境中。本文提出了一种面向对象SLAM的语义增强(SEO-SLAM)的新型SLAM系统,借助视觉语言模型(VLM)和多模态大语言模型(MLLMs)来强化此类环境中的对象级语义映射。
• 文章:
Learning from Feedback: Semantic Enhancement for Object SLAM Using Foundation Models
• 作者:
Jungseok Hong, Ran Choi, John J. Leonard
• 论文链接:
https://arxiv.org/abs/2411.06752
• 编译:
INDEMIND
• 数据集:
jungseokhong.com/SEO-SLAM
01 本文核心内容
SLAM已从专注于几何精度演变为融合语义信息,增强了其在诸如导航、操作和规划等下游任务中的效用。这一演进与计算机视觉和深度学习的进步相契合,引入了更丰富且更精确的环境表征。近期在基础模型方面的发展,例如大语言模型(LLM)、视觉语言模型(VLM)、以及多模态大语言模型(MLLM),已表明它们能够在开放式词汇设定下从数据中提取语义信息。若干研究显示,基础模型能够对给定的包含语义特征的场景或地图进行空间推理。除了建图,还有研究提出了运用基础模型的语义SLAM。

尽管取得了这些进展,语义SLAM仍存在关键挑战:(1)当探测器仅提供通用标签(例如,所有鞋子均用“鞋”表示)时,难以区分紧邻的相似物体。这导致相似物体融合为一个单一地标,如图1a所示。(2)错误地标在长时间维持地图一致性方面构成重大挑战。此问题可能由传感器测量的不确定性或场景变化引起,尤其在杂乱和动态的环境中。(3)对象探测器易受其训练数据集中固有偏差的影响,导致某些对象存在持续的语义错误。
为应对这些挑战,我们旨在利用基础模型的语义理解能力和SLAM的空间精度来构建在语义和空间上均一致的地图。基础模型具有强大的语义理解能力,但在没有预先构建且嵌入语义特征的地图时,空间推理能力有限。相反,SLAM系统擅长捕获空间信息,但往往难以维持可靠的语义信息。通过整合这些优势,我们提出了对象SLAM的语义增强(SemanticEnhancementforObjectSLAM,SEO-SLAM)这一新颖方法,该方法利用VLM和MLLM实现语义SLAM。
我们在具有挑战性的数据集上对SEO-SLAM进行评估,其在存在多个相似物体的环境中的准确性和稳健性明显提升。我们的系统在路标匹配精度和语义一致性方面优于现有方法。结果表明,MLLM的反馈改进了以对象为中心的语义映射。
02 主要贡献
1.将图像标记、基于标签的定位以及分割模型整合到SLAM流程中,以实现描述性开放式词汇对象检测,并优化地标的语义信息。
2.利用MLLMs为现有地标生成更具描述性的标签,并校正错误地标以减少感知混淆。
3.提出一种使用MLLM响应来更新多类别预测混淆矩阵并识别重复地标的方法。
4.实验结果表明,在具有多个紧邻相似对象的具有挑战性的场景中,对象语义映射精度得到了提高。
5.引入在单个场景中具有语义相似对象的数据集,其中包含里程计、真实轨迹数据和真实对象信息。
03 方法架构
SEO-SLAM旨在通过整合丰富的语义信息来解决MAP问题。为了适应开放式词汇表的语义,我们仅使用几何信息来优化MAP问题,并利用我们测量中的语义和几何信息之间的联系。这通过融合来自检测器和深度图像的语义信息来实现。我们的方法可以处理开放式词汇表的语义类别,无需为多类预测混淆矩阵的类预测统计信息提供先验知识。图2展示了我们SEO-SLAM管道的整体架构。
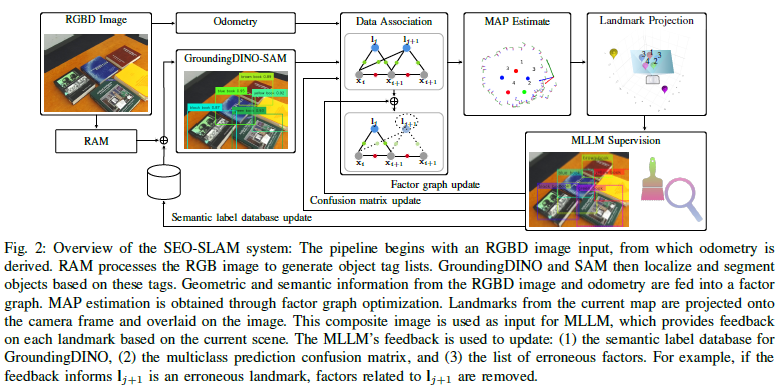
04 实验
A.数据采集
我们在室内房间环境中采集了六个涵盖日常物品的数据集(见表II)。依据现存物体的数量,我们将这些数据集归类为小(约10个)、中(约20个)或大(约30个)类别。我们采用ZED2i立体相机来收集RGB图像及里程数据。通过OptiTrack运动捕捉系统获取真实轨迹。为构建具有挑战性的场景,我们将相同类别的物体放置得较为临近。
B.实验设置
我们运用RAM++大型模型(加上swin大型模型)进行图像标注,并滤除那些过于宽泛且不代表单个物体的标签(例如,“坐”、“白色”、“许多物体”)。对象定位由GroundingDINO大型模型(swinbcogcoor)处理,而分割任务则使用带有ViT-H模型的SAM完成。在我们的RGS模型中,我们将置信度阈值设为0.5,将GroundingDINO的IoU阈值设为0.5。对于MLLMs,我们利用ChatGPTAPI(gpt-4o版本),在LandmarkEval和ClassLabelGen中均使用默认设置,并异步执行以优化我们的系统速度。

我们针对这六个数据集(见表II)开展了实验。我们的评估指标涵盖地标语义的准确性、错误地标的数量以及绝对位姿误差(APE)。我们对三种方法进行了比较:我们的SEO-SLAM方法,其使用RGS作为对象检测器,并结合基于MLLM的反馈来细化地标;单独使用RGS的方法,其运用RAM-Grounded-SAM进行开放词汇检测,且无MLLM反馈;以及YOLO方法(基准线),使用预先训练的YOLOv8进行对象检测。这种实验设置使我们能够全面评估在开放词汇环境中不同数据集和方法的语义映射性能以及轨迹精度。
C.结果
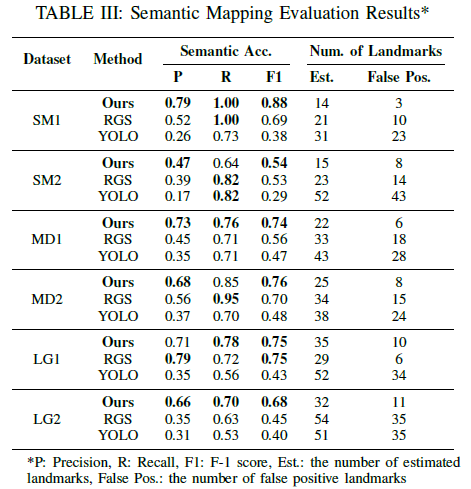
表III全面展示了在六个复杂程度各异的数据集上,我们的方法、RGS与YOLO之间语义映射性能的对比情况。结果表明,在语义准确性及地标数量估计方面,我们的方法始终优于其他两种方法。在多数数据集中,我们的方法达到了最高的精度和F1分数,这表明借助反馈,语义准确性得到了提升。在SM1、MD1和LG2中这一情况尤为显著,我们的方法保持了稳定的性能,而RGS和YOLO的表现则有所下降。值得注意的是,与其他方法相比,我们的方法通常产生的假阳性地标更少,这显示出其在复杂环境中的更强鲁棒性。我们的方法表现出色,这可归因于其能够利用MLLM反馈来细化地标描述并降低感知混叠。然而,在LG1中,我们的方法与RGS的表现相近,原因是每个帧中的物体数量较多,从而降低了MLLM反馈的质量。总体而言,结果证明了SEO-SLAM在提高语义映射准确性和减少假阳性方面,在各种环境复杂度下都是有效的。

我们还评估了每种方法相对于里程计的轨迹误差(图5)。在所有数据集中,我们的方法始终显示出更低的中位APE。RGS也表现良好,其中位误差较低,异常值少于YOLO。YOLO显示出最高的中位误差和异常值,因为YOLO只能检测训练数据集中的物体。这表明我们的开放式词汇检测器在各种条件下更具稳健性和准确性。图4展示了MD1数据集的定性结果。SEO-SLAM成功区分了邻近的物体,并展示了其根据场景变化更新语义地图的能力。虽然SEO-SLAM能够捕获大多数物体,但当物体过于靠近时,有时也会遇到困难。例如,它在场景中仅绘制了一本书。
D.局限性
虽然SEO-SLAM在语义映射方面取得了显著的改进,但仍需承认存在一些局限性。我们发现,在SEO-SLAM中,MLLM难以从颜色相近且同属一类的物体中生成非基于颜色的独特标签。此外,其性能对环境光照条件敏感,这可能会影响基于颜色的物体识别性能。未来,我们计划通过元提示,使MLLM能够依据物体的独特特征生成标签,以解决这些问题。
05 总结
我们提出了一种被命名为 SEO-SLAM 的创新方法,旨在拥挤的室内环境中强化对象级语义映射。此方法借助基础模型的语义理解能力,通过引入 MLLMs 的反馈来化解现有语义 SLAM 系统中的关键难题。借助反馈,SEO-SLAM 能够生成更具描述性的开放式词汇对象标签,同步校正导致虚假地标的诸因素,并动态更新多类混淆矩阵。实验结果显示,SEO-SLAM 在不同复杂程度的数据集上始终优于基线方法,提升了语义准确性、地标估计精度和轨迹准确性。该方法尤其善于降低假阳性地标数量,并增强在存在多个相似对象环境中的稳健性。故而,SEO-SLAM 标志着将基础模型的语义理解能力与 SLAM 系统的空间精度相融合的重大进展。本文为在复杂动态的环境中达成更精确且稳健的语义映射开辟了崭新的路径。(想要了解更多文章细节的读者,可以阅读一下论文原文~)
-
模型
+关注
关注
1文章
3810浏览量
52257 -
SLAM
+关注
关注
24文章
459浏览量
33413 -
LLM
+关注
关注
1文章
350浏览量
1394
原文标题:更准确,更鲁棒!利用VLM和MLLMs实现SLAM语义增强
文章出处:【微信号:gh_c87a2bc99401,微信公众号:INDEMIND】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Actian推出对话式分析解决方案,依托智能生成的语义基础,提供可信洞见
ROS2 SLAM建图与导航实战--基于米尔RK3576开发板
基于NVIDIA GPU加速端点使用千问3.5 VLM开发原生多模态智能体
什么是VLM?为什么它对自动驾驶很重要?
已有VLM,自动驾驶为什么还要探索VLA?
什么是激光雷达 3D SLAM技术?

FPGA和GPU加速的视觉SLAM系统中特征检测器研究

自动驾驶中如何将稀疏地图与视觉SLAM相结合?
微店关键词搜索接口核心突破:动态权重算法与语义引擎的实战落地
全新轻量级ViSTA-SLAM系统介绍
【HZ-T536开发板免费体验】3 - Cangjie Magic调用视觉语言大模型(VLM)真香,是不是可以没有YOLO和OCR了?
基于深度学习的增强版ORB-SLAM3详解
三维高斯泼溅大规模视觉SLAM系统解析




评论