 聚类分析的简单案例
聚类分析的简单案例

基本概念
聚类就是一种寻找数据之间一种内在结构的技术。聚类把全体数据实例组织成一些相似组,而这些相似组被称作聚类。处于相同聚类中的数据实例彼此相同,处于不同聚类中的实例彼此不同。聚类技术通常又被称为无监督学习,因为与监督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。
通过上述表述,我们可以把聚类定义为将数据集中在某些方面具有相似性的数据成员进行分类组织的过程。因此,聚类就是一些数据实例的集合,这个集合中的元素彼此相似,但是它们都与其他聚类中的元素不同。在聚类的相关文献中,一个数据实例有时又被称为对象,因为现实世界中的一个对象可以用数据实例来描述。同时,它有时也被称作数据点(Data Point),因为我们可以用r 维空间的一个点来表示数据实例,其中r 表示数据的属性个数。下图显示了一个二维数据集聚类过程,从该图中可以清楚地看到数据聚类过程。虽然通过目测可以十分清晰地发现隐藏在二维或者三维的数据集中的聚类,但是随着数据集维数的不断增加,就很难通过目测来观察甚至是不可能。
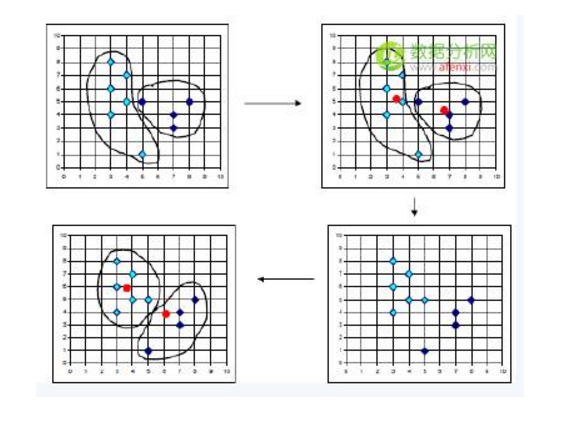
SAS聚类分析案例
1 问题背景
考虑下面案例,一个棒球管理员希望根据队员们的兴趣相似性将他们进行分组。显然,在该例子中,没有响应变量。管理者希望能够方便地识别出队员的分组情况。同时,他也希望了解不同组之间队员之间的差异性。
该案例的数据集是在SAMPSIO库中的DMABASE数据集。下面是数据集中的主要的变量的描述信息:
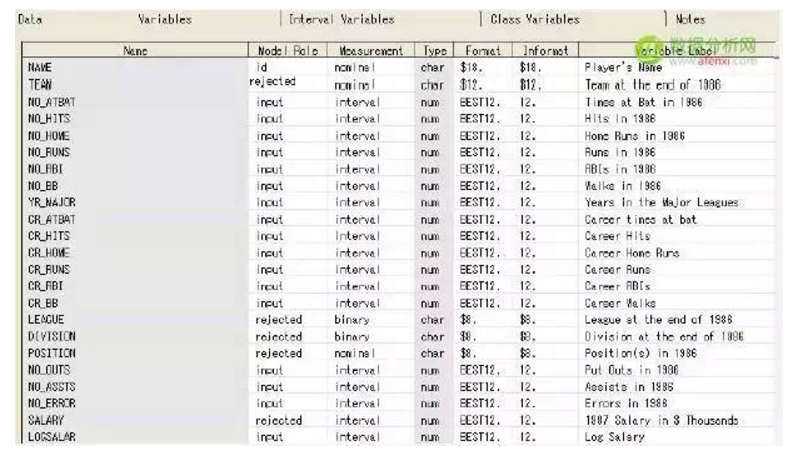
在这个案例中,设置TEAM,POSITION,LEAGUE,DIVISION和SALARY变量的模型角色为rejected,设置SALARY变量的模型角色为rejected是由于它的信息已经存储在LOGSALAR中。在聚类分析和自组织映射图中是不需要目标变量的。如果需要在一个目标变量上识别分组,可以考虑预测建模技术或者定义一个分类目标。
2 聚类方法概述
聚类分析经常和有监督分类相混淆,有监督分类是为定义的分类响应变量预测分组或者类别关系。而聚类分析,从另一方面考虑,它是一种无监督分类技术。它能够在所有输入变量的基础上识别出数据集中的分组和类别信息。这些组、簇,赋予不同的数字。然而,聚类数目不能用来评价类别之间的近似关系。自组织映射图尝试创建聚类,并且在一个图上用图形化的方式绘制出聚类信息,在此处我们并没有考虑。
1) 建立初始数据流
2) 设置输入数据源结点
打开输入数据源结点
从SAMPSIO库中选择DMABASE数据集
设置NAME变量的模型角色为id,TEAM,POSIOTION,LEAGUE,DIVISION和SALARY变量的模型角色为rejected
探索变量的分布和描述性统计信息
选择区间变量选项卡,可以观察到只有LOGSALAR和SALARY变量有缺失值。选择类别变量选项卡,可以观察到没有缺失值。在本例中,没有涉及到任何类别变量。
关闭输入数据源结点,并保存信息。
3) 设置替代结点
虽然并不是总是要处理缺失值,但是有时候缺失值的数量会影响聚类结点产生的聚类解决方案。为了产生初始聚类,聚类结点往往需要一些完整的观测值。当缺失值太多的时候,需要用替代结点来处理。虽然这并不是必须的,但是在本例中使用到了。
4) 设置聚类结点
打开聚类结点,激活变量选项卡。K-means聚类对输入数据是敏感的。一般情况下,考虑对数据集进行标准化处理。
在变量选项卡,选择标准偏差单选框
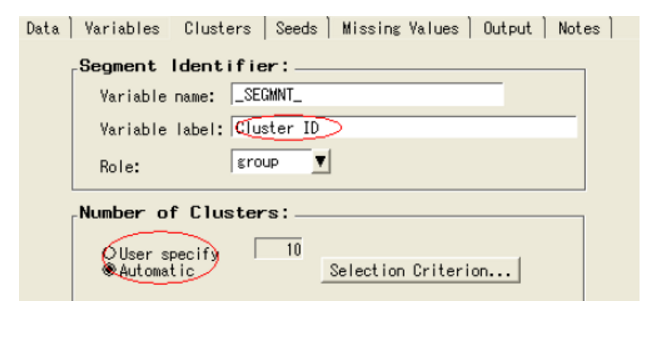
选择聚类选项卡
观察到默认选择聚类数目的方法是自动的
关闭聚类结点
5) 聚类结果
在聚类结点处运行流程图,查看聚类结果。
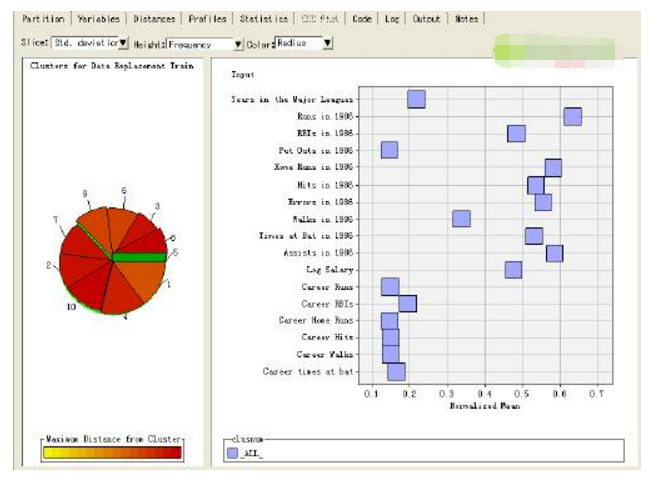
6) 限定聚类数目
打开聚类结点
选择聚类选项卡
在聚类数目选择部分,点击选择标准按钮
输入最大聚类数目为10
点击ok,关闭聚类结点
7)结果解释
我们可以定义每个类别的信息,结合背景识别每个类型的特征。选择箭头按钮,
选择三维聚类图的某一类别,
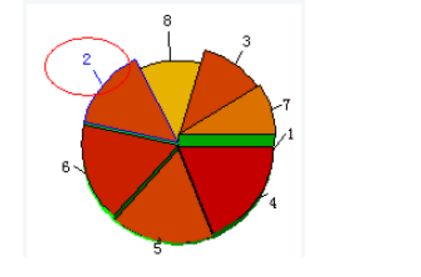
在工具栏选择刷新输入均值图图标,
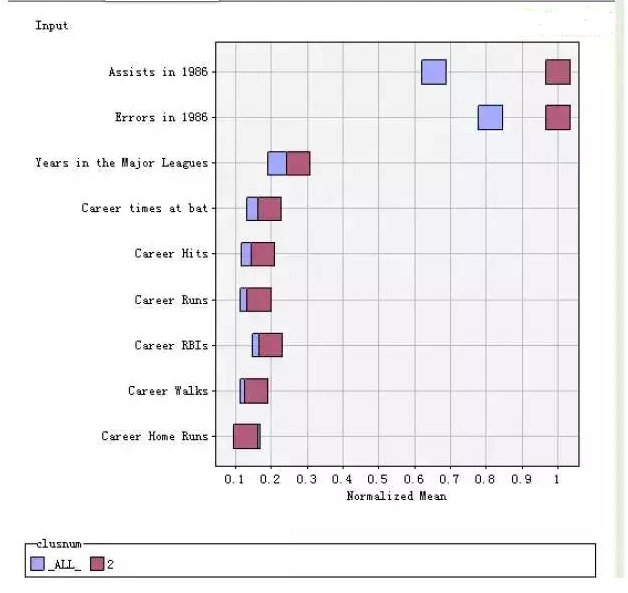
点击该图标,可以查看该类别的规范化均值图
同理,可以根据该方法对其他类别进行解释。
8)运用Insight结点
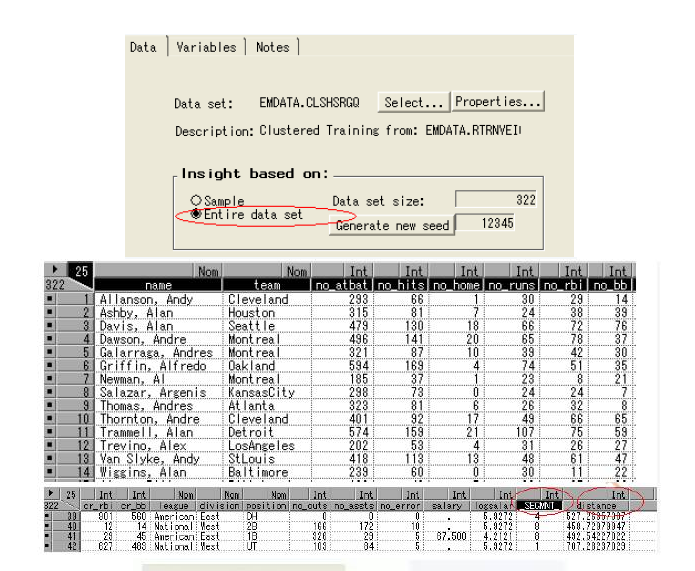
Insight结点可以用来比较不同属性之间的异常。打开insight结点,选择整个数据集,关闭结点。
从insight结点处运行。
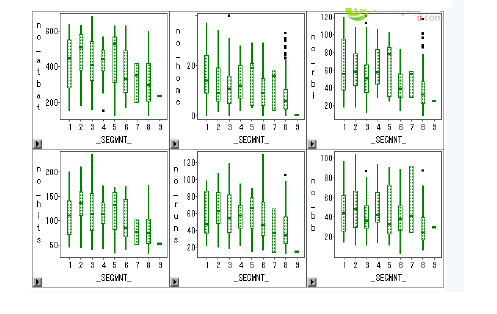
变量_SEGMNT_标识类别,distance标识观测值到所在类别中心的距离。运用insight窗口的analyze工具评估和比较聚类结果。
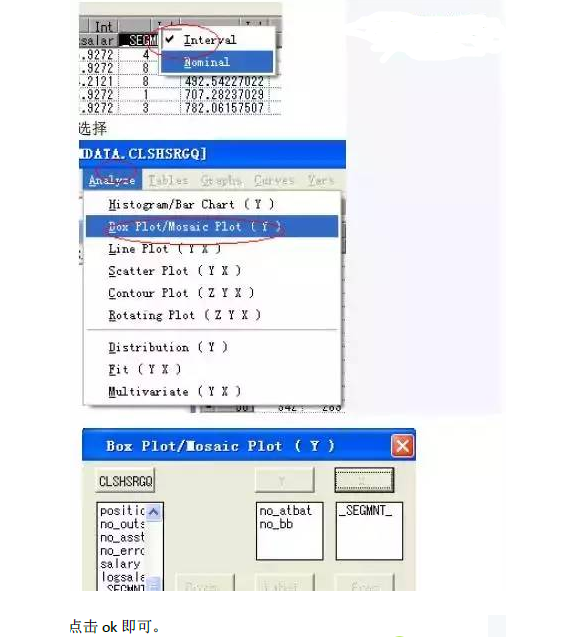
首先把_SEGMNT_的度量方式从interval转换成nominal。
聚类应用
在商业上,聚类分析被用来发现不同的客户群,并且通过购买模式刻画不同的客户群的特征。聚类分析是细分市场的有效工具,同时也可用于研究消费者行为,寻找新的潜在市场、选择实验的市场,并作为多元分析的预处理。在生物上,聚类分析被用来动植物分类和对基因进行分类,获取对种群固有结构的认识。在地理上,聚类能够帮助在地球中被观察的数据库商趋于的相似性。在保险行业上,聚类分析通过一个高的平均消费来鉴定汽车保险单持有者的分组,同时根据住宅类型,价值,地理位置来鉴定一个城市的房产分组。在因特网应用上,聚类分析被用来在网上进行文档归类来修复信息。在电子商务上,聚类分析在电子商务中网站建设数据挖掘中也是很重要的一个方面,通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好的帮助电子商务的用户了解自己的客户,向客户提供更合适的服务。
聚类分析应用——市场细分
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。
从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。聚类是观察式学习,而不是示例式的学习。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。
聚类分析的核心思想就是物以类聚,人以群分。在市场细分领域,消费同一种类的商品或服务时,不同的客户有不同的消费特点,通过研究这些特点,企业可以制定出不同的营销组合,从而获取最大的消费者剩余,这就是客户细分的主要目的。在销售片区划分中,只有合理地将企业所拥有的子市场归成几个大的片区,才能有效地制定符合片区特点的市场营销战略和策略。金融领域,对基金或者股票进行分类,以选择分类投资风险。
下面以一个汽车销售的案例来介绍聚类分析在市场细分中的应用。
商业目标
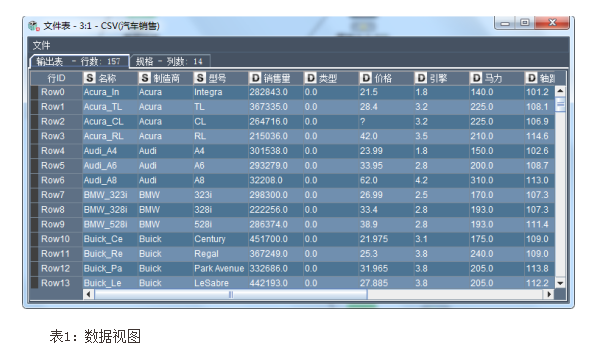
业务理解:数据名称《汽车销售.csv》。该案例所用的数据是一份关于汽车的数据,该数据文件包含销售值、订价以及各种品牌和型号的车辆的物理规格。订价和物理规格可以从 edmunds.com 和制造商处获得。定价为美国本土售价。如下:
业务目标:对市场进行准确定位,为汽车的设计和市场份额预测提供参考。
数据挖掘目标:通过聚类的方式对现有的车型进行分类。
数据准备
通过数据探索对数据的质量和字段的分布进行了解,并排除有问题的行或者列优化数据质量。
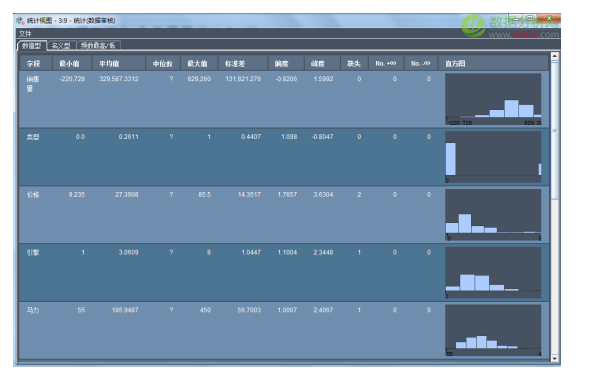
第一步,我们使用统计节点审核数据的质量,从审核结果中我们发现存在缺失的数据,如下图所示:
第二步,对缺失的数据进行处理,我们选择使用缺失填充节点删除这些记录。配置如下:
建模
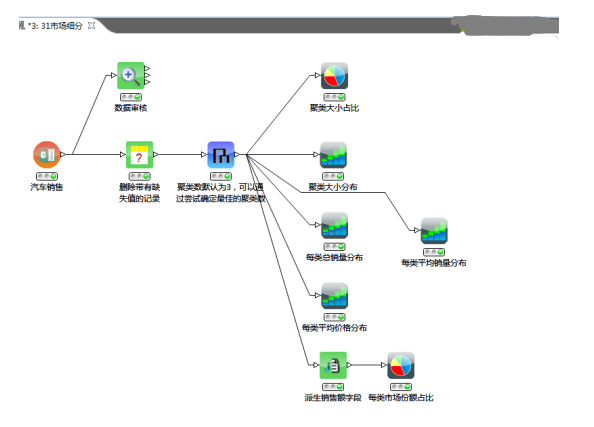
我们选择层次聚类进行分析,尝试根据各种汽车的销售量、价格、引擎、马力、轴距、车宽、车长、制动、排量、油耗等指标对其分类。
因为层次聚类不能自动确定分类数量,因此需要我们以自定义的方式规定最后聚类的类别数。层次聚类节点配置如下(默认配置):
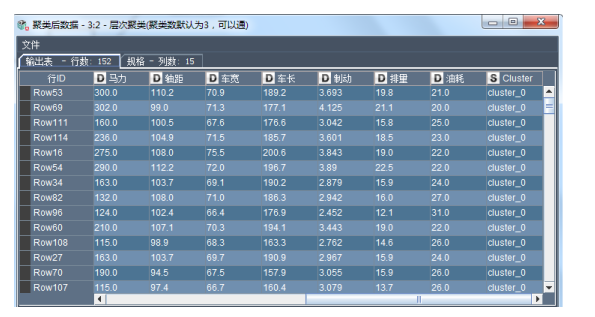
可以使用交互表或者右击层次聚类节点查看聚类的结果,如下图所示:
再使用饼图查看每个类的大小,结果如下:
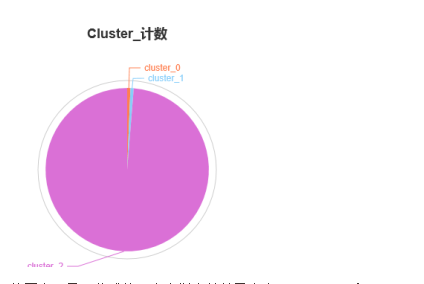
从图中可见,分成的三个类样本数差异太大,cluster_0和cluster_1包含的样本数都只有1,这样的分类是没有意义的,因此需要重新分类。我们尝试在层次聚类节点的配置中指定新的聚类方法:完全。新的聚类样本数分布如下:
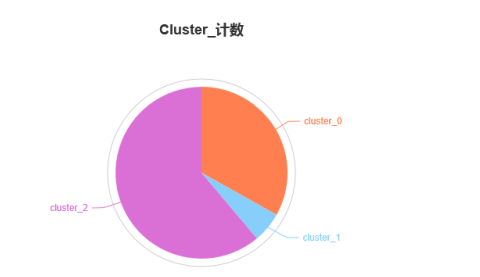
cluster_0、 cluster_1、cluster_2的样本数分别为:50、9、93。
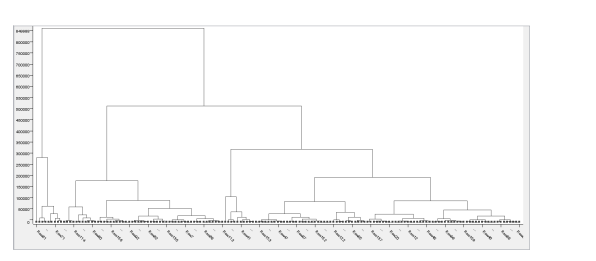
执行后输出树状/冰柱图,可以从上往下看,一开始是一大类,往下走就分成了两类,越往下分的类越多,最后细分到每一个记录是一类,如下所示:
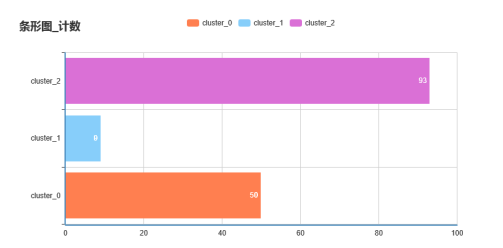
我们可以再使用条形图查看每类的销售量、平均价格,如下图所示:
每类总销量分布图
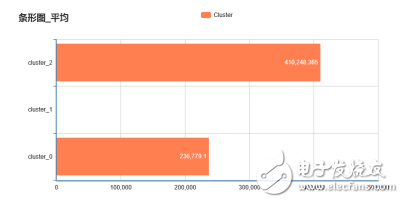
每类平均销量分布图
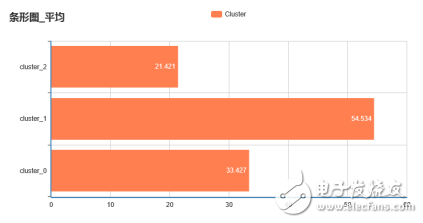
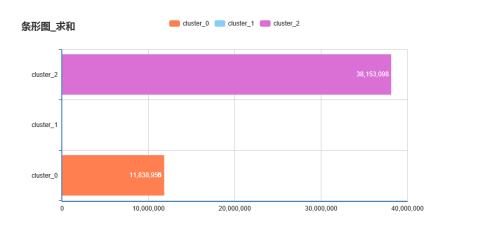
每类平均价格分布图
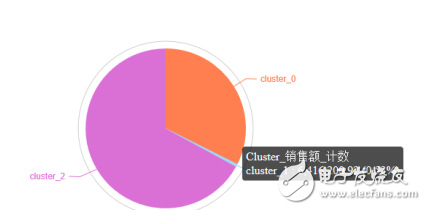
我们再看一下每类的销售额分布情况。首先,我们需要使用Java代码段节点或者派生节点生成销售额字段,配置如下:
再使用饼图查看销售额分布情况,cluster_0、 cluster_1、cluster_2的市场份额分别为:32.39%、0.53%和67.08%,如下图所示:
案例小结
通过这个案例,大家可以发现聚类分析确实很简单。进行聚类计算后,主要通过图形化探索的方式评估聚类合理性,以及在确定聚类后,分析每类的特征。
-
聚类分析
+关注
关注
0文章
16浏览量
7595
发布评论请先 登录
[VirtualLab] 激光引导无焦系统的分析与设计
[VirtualLab] 椭圆偏振分析器
罗德与施瓦茨 FPL1003 频谱分析仪
罗德与施瓦茨 FSWP8 相位噪声分析仪
德国罗德与施瓦茨 FSV3004 频谱分析仪
矢量网络分析仪与标量网络分析仪的区别

linux-arm开发环境的简单配置
红外光谱技术应用与原理分析
现代功率分析仪的演进

看似简单的自动泊车需要哪些技术支撑?

如何用FIB截面分析技术做失效分析?
谐波怎么处理最简单的方法




评论