 Arm Neoverse与AWS Graviton4加速云计算创新
Arm Neoverse与AWS Graviton4加速云计算创新
作者:Arm 基础设施事业部服务器生态系统开发总监
Bhumik Patel
随着人工智能 (AI) 技术的迅猛发展,云计算领域正在经历显著变革。愈发复杂的 AI 应用对计算解决方案的性能、效率和成本效益提出了更高要求。在云端部署工作负载的客户正在重新评估其所需的基础设施,以满足现代工作负载需求,其中不仅包括提高性能和降低成本,还涵盖了需符合监管要求或可持续发展目标的新能效基准。
Arm 与亚马逊云科技 (AWS) 长期合作,为实现性能更强劲、更高效和可持续的云计算提供专用芯片和计算技术。在近期举行的 AWS re:Invent 2024 大会上,AWS 进一步展示了 AWS Graviton4 所取得的显著进展,使开发者和企业能够充分发挥其云工作负载的性能潜力。
卓越的性能表现
相较于上一代 Graviton3 处理器,基于 Arm Neoverse V2 平台的 AWS Graviton4 处理器在计算性能上提升了 30%,核心数增加了 50%,内存带宽提高了 75%。凭借这些技术优势,AWS Graviton 处理器在生态系统和客户群体中得到了广泛应用。
Arm Neoverse V2 平台涵盖 Armv9 架构的新特性,包括高性能浮点和向量指令支持,以及 SVE/SVE2、Bfloat16 和 INT8 MatMul 等特性。这些特性为 AI/机器学习 (ML) 以及高性能计算 (HPC) 工作负载提供了卓越性能。
AI/ML 工作负载
今年早些时候,Arm 与主流的 AI 框架和软件生态系统合作,推出了 Arm Kleidi 软件,以确保 Arm 平台上开机即用的推理性能优化能惠及整个 ML 栈,开发者无需掌握额外的 Arm 专业知识即可构建其工作负载,从而进一步推动 AI 工作负载的广泛应用。此前,我们已展示了 PyTorch 中的这些优化如何赋能 AWS Graviton4 上运行大语言模型 (LLM),如 Llama 3 70B 和 Llama 3.1 8B,并显著改善了每秒生成词元 (token) 数和词元首次响应时间的表现指标。
欢迎阅读《Arm KleidiAI 助力提升 PyTorch 上 LLM 推理性能》一文,详细了解性能指标的提升细节。
HPC 和 EDA 工作负载
对于 HPC 工作负载,Graviton4 相较于 Graviton3E 在功能上实现了显著提升。每个核心的主内存带宽增加了16%,每个 vCPU 的 L2 缓存容量翻倍。这些改进对于 HPC 应用的性能至关重要,因为 HPC 应用通常受限于内存带宽。AWS 已经在这些领域取得了显著优势,如下所示。
根据 Arm 工程团队实际运行 EDA 工作负载所得出的结果,Graviton4 提供的 RTL 仿真工作负载性能比 Graviton3 高出 37%。
生态系统广泛采用
近年来,随着云计算用户将各种云工作负载部署在 AWS Graviton 处理器上,其软件生态系统持续扩展。如此一来,客户不仅节省了费用,收获了性能的提升,还能优化其碳足迹和可持续发展足迹。以下是部分示例:
着手利用 Graviton 的强大性能
我们坚信 Arm 将在云计算的未来中发挥关键作用,同时我们也非常自豪能够支持 AWS Graviton 立于技术创新的前沿。Arm 将继续投入,进一步强化我们的软件生态系统,从而使开发者能够更加轻松地在 Arm 平台上构建其应用,并充分利用 Arm 计算平台所提供的卓越性能和效率优势。
-
处理器
+关注
关注
68文章
19242浏览量
229593 -
ARM
+关注
关注
134文章
9079浏览量
367293 -
云计算
+关注
关注
39文章
7769浏览量
137330 -
AI
+关注
关注
87文章
30643浏览量
268822
原文标题:Arm Neoverse 赋能 AWS Graviton4 处理器,加速云计算创新
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Arm Neoverse如何加速实现AI数据中心
亚马逊云科技宣布基于自研Amazon Graviton4的Amazon EC2 R8g实例正式可用
亚马逊网络服务即将推出第四代Graviton处理器
ARM进军汽车芯片市场,推出Neoverse设计
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3

Google Cloud推出基于Arm Neoverse V2定制Google Axion处理器
Arm Neoverse CSS V3 助力云计算实现 TCO 优化的机密计算
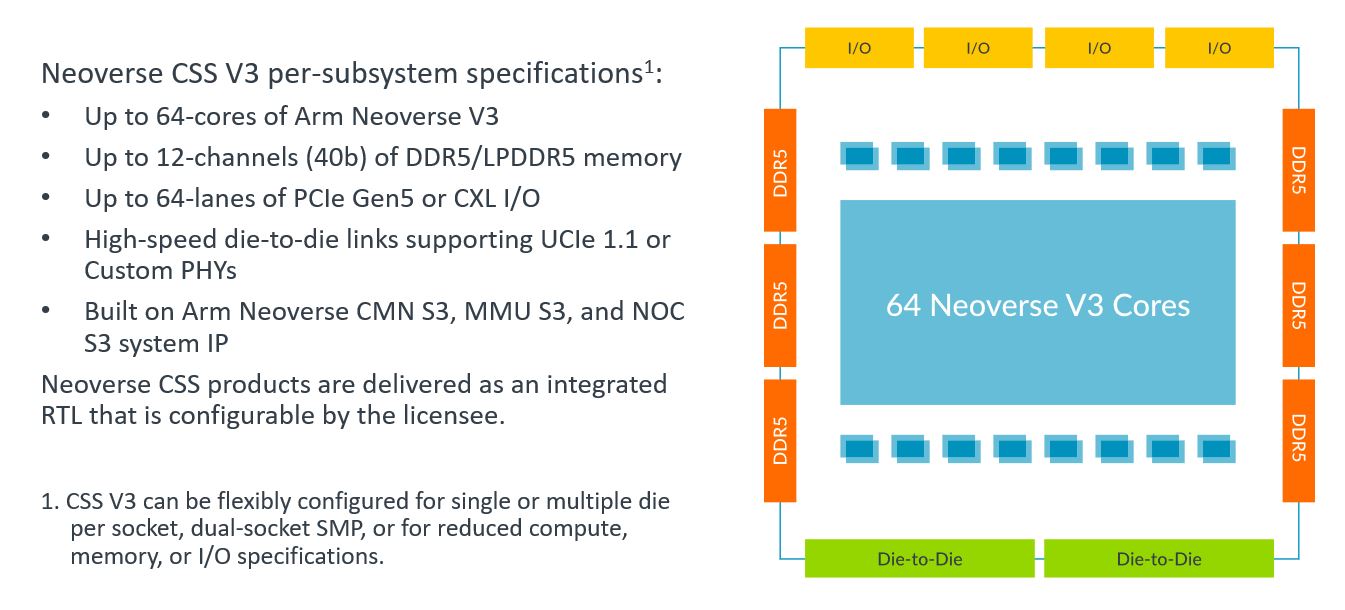
Arm Neoverse S3 系统 IP 为打造机密计算和多芯粒基础设施 SoC 夯实根基
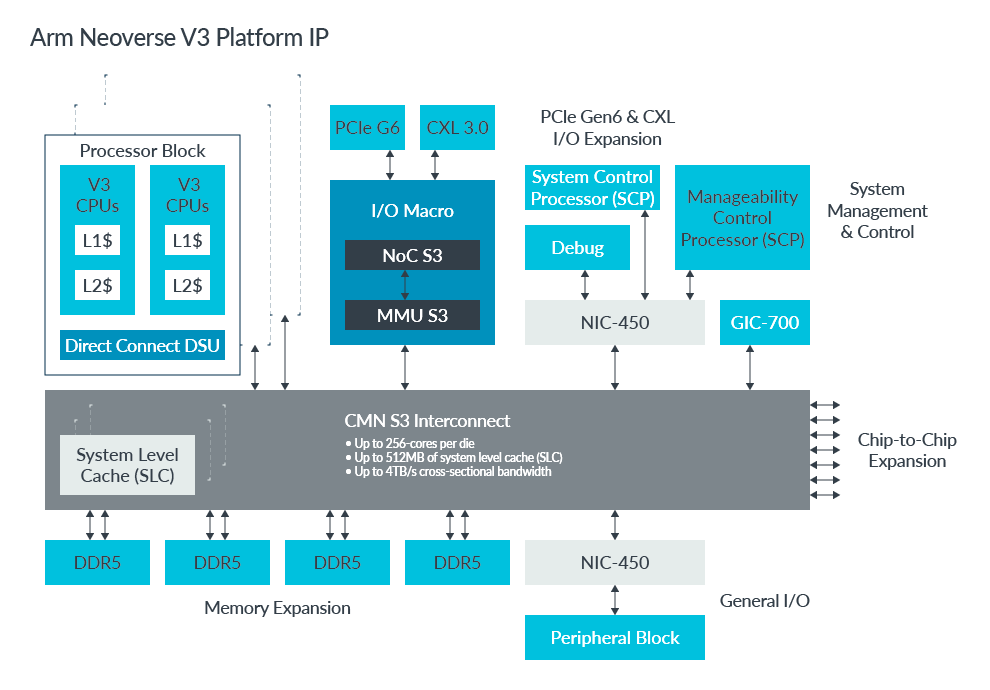
Neoverse CSS V3助力云计算实现TCO优化的机密计算

Arm Neoverse CSS N3助力快速实现出色能效

Arm发布Neoverse V3和N3 CPU内核
FunASR语音大模型在Arm Neoverse平台上的优化实践流程





 工商网监
工商网监
评论