 准确性超Moshi和GLM-4-Voice,端到端语音双工模型Freeze-Omni
准确性超Moshi和GLM-4-Voice,端到端语音双工模型Freeze-Omni
GPT-4o 提供的全双工语音对话带来了一股研究热潮,目前诸多工作开始研究如何利用 LLM 来实现端到端的语音到语音(Speech-to-Speech)对话能力,但是目前大部分开源方案存在以下两个问题:
LLM 灾难性遗忘:由于现有方案在语音模态与 LLM 进行对齐时,会或多或少对 LLM 进行微调,但由于要采集到与 LLM 本身训练的文本数据同等量级的语音数据是非常困难的,所以这一微调过程往往会导致 LLM 出现遗忘现象,造成 LLM 的聪明度下降
语音问答(Spoken Question Answering)任务的评估:多数工作对于语音问答的准确性并没有进行定量评估,从已有的一些评估结果也可以看出同一模型语音问答和文本问答相比准确性会有明显的差距
针对上述这些问题,近日腾讯&西工大&南大的研究人员提出了一种低延迟的端到端语音双工对话模型 Freeze-Omni(VITA 大模型系列第二个工作),其可以在完全冻结 LLM 的情况下,为 LLM 接入语音输入和输出,使其能够支持端到端的语音对话能力,且通过一系列优化使得其具备低延迟的双工对话能力,其主要特性如下:
在整个训练过程中,LLM 的参数被完全冻结,确保大型语言模型的知识能力被完全保留;
训练过程中所依赖的数据规模较小,消耗的计算资源也较少。Freeze-Omni 仅需要文本-语音配对数据(如 ASR 和 TTS 训练数据,比较容易获得)以及仅少量的文本模态的问答数据,语音问答准确性显著超越 Moshi 与 GLM-4-Voice 等目前 SOTA 的模型;
Freeze-Omni 可以支持任何具有文本模态的(多模态)大语言模型,能够保留基底大语言模型的能力,如提示服从和角色扮演等。此外,如果有必要改变大语言模型的领域或者回应方式,只需要用相应的文本数据对大语言模型进行微调即可,不需要采集大量语音的问答和对话数据。

论文标题:
Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM
论文链接:
https://arxiv.org/abs/2411.00774
项目主页:
https://freeze-omni.github.io/
开源代码:
https://github.com/VITA-MLLM/Freeze-Omni
三阶段训练策略实现语音输入输出能力
Freeze-Omni 的整体结构如图 1 所示,其包含有语音编码器(Speech Encoder)和语音解码器(Speech Decoder)以及基底 LLM 三部分。 在运行过程中,流式的语音输入通过语音编码器形成分块(Chunk)特征,然后通过 Adapter 连接到 LLM,LLM 生成的 Hidden State 和文本 Token 的在分块分割后,分别以块的形式送入非自回归前缀语音解码器(NAR Prefix Speech Decoder)和非自回归语音解码器(NAR Speech Decoder)以进行 Prefill 操作。 最后自回归语音解码器(AR Speech Decoder)将会完成 Generate 操作以生成语音 Token,并由 Codec Decoder 将其流式解码为语音信号输出。
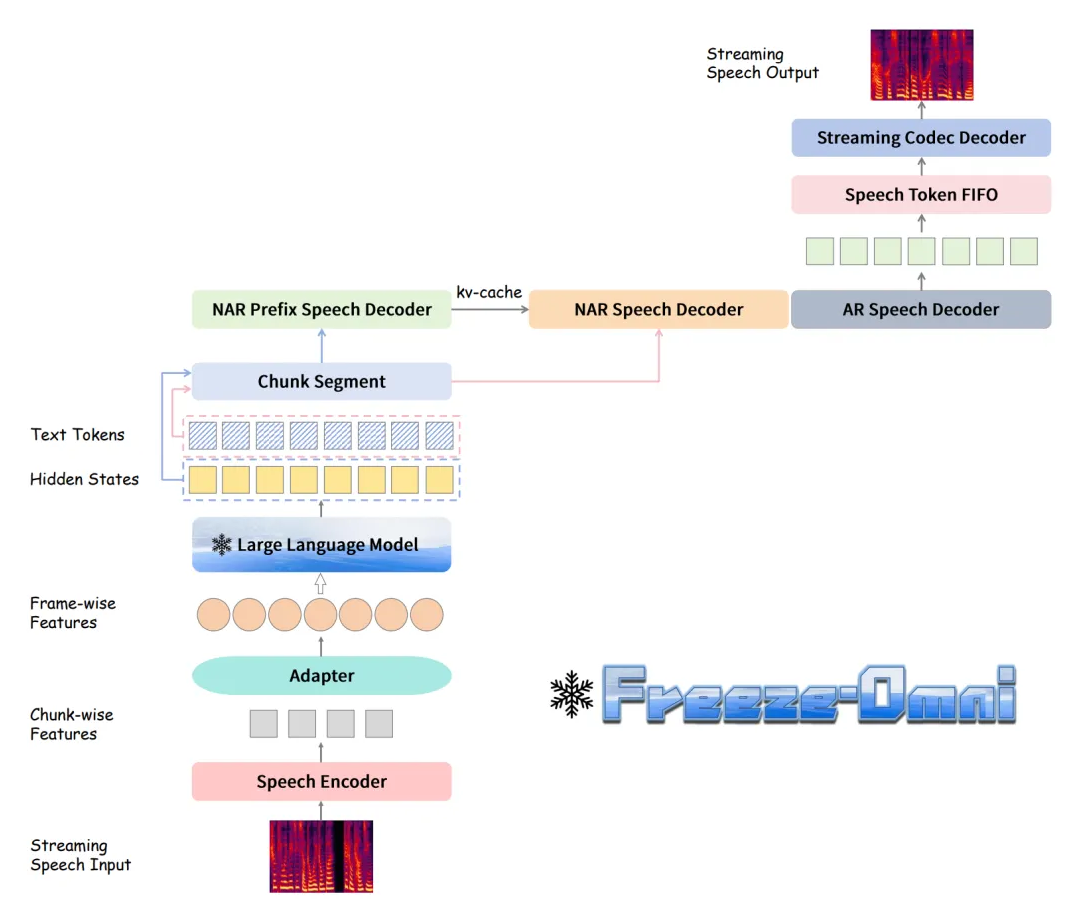
▲ 图1. Freeze-Omni框架图 Freeze-Omni 各个模块的三阶段训练策略如下: 流式语音编码器的三阶段训练:如图 2 所示,第一阶段(a)会先使用 ASR 数据训练一个具有 ASR 能力的语音编码。 第二阶段(b)会以 ASR 任务为优化目标,将语音编码器与 LLM 做模态对齐,这个过程中 LLM 是处于冻结状态的。 第三阶段(c)会使用由 TTS 系统合成的语音输入-文本回答的多轮 QA 数据进行训练,这里会使用第二阶段训练好的语音编码器,但是其参数保持冻结以保留其语音鲁棒性,而可训练的参数只有每个问题前的 Prompt Embedding,用于指导 LLM 从 ASR 任务迁移到 QA 任务中。
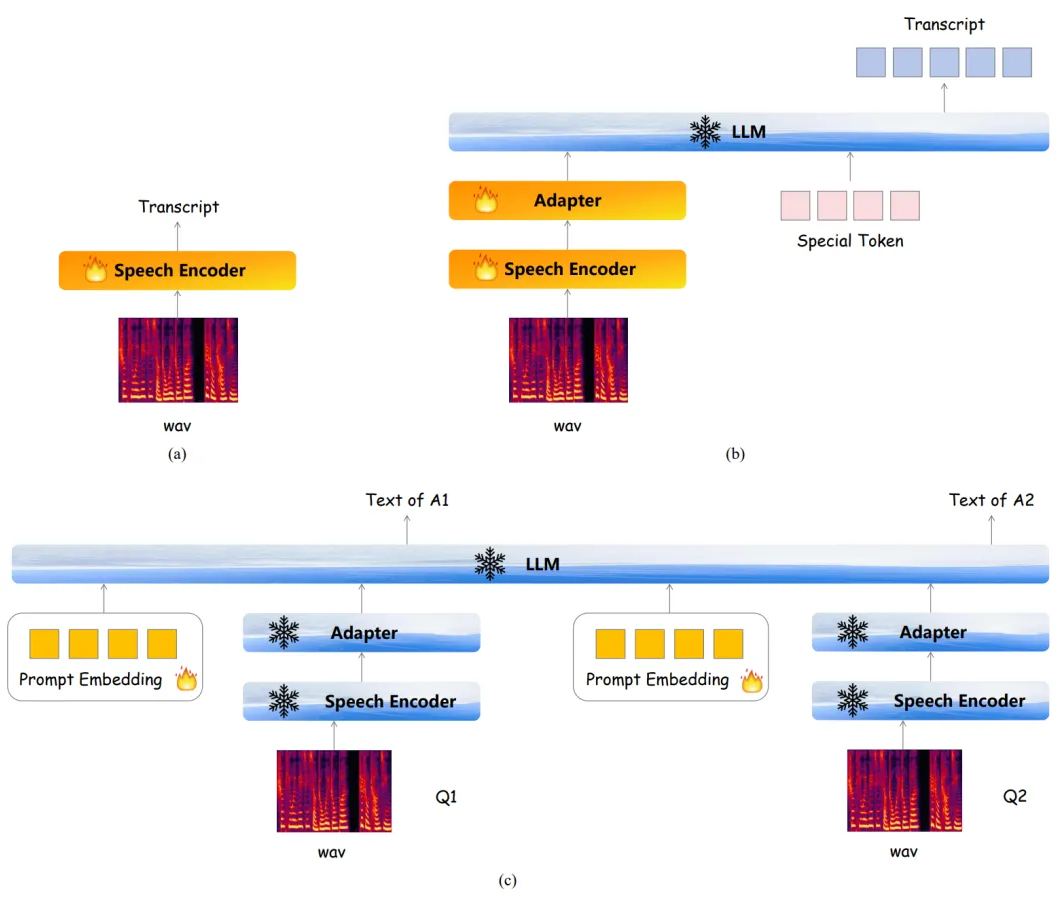
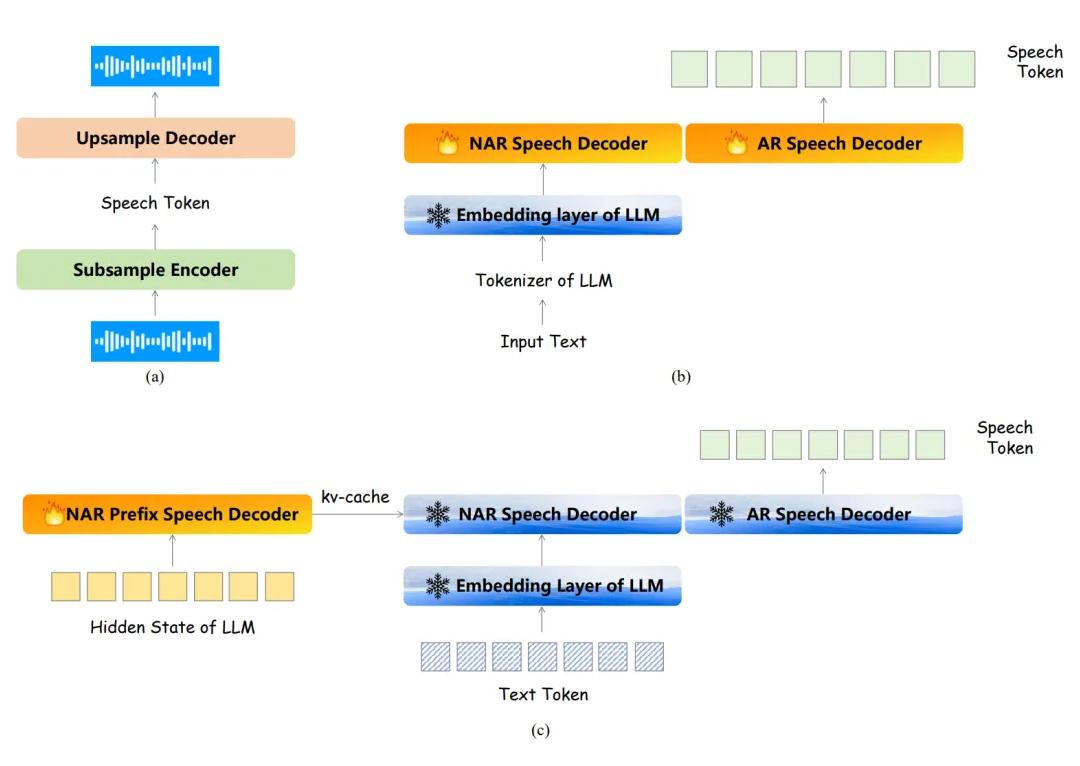
▲ 图2. 流式语音编码器的三阶段训练示意图 流式语音解码器的三阶段训练:如图 3 所示,第一阶段(a)会先训练一个单码本的语音编解码模型,使用单码本的目的主要是为了降低计算复杂度和时延。 第二阶段(b)将会训练 NAR 语音编码器和 AR 语音编码器,这里会使用文本-语音的 TTS 数据,其文本会通过基底 LLM 的 Tokenizer 转化为 Token,再经过基底 LLM 的 Embedding 层转化为文本特征,这个过程中 Embedding 的参数是冻结的,训练目标的语音 Token 是由第一阶段的语音编码器提供。 第三阶段(c)将会冻结第二阶段训练得到的所有网络,但同时加入了一个 NAR Prefix 语音编码器,其用于接受 LLM 输出的 Hidden State,并将输出的 kv-cache 作为第二阶段模型的初始 kv-cache,该过程使用的数据是文本输入-语音输出的 QA 数据,主要目的是为了使得语音编码器迁移到 LLM 的输出领域中。
▲ 图3. 流式语音解码器的三阶段训练示意图 双工对话的状态标签训练:如图 4 所示,为了实现双工交互,Freeze-Omni 在语音编码器训练的第三阶段中,会为每个 Chunk 的最后一个语音帧对应的 LLM 输出 Hidden State 加入一个额外的分类层进行多任务训练,其目的主要是为了输出状态标签。 当使用 VAD 激活语音流输入后,状态标签 0 表示 LLM 将会继续接受语音 Chunk 的输入,状态标签 1 表示 LLM 将会停止接收语音,且会打断用户并进入 LLM 的 Generate 阶段输出回复,状态标签 2 表示 LLM 也会停止接收语音,但不会打断用户,相当于对这次语音激活做了拒识。
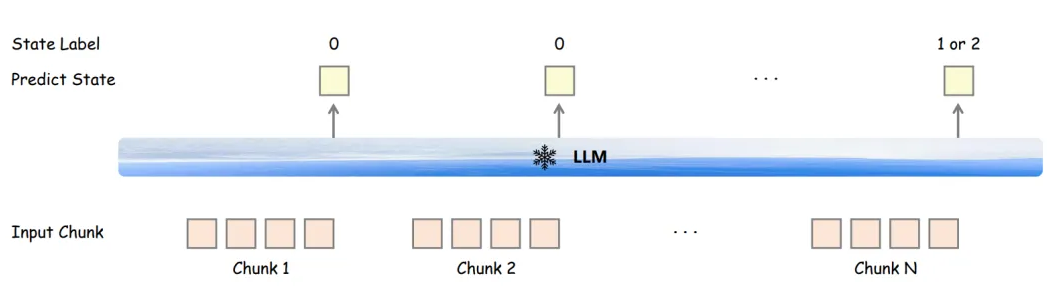
▲ 图4. 全双工对话的状态标签训练示意图
模型性能测评
训练配置:Freeze-Omni 在训练过程中,使用了开源 Qwen2-7B-Instruct 作为基底模型,语音编码器在训练过程中使用了 11 万小时中文英文混合的 ASR 数据,语音解码器训练过程使用了 3000 小时由 TTS 系统合成的文本-语音数据,所提到的 QA 数据是由 6 万条从 moss-003-sft-data 中抽取的多轮对话经过 TTS 系统合成得到的。 语音输入理解能力评估:Freeze-Omni 提供了其在常见的英文测试集上的 ASR 性能测试结果,从中可以看出,其 ASR 准确性处于较为领先的水平。
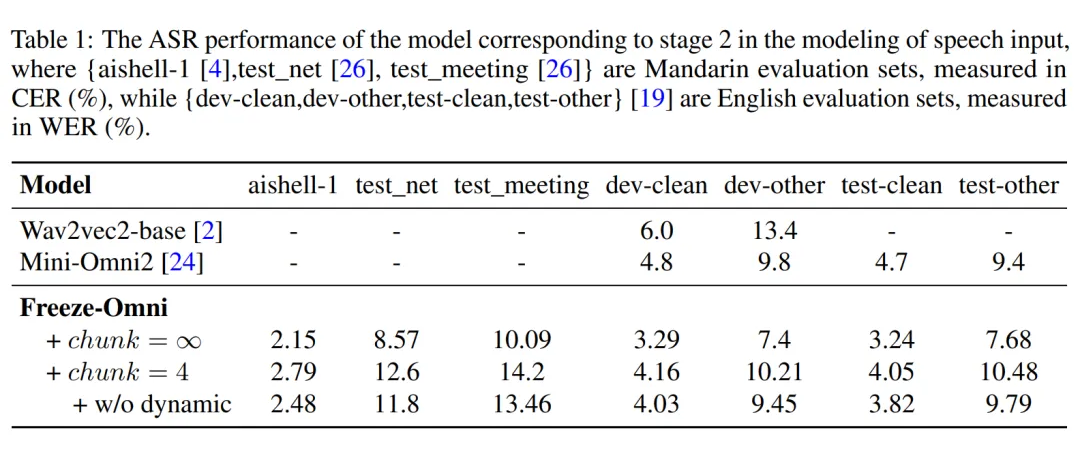
▲ 图5. 语音理解能力评估 语音输出质量评估:Freeze-Omni 提供了其在 1000 条 LLM 输出的 Hidden State 与 Text Token 上语音解码器生成的语音在使用 ASR 模型测试得到的词错误率(CER),从结果中可以看出 NAR Prefix 语音解码器的引入会有效降低词错误率,提高生成语音的质量。
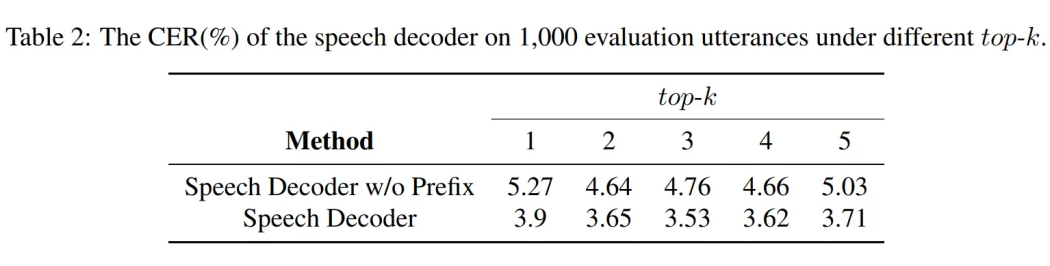
▲ 图6. 语音输出质量评估 语音问答准确性评估:Freeze-Omni 提供了其在 LlaMA-Questions, Web Questions, 和 Trivia QA 三个集合上的语音问答准确率评估。 从结果中可以看出 Freeze-Omni 的准确率具有绝对的领先水平,超越 Moshi 与 GLM-4-Voice 等目前 SOTA 的模型,并且其语音模态下的准确率相比其基底模型 Qwen2-7B-Instruct 的文本问答准确率而言,差距明显相比 Moshi 与其文本基底模型 Helium 的要小,足以证明 Freeze-Omni 的训练方式可以使得 LLM 在接入语音模态之后,聪明度和知识能力受到的影响最低。
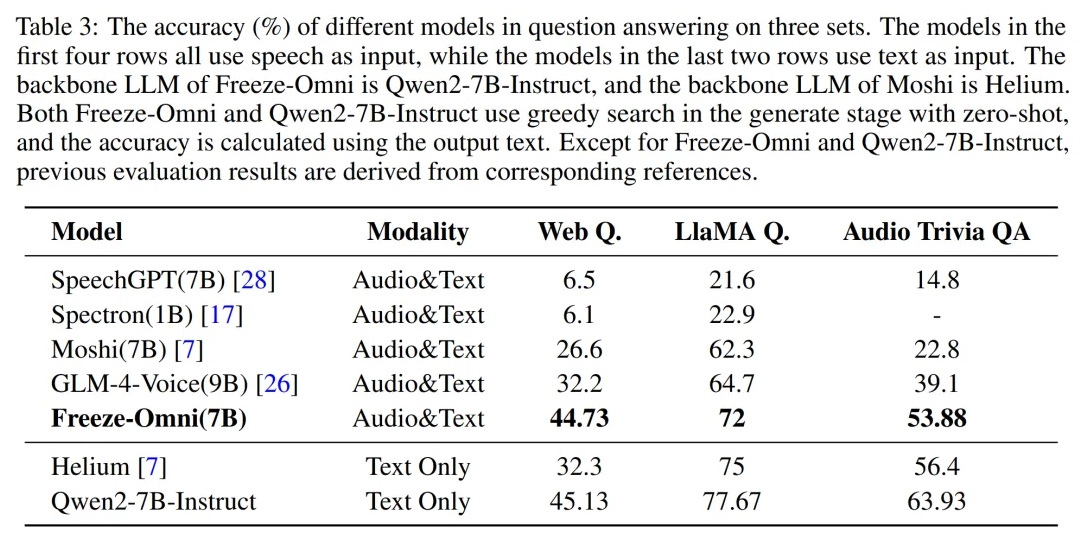
▲ 图7. 语音问答准确性评估 系统延迟评估:Freeze-Omni 还提供了端到端时延分析(即用户说完后到 LLM 输出音频的时间差),作者将其分为了可统计时延和不可统计时延两部分,其中可统计时延的总时长平均数仅为 745ms,而作者也提到如果经过测量考虑到网络延迟和不可统计时延部分,则系统的平均响应时延在 1.2s 左右,在行业内仍为领先水平。

▲ 图8. 系统延迟评估
-
模型
+关注
关注
1文章
3440浏览量
49609 -
LLM
+关注
关注
1文章
316浏览量
574
原文标题:准确性超Moshi和GLM-4-Voice!端到端语音双工模型Freeze-Omni
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用OpenVINO部署GLM-Edge系列SLM模型
智谱推出四个全新端侧模型 携英特尔按下AI普及加速键
如何提升ASR模型的准确性
连接视觉语言大模型与端到端自动驾驶

如何评估 ChatGPT 输出内容的准确性
端到端InfiniBand网络解决LLM训练瓶颈







 工商网监
工商网监
评论