 RAG的概念及工作原理
RAG的概念及工作原理

检索增强型生成(RAG)系统正在重塑我们处理AI驱动信息的方式。作为架构师,我们需要理解这些系统的基本原理,从而有效地发挥它们的潜力。
什么是RAG?
总体而言,RAG系统通过将大型语言模型(LLM)与外部知识源集成,增强了其能力。这种集成允许模型动态地引入相关信息,使其能够生成不仅连贯而且事实准确、上下文相关的回应。RAG系统的主要组成部分包括:
·检索器(Retriever): 该组件从外部知识库中获取相关数据。
·生成器(Generator): LLM将检索到的信息综合成类似人类的回应。
通过利用这些组件,RAG系统可以提供由实时数据而非仅依赖于预训练知识的信息所支持的答案,预训练知识可能很快过时。
RAG工作原理
RAG系统的架构可以想象成一个简单的管道:
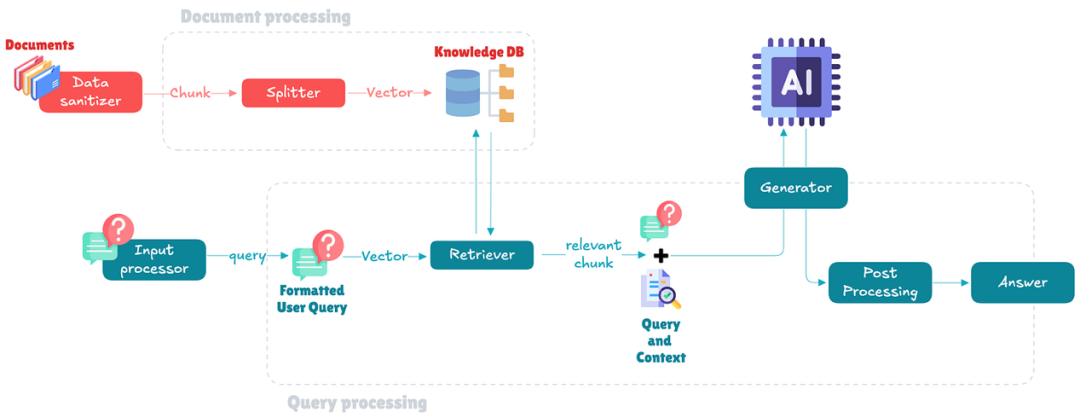
文档处理模块
·数据清理器(Data sanitizer): 该组件清洗和预处理传入的文档,确保数据准确且无噪声。它为文档的高效处理和存储做准备。
·分割器(Splitter): 分割器将文档分成更小、更易于管理的块。这一步对于创建可以高效存储和从数据库中检索的向量表示至关重要。
·知识数据库(Knowledge DB): 这是处理过的文档块作为向量存储的地方。数据库能够基于语义相似性快速检索相关信息。
查询处理模块
·输入处理器(Input processor): 该组件处理用户查询,执行解析和预处理任务,确保查询清晰且准备好检索。
·检索器(Retriever): 检索器在知识数据库中搜索与用户查询匹配的相关文档向量。它使用向量相似性度量来找到最相关的信息。
·生成器(Generator): 生成器使用大型语言模型(LLM)通过结合检索到的信息和自己的知识库来综合出一个连贯的回应。
这种设置允许RAG系统动态地引入相关数据,增强生成回应的准确性和相关性。
优势
RAG系统提供了几个优势,使它们成为架构师工具箱中的有力工具:
·实时信息检索: 通过集成外部知识源,RAG系统可以访问最新的信息,确保回应是当前和相关的。
·增强的准确性: 检索器组件允许精确的数据获取,减少错误并提高事实准确性。
·上下文相关性: 动态结合知识库中的上下文产生更连贯和上下文适当的输出。
·可扩展性: RAG架构可以扩展以处理大量数据和查询,适合企业级应用。
权衡
尽管RAG系统功能强大,但它们也带来了架构师需要考虑的某些权衡:
·复杂性: 集成多个组件(检索器、生成器、知识库)增加了系统复杂性,需要仔细设计和维护。
·延迟: 实时数据检索可能会引入延迟,可能影响响应时间。优化每个组件对于最小化延迟至关重要。
·资源密集型: 需要强大的基础设施来支持向量数据库和大型语言模型,导致更高的计算成本。
·数据隐私: 在实时检索中处理敏感信息提出了必须用严格的安全协议管理的隐私问题。
结论
RAG系统通过将实时信息检索与强大的语言生成无缝集成,代表了AI架构的重大进步。这种结合允许更准确、相关和上下文感知的回应,使RAG成为架构师在现代数据环境中导航复杂性的宝贵工具。随着我们继续探索和完善这些系统,AI驱动应用的创新潜力是巨大的。未来的开发可能专注于提高效率和隐私,为更广泛的行业采用铺平道路。RAG系统不仅仅是一种趋势;它们是迈向更智能、更实时的AI解决方案的关键一步。
原文链接:https://dzone.com/articles/rag-systems-a-brand-new-architecture-tool
-
生成器
+关注
关注
7文章
322浏览量
22843 -
检索
+关注
关注
0文章
27浏览量
13440 -
系统
+关注
关注
1文章
1048浏览量
22430
原文标题:RAG系统:用大模型赋能实时信息检索
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RAG效果不佳的常见问题与优化思路
高质量RAG系统的五个核心设计要点
这个电路干啥用的呢?它的工作原理是怎么样?
433M无线模块的工作原理和距离
RAG、MCP与智能体:大模型落地的三道关
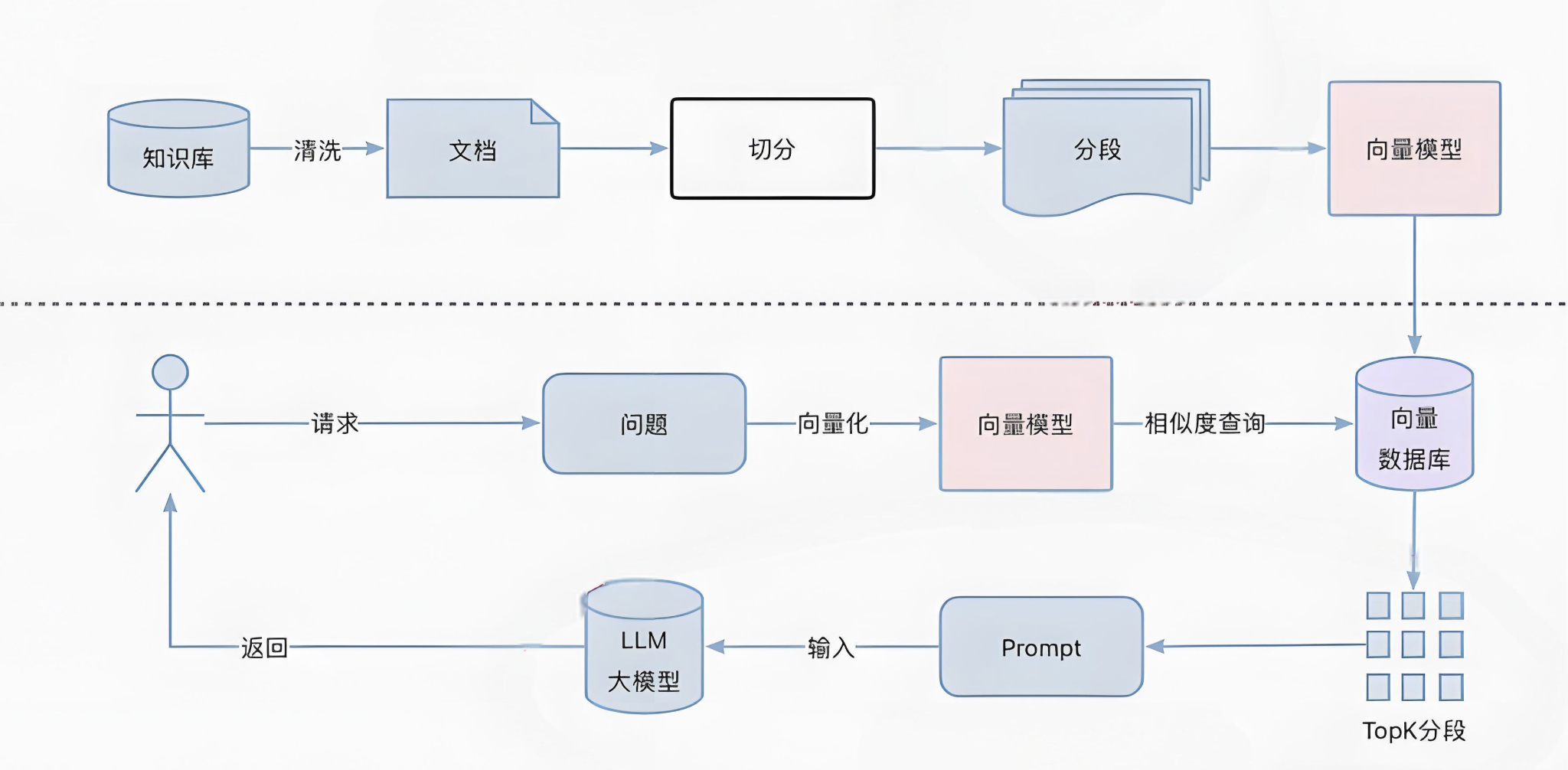
RAG(检索增强生成)原理与实践

RAG实践:一文掌握大模型RAG过程
解析基带和射频的工作原理
使用 llm-agent-rag-llamaindex 笔记本时收到的 NPU 错误怎么解决?
语音控制模块工作原理

软通动力发布智慧园区RAG解决方案
FLASH的工作原理与应用




评论