 在边缘设备上设计和部署深度神经网络的实用框架
在边缘设备上设计和部署深度神经网络的实用框架

机器学习和深度学习应用程序正越来越多地从云端转移到靠近数据源头的嵌入式设备。随着边缘计算市场的快速扩张,多种因素正在推动边缘人工智能的增长,包括可扩展性、对实时人工智能应用的不断增长的需求,以及由强大而高效的软件工具链补充的低成本边缘设备的可用性。此外,需要避免通过网络传输数据——无论是出于安全原因还是仅仅为了尽量减少通信成本。
边缘人工智能涵盖广泛的设备、传感器、微控制器、片上多微处理器、应用处理器和专用片上系统——包括相对强大的边缘服务器和物联网模块。参考社区,TinyML 基金会,成立于 2019 年,专注于开发机器学习模型并将其部署在内存、处理能力和能耗预算有限的资源极其受限的嵌入式设备上。TinyML 开辟了独特的机会,包括可使用廉价电池甚至小型太阳能电池板供电的应用程序,以及在低成本硬件上本地处理数据的大规模应用程序。当然,TinyML 也带来了各种挑战。其中一个挑战是机器学习和嵌入式系统开发人员必须优化应用程序的性能和占用空间,这需要熟练掌握人工智能和嵌入式系统。
在这样的背景下,本文介绍了一种在边缘设备上设计和部署深度神经网络的实用框架。该框架基于 MATLAB 和 Simulink 产品,以及 STMicroelectronics Edge AI 工具,可帮助团队快速提升深度学习和边缘部署方面的专业知识,使他们能够克服使用 TinyML 时遇到的常见障碍。这反过来又使他们能够快速构建和基准测试概念验证 TinyML 应用程序。在工作流程的第一步中,团队使用 MATLAB 构建深度学习网络,使用贝叶斯优化调整超参数,使用知识提炼,并使用修剪和量化压缩网络。最后一步,开发人员使用集成到 ST Edge AI Developer Cloud—一项免费的在线服务,用于在 STMicroelectronics 32 位 (STM32、Stellar) 微控制器和微处理器(包括配备集成 AI 的传感器)上开发 AI,以对已部署的深度学习网络的资源利用率和推理速度进行基准测试(图 1)。
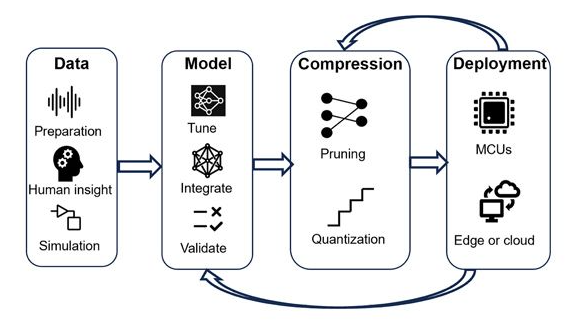
图 1. 将深度学习网络部署到微控制器和边缘设备的迭代工作流程。反馈回路有助于形成更精确、更微小的模型。
▼
网络设计、训练和超参数优化
一旦工程师收集、预处理并准备好用于深度学习应用程序的数据集,下一步就是训练和评估候选模型,其中可以包括预训练模型,例如 NASNet、SqueezeNet、Inception-v3 和 ResNet-101,或者机器学习工程师使用深度网络设计器(图 2)。多个模型提供了可用于快速启动开发的示例,包括以下示例模型:图像,视频,声音 和激光雷达点云分类;物体检测;姿势估计;和波形分割。
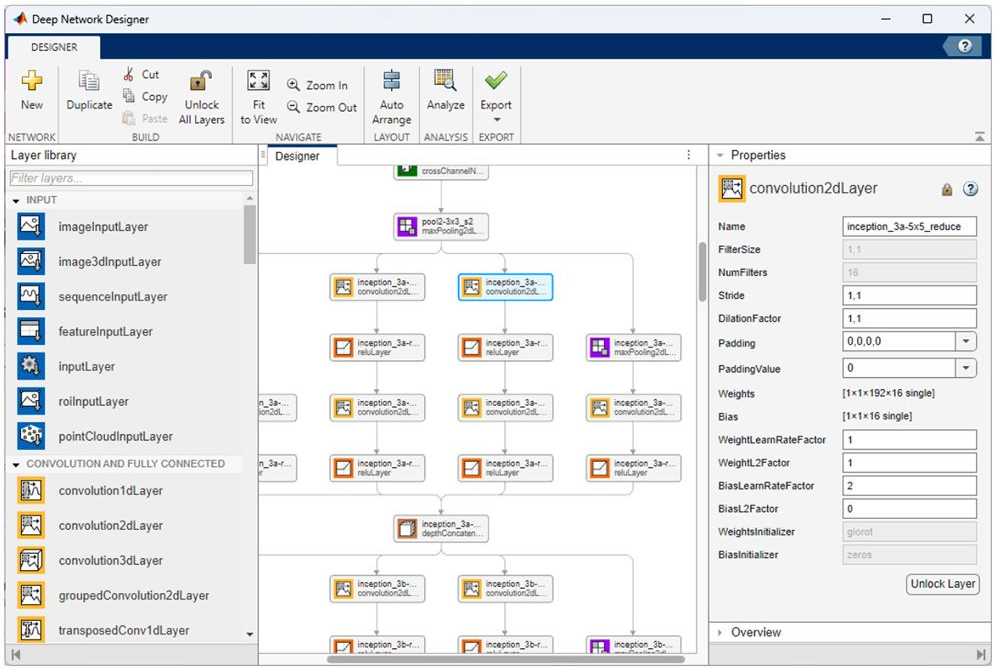
图 2. 深度网络设计器在设计器面板中显示网络的多层。
深度学习网络的性能在很大程度上取决于控制其训练的参数和描述其网络架构的参数。这些超参数示例包括学习率和批量大小,以及层数、层的类型以及层之间的连接。适当的超参数调整可以使模型实现更高的准确性和更好的性能,即使在 TinyML 应用程序运行的资源受限的环境中也是如此。然而,选择和微调超参数值以找到优化性能的组合可能是一项困难且耗时的任务。
贝叶斯优化非常适合分类和回归深度学习网络的超参数优化,因为它可以有效地探索高维超参数空间以找到最佳或接近最佳的配置。在 MATLAB 中,机器学习开发人员可以使用 bayesopt 函数使用贝叶斯优化来找到最佳超参数值。例如,它可以提供一组要评估的超参数(例如卷积层的数量、初始学习率、动量和 L2 正则化)以及要最小化的目标函数(例如验证误差)。然后该函数可以使用 bayesopt 选择一组或多组超参数配置,以便在工作流程的下一阶段进一步探索。
▼
知识提炼
资源受限的嵌入式设备可用内存有限。知识提炼是一种减少深度学习网络占用空间同时保持高精度的方法。该技术使用更大、更准确的教师网络来教更小的学生网络进行预测。关键在于师生网络架构中的损失函数的选择。
在前面的步骤中训练的网络可以用作教师模型。学生网络是教师模型的较小但相似的版本。通常,学生模型包含较少的 convolution-batchnorm-ReLU 模块。为了考虑降维,在学生网络中添加了最大池化层或全局平均池化层。与教师网络相比,这些修改显著减少了可学习内容的数量。
必须定义知识提炼损失函数来训练学生网络。它由学生网络、教师网络的输入、具有对应目标的输入数据和温度超参数确定。从经验上讲,损失函数由以下两项的加权平均值组成:1)硬损失,即学生网络输出与真实标签之间的交叉熵损失;2)软损失,即学生网络日志与教师网络日志之间带温度的 SoftMax 的交叉熵损失。
训练后的学生网络更好地保留了教师网络的准确性,并减少了可学习参数,使其更适合部署到嵌入式设备中。
▼
模型压缩与优化
训练阶段的有效设计和超参数优化是必不可少的第一步;然而,这还不足以确保在边缘设备上的部署。因此,通过模型修剪和量化进行训练后优化对于进一步减少深度神经网络的内存占用和计算要求非常重要。
网络压缩最有效的方法之一是量化。这是因为没有大容量传感器输出浮点表示,所以数据是以整数精度获取的。通过量化,目标是通过减少存储网络参数所需的内存占用,并通过用更少的位数表示模型的权重和激活来提高计算速度。例如,这可能涉及用 8 位整数替换 32 位浮点数——同样,当可能这样做时,仅接受预测准确度的轻微下降。量化可以节约使用嵌入式内存,这对于边缘资源受限的传感器、微控制器和微处理器(图 3)至关重要。此外,整数运算在硬件上通常比浮点运算更快,从而提高微控制器的推理性能。这使得模型消耗的电量更少,使其更适合部署在电池供电或能源受限的设备上,例如移动电话和物联网设备。虽然训练后量化可能会引入一些精度损失,MATLAB 中的量化工具旨在最大限度地减少对模型精度的影响。采用微调、校准等技术来保持量化模型的性能。在 MATLAB 中,dlquantizer 函数简化了将深度神经网络的权重、偏差和激活量化为 8 位整数值的过程。
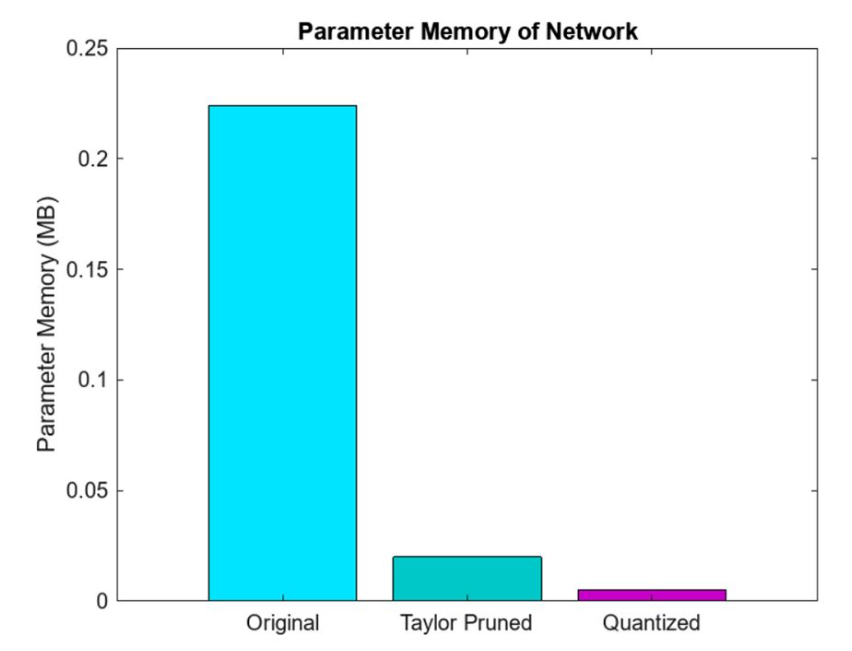
图 3. MATLAB修剪和量化后深度神经网络的内存占用。
相比之下,修剪技术侧重于通过最小化操作冗余来降低网络的复杂性。这对于大幅降低计算复杂性至关重要。其目的是识别并删除那些对网络预测影响不大的连接、权重、过滤器甚至整个层。投影是 MATLAB 的专有技术,用于通过有选择地删除不太重要的权重或连接来优化神经网络。此过程降低了模型的复杂性,从而减小了模型尺寸并加快了推理时间,同时又不会显著影响性能。虽然常规修剪通常涉及直接基于阈值去除低幅度权重,但投影可能采用更复杂的标准和方法来确保网络的基本特征得到保留。此外,投影通常旨在维持权重空间的几何特性,与传统修剪方法相比,可能产生更高效、更稳健的模型。
▼
ST Edge AI Developer Cloud 基准测试
在 MATLAB 中完成初始网络设计、超参数优化、提炼和压缩后,工作流程的下一步是在微控制器或微处理器上评估该设计的性能。具体来说,工程师需要评估网络的闪存和 RAM 要求以及推理速度等因素。
ST Edge AI Developer Cloud 旨在通过对 ST Edge 设备上的网络进行快速基准测试来简化工作流程的这一阶段。要将此服务用于在 MATLAB 中开发的 TinyML 应用程序,您首先需将网络导出为 ONNX 格式。将生成的 ONNX 文件上传到 ST Edge AI Developer Cloud 后,工程师可以选择要在其上运行基准测试的 ST 设备(图 4)。
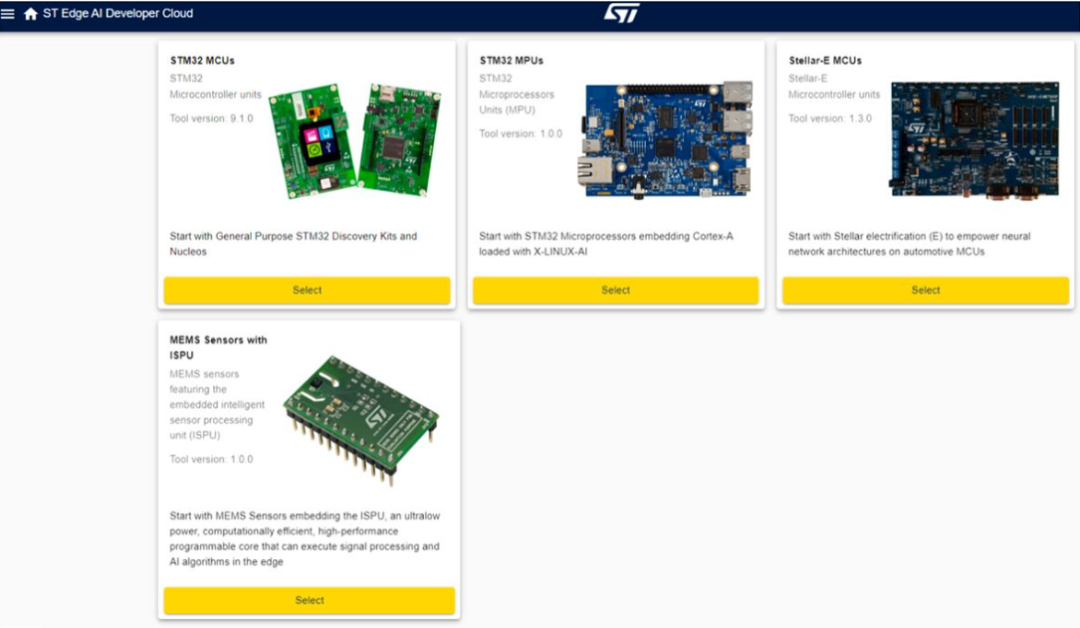
图 4. 可在 ST Edge AI Developer Cloud 用户界面中进行基准测试的设备。
基准测试完成后,ST Edge AI Developer Cloud 会提供一份详细说明结果的报告(图 5)。ST Edge AI Developer Cloud 提供的性能分析工具提供了各种详细的见解,包括内存使用情况、处理速度、资源利用率和模型准确性。开发人员会收到有关 RAM 和闪存消耗的信息,以及模型不同层和组件的内存分配细目。此外,这些工具还提供每一层的执行时间和总体推理时间,以及详细的时序分析以识别和优化缓慢的操作。资源利用率统计数据(包括 CPU 和硬件加速器使用情况以及功耗指标)有助于优化能源效率。
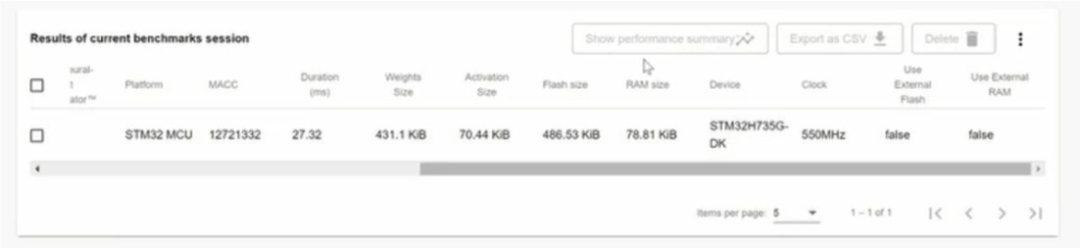
图 5. ST Edge AI Developer Cloud 中典型基准测试会话的结果。
通过审查基准测试结果,工程师可以确定下一步的最佳行动方案。如果网络设计能够轻松地适应具有较低推理时间的给定边缘设备的约束,他们可能会探索使用更小的设备或使用更大、更复杂的网络来提高预测准确性的机会。另一方面,如果网络设计太大,由于使用外部 Flash 或 RAM 而导致推理时间变慢,那么团队可能会寻找具有更多嵌入式 Flash 和 RAM 的计算能力更强大的设备,或者他们可能会使用 MATLAB 执行额外的超参数优化、知识提炼、修剪和量化迭代以进一步压缩网络。ST Edge AI Developer Cloud 还提供自动代码生成,以简化在 ST 设备上部署 AI 模型。该功能将训练有素的 AI 模型转换为与 STMicroelectronics 的传感器、微控制器和微处理器兼容的优化 C 代码。
▼
从基准测试到部署
工作流程的最后一步是部署到传感器、微控制器或微处理器。有了基准测试结果,工程师们就可以做出明智的决定,选择一个平台,比如 STM32 Discovery Kit,在真实硬件上评估他们的 TinyML 应用程序。根据应用情况,他们可能需要将深度神经网络与其他组件(例如控制器)集成,并在部署之前将其合并到更大的系统中。对于这些用例,他们可以进一步扩展工作流程,在 Simulink 中对其他组件进行建模,运行系统级仿真以验证设计,并使用 Embedded Coder 和 Embedded Coder Support Package for STMicroelectronics STM32 Processors 生成 C/C++ 代码以部署到 STM32 设备。
◆ ◆ ◆ ◆
-
matlab
+关注
关注
189文章
3032浏览量
239447 -
神经网络
+关注
关注
42文章
4845浏览量
108326 -
机器学习
+关注
关注
67文章
8570浏览量
137381
原文标题:MathWorks × STMicroelectronics | 在边缘设备上快速部署深度学习
文章出处:【微信号:MATLAB,微信公众号:MATLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深度神经网络是什么
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别
轻量化神经网络的相关资料下载
基于深度神经网络的激光雷达物体识别系统
卷积神经网络模型发展及应用
如何使用TensorFlow将神经网络模型部署到移动或嵌入式设备上
基于虚拟化的多GPU深度神经网络训练框架
在Arduino Nano BLE Sense 33边缘设备上训练神经网络




评论