 利用Arm Kleidi技术实现PyTorch优化
利用Arm Kleidi技术实现PyTorch优化

作者:Arm 基础设施事业部高级产品经理 Ashok Bhat
PyTorch 是一个广泛应用的开源机器学习 (ML) 库。近年来,Arm 与合作伙伴通力协作,持续改进 PyTorch 的推理性能。本文将详细介绍如何利用 Arm Kleidi 技术提升 Arm Neoverse 平台上的 PyTorch 推理表现。Kleidi 技术可以通过 Arm Compute Library (ACL) 和 KleidiAI 库获取。
PyTorch 提供两种主要的执行模式:即时执行模式 (Eager Mode) 和图模式 (Graph Mode)。即时执行模式是一种动态执行模式,操作会以 Python 代码编写的方式立即执行,该模式非常适用于实验与调试。而图模式则是在执行前将一系列 PyTorch 操作编译成静态计算图,从而实现性能优化和高效的硬件加速。通过使用 torch.compile 函数,可以方便地将 PyTorch 代码转换为图模式,通常能够显著提升执行速度。
PyTorch 即时执行模式
CPU 推理性能提升高达三倍
PyTorch 即时执行模式使用 oneDNN,针对具有 ACL 内核的 Arm Neoverse 处理器进行了优化。可以通过以下的 PyTorch 软件栈图进行了解。
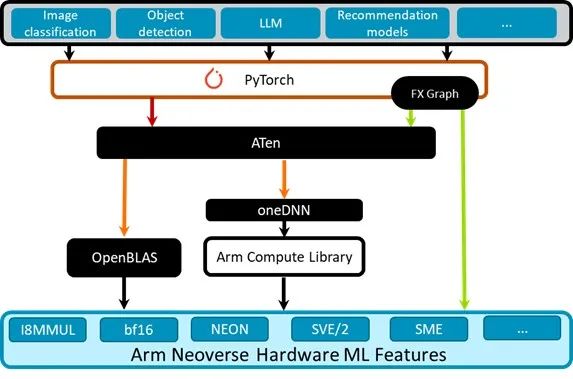
图 1:PyTorch 软件栈
PyTorch 中的 FX Graph 是用于可视化和优化 PyTorch 模型的一种中间表示形式。
ATen 是支撑 PyTorch 框架的基础张量库。它提供了核心张量类别和大量数学运算,构成了 PyTorch 模型的基本组件。
oneDNN 是一个性能库,为包括 Arm 和 x86 在内的各种硬件架构提供常见深度学习原语的优化实现方案。在这些架构上,ATen 使用 oneDNN 作为性能增强后端。这意味着当 PyTorch 遇到支持的操作时,会将计算委托给 oneDNN,后者可以使用针对特定硬件的优化来提高执行效率。
Arm Compute Library 于 2016 年首次发布,提供针对 Arm 进行优化的关键 ML 原语,包括卷积、池化、激活函数、全连接层、归一化。这些原语利用 Arm Neoverse 核心上针对特定 ML 和特定硬件的功能和指令来实现高性能。我们已将 Arm Compute Library 集成到 oneDNN 中,以便在 Arm 平台上加速 ATen 操作。
Arm Neoverse CPU 包含有助于加速 ML 的硬件扩展,其中包括 Neon、SVE/SVE2、BF16 和 I8MM,通过有效地进行向量处理、BF16 运算和矩阵乘法来加速 ML 任务。
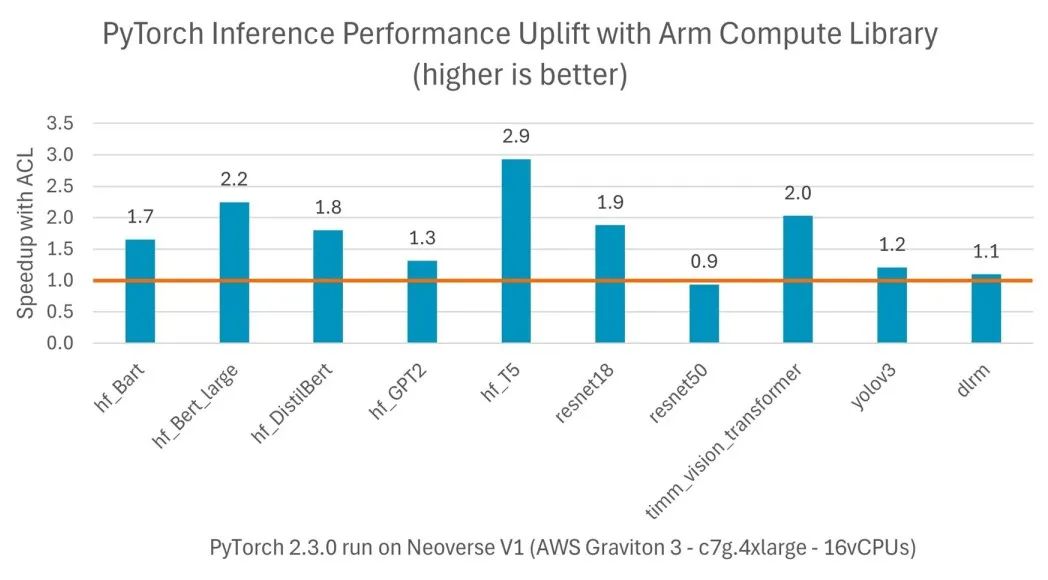
图 2:各种模型在即时执行模式下实现的性能提升
PyTorch 图模式(使用 torch.compile)
比 PyTorch 即时执行模式进一步提高两倍
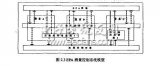
PyTorch 2.0 引入了 torch.compile,与默认的即时执行模式相比,可提高 PyTorch 代码的速度。与即时执行模式不同,torch.compile 将整个模型预编译成针对特定硬件平台优化的单图。从 PyTorch 2.3.1 开始,官方 AArch64 安装包均包含 torch.compile 优化。在基于亚马逊云科技 (AWS) Graviton3 的 Amazon EC2 实例上,对于各种自然语言处理 (NLP)、计算机视觉 (CV) 和推荐模型,这些优化可以为 TorchBench 模型推理带来比即时执行模式高出两倍的性能。
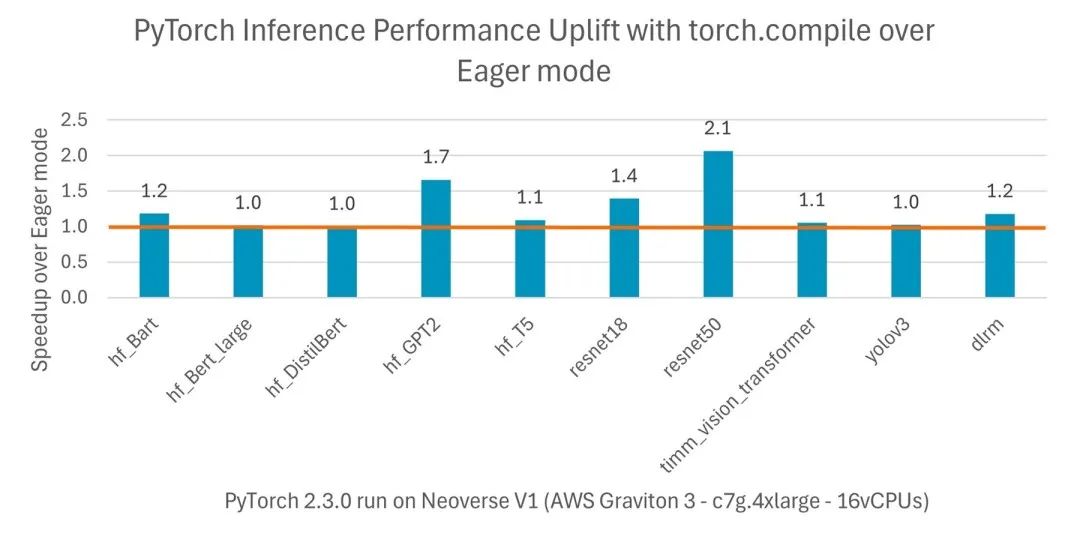
图 3:各种模型在编译模式下实现的性能提升
下一步通过 KleidiAI 库
提升生成式 AI 推理性能
目前,我们已经研究了 Arm Compute Library 如何在即时执行模式和编译模式下提升 PyTorch 推理性能。接下来,我们来看 PyTorch 即将推出什么新功能。Arm 目前正在努力提升 PyTorch 中的大语言模型 (LLM) 推理性能,并以 Llama 和 Gemma 为主要 LLM 示例。
经优化的 INT4 内核
今年早些时候,Arm 软件团队和合作伙伴共同优化了 llama.cpp 中的 INT4 和 INT8 内核,以利用更新的 DOT 和 MLA 指令。在 AWS Graviton3 处理器上,这些内核在即时评估方面比现有 GEMM MMLA 内核提升了 2.5 倍,并且在文本生成方面比默认的 vec_dot 内核提升了两倍。这些经优化的新内核也是 Arm KleidAI 库的一部分。
今年早些发布的 KleidiAI 库是一个开源库,具有针对 Arm CPU 上的 AI 任务进行优化的微内核。对于微内核,可将它视为能够提升特定 ML 操作性能的软件。开发者可以通过包含相关的 .c 和 .h 文件及公共头文件来使用这些微内核。无需包含库的其余部分。
Kleidi 与 PyTorch 的集成
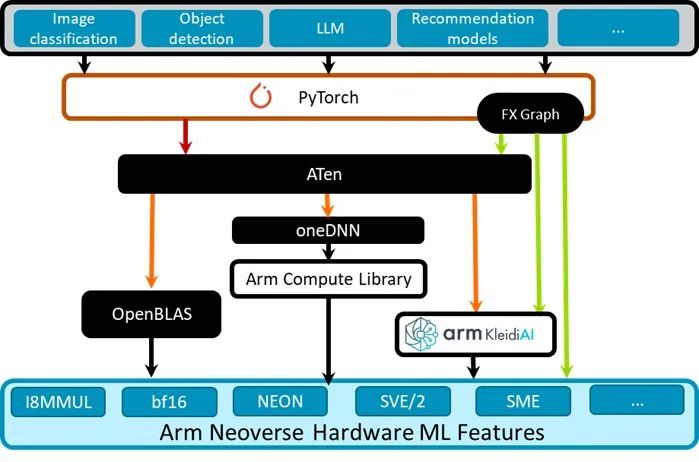
图 4:Kleidi 技术与 PyTorch 的集成
我们引入了两种新的 ATen 操作:torch.ops.aten._kai_weights_pack_int4() 和 torch.ops.aten._kai_input_quant_mm_int4(),两者均使用 KleidiAI 库中高度优化的打包技术和 GEMM 内核。gpt-fast 利用这些 PyTorch 算子来 (1) 使用对称的每通道量化将权重量化为 INT4,并添加包含量化尺度的额外数组;(2) 动态量化激活矩阵并使用 AArch64 I8MM 扩展来执行激活矩阵和权重的 INT8 矩阵乘法。
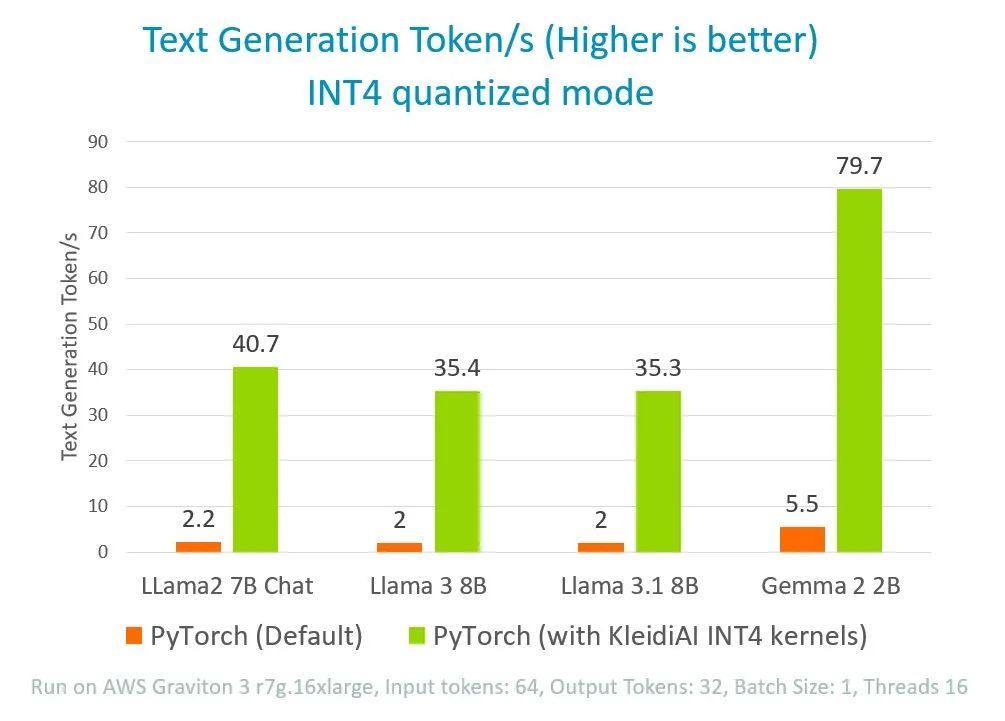
图 5:通过在 PyTorch 中集成 KleidiAI
来提升 4 位量化 LLM 模型性能
通过这种方法,与目前默认的 PyTorch 实现方案相比,我们可以将 Llama 的推理性能提高 18 倍,将 Gemma 的推理性能提高 14 倍。
结论
Arm 及其合作伙伴利用 Arm Compute Library 中的 Kleidi 技术提高了 Arm Neoverse 平台上的 PyTorch 推理性能。在即时执行模式下可实现高达两倍的性能提升,在图模式下(使用 torch.compile)可再提升两倍。此外,我们还在努力将生成式 AI 模型(Llama 和 Gemma)的推理性能提升高达 18 倍。
Arm 通过部署 Kleidi 技术来实现PyTorch 上的优化,以加速在基于 Arm 架构的处理器上运行 LLM 的性能。Arm 技术专家在基于 Neoverse V2 的 AWS Graviton4 R8g.4xlarge EC2 实例上运行 Llama 3.1 展示了所实现的性能提升。如果你对这一演示感兴趣,可阅读《Arm KleidiAI 助力提升 PyTorch 上 LLM 推理性能》了解。
-
ARM
+关注
关注
135文章
9611浏览量
394274 -
cpu
+关注
关注
68文章
11370浏览量
226360 -
机器学习
+关注
关注
67文章
8570浏览量
137408 -
pytorch
+关注
关注
2文章
813浏览量
14950 -
Neoverse
+关注
关注
0文章
17浏览量
5003
原文标题:如何在 Arm Neoverse 平台上使用 Kleidi 技术加速 PyTorch 推理?
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Arm KleidiAI助力提升PyTorch上LLM推理性能
ARM程序设计优化策略与技术
Pytorch模型训练实用PDF教程【中文】
在Ubuntu 18.04 for Arm上运行的TensorFlow和PyTorch的Docker映像
解读最佳实践:倚天 710 ARM 芯片的 Python+AI 算力优化

Arm推出AI优化的Arm终端CSS以及新的Arm Kleidi软件




评论