 首个科学计算基座大模型BBT-Neutron开源,助力突破大科学装置数据分析瓶颈
首个科学计算基座大模型BBT-Neutron开源,助力突破大科学装置数据分析瓶颈
大语言模型能否解决传统大语言模型在大规模数值数据分析中的局限性问题,助力科学界大科学装置设计、高能物理领域科学计算?
高能物理是探索宇宙基本组成与规律的前沿科学领域,研究粒子在极高能量下的相互作用,是揭示宇宙起源、暗物质与暗能量等未解之谜的重要手段。高能物理实验(如粒子对撞实验、暗物质与暗能量实验等)产生的数据量极为庞大且复杂,传统的数据分析方法在处理海量数据和复杂物理结构时,面临计算瓶颈。
2024年12月3日,arxiv上更新了一篇将多模态基座大模型运用于粒子物理科研场景的最新论文《Scaling Particle Collision Data Analysis》,从粒子对撞实验出发,探索了大语言模型在大科学装置数据分析与科学计算领域的全新应用场景。作者团队来自超越对称(上海)技术有限公司,与中国高能物理研究所(高能所)大对撞机CEPC团队、北京大学等机构的研究人员合作,将其最新研发的科学基座大模型BBT-Neutron应用于粒子对撞实验。模型应用了全新的二进制分词方法(Binary Tokenization),可实现对多模态数据(包括大规模数值实验数据、文本和图像数据)的混合预训练。
论文链接:https://arxiv.org/abs/2412.00129
代码地址:https://github.com/supersymmetry-technologies/bbt-neutron
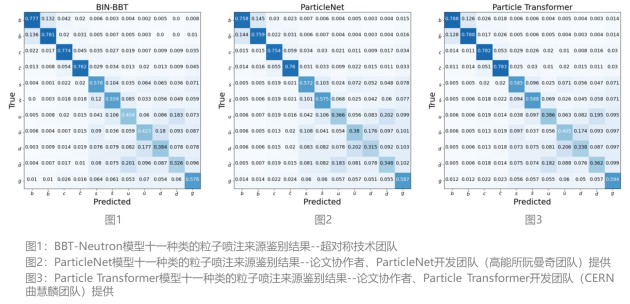
论文中对比了BBT-Neutron的通用架构模型与最先进的专业JoI模型(如ParticleNet和Particle Transformer)在粒子物理领域的Jet Origin Identification(JoI)分类任务上的实验结果。粒子分类的识别准确率(图1-3)表明,研究表明该通用架构的性能与专业模型持平,这也验证了基于sequence-to-sequence建模的decoder-only架构在学习物理规律方面的能力。
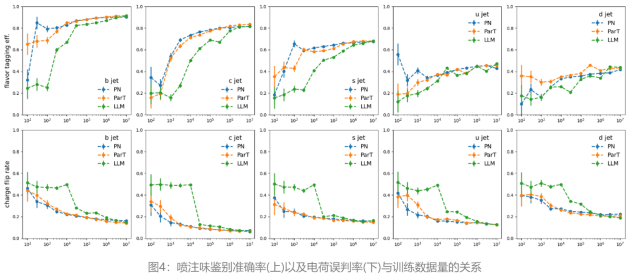
这些模型在数据集大小扩展时都显示出性能提升,Jet Flavor Tagging Efficiency, Charge Flip Rate形成了S曲线。然而,BBT-Neutron和专业模型之间观察到不同的扩展行为,S曲线上的关键数据阈值表明BBT-Neutron中出现了涌现现象(在专业架构中未出现),不仅打破了传统观念认为该架构不适用于连续性物理特征建模的局限,更验证了通用模型在大规模科学计算任务中的可扩展性。
二进制分词:统一多模态数据处理,突破数值数据分析瓶颈
近年来大语言模型在文本处理、常识问答等任务上取得了显著进展,但在处理大规模数值数据方面依然面临挑战。传统的BPE分词方法在分词数字时可能会引入歧义和不一致,特别是在高能物理、天文观测等领域,分析复杂的实验数据成为瓶颈。
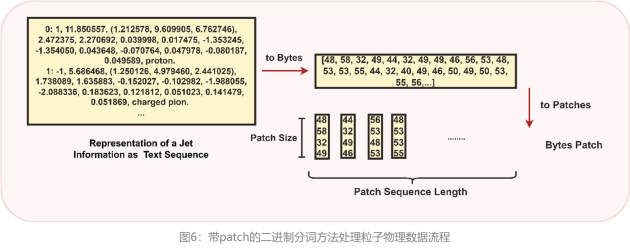
为了让大模型更加适配科学计算场景,该研究通过引入一种创新的二进制分词方法(Binary Tokenization),即利用计算机存储中使用的二进制表示数据,实现了数值数据与文本、图像等多模态数据的统一表示。以使其能够在无需额外预处理的情况下,通过二进制分词,实现对所有数据类型的统一处理,简化预处理流程,确保输入数据的一致性。研发团队在论文中详细展示了如何克服传统BPE方法的局限性及其数据处理过程。
BPE方法的局限性
歧义和不一致性
BPE是一种基于频率的token 化方法,它会根据上下文将数字分割成不同的子单元,这可能导致同一数字在不同上下文中有不同的分割方式。
例如,数字12345在一个上下文中可能被分割成‘12’、‘34’和‘5’,在另一个上下文中可能被分割成‘1’、‘23’和‘45’。这种分割方式丢失了原始数值的固有意义,因为数字的完整性和数值关系被破坏了。
token ID的不连续性
BPE会导致数值的token ID不连续。例如,数字‘7’和‘8’的token ID可能被分配为4779和5014。
这种不连续性使得管理和处理数值数据变得更加复杂,特别是在需要顺序或模式化的token ID时,这种不连续性会影响模型处理和分析数值数据的能力。
单数字token化的问题
尽管单数字token 化方法简单直接,但它也会导致多位数数字的token ID不连续。例如,数字15可能会被分解为独立的token ‘1’和‘5’,每个token 都被映射到独立的token ID。这种分割可能会破坏数值信息的连续性,使得模型更难捕捉多位数数字内在的结构和关系。
数值处理方式
对于文本数据,使用UTF-8编码将字符转换为字节序列。
对于数值数据,提供了双重策略:一种是当保留数字的确切格式和任何可能重要的前导零时,数字被视为字符串,然后使用UTF-8编码;另一种是在进行算术运算或处理重要数值时,数字被转换成其数值形式(例如,整数),然后转换成字节数组。 这种方法保证了模型能够统一且高效地处理各种数据类型。
对于科学公式或符号: 复杂的表达式被解析并序列化成字节序列,捕捉公式的结构和内容。 例如,公式E = mc^2被编码为字节数组[69, 61, 109, 99, 94, 50],代表了公式的结构和变量。
对于图像数据,使用patch方法将图像分解为小块,提高对高密度像素数据的处理效率。
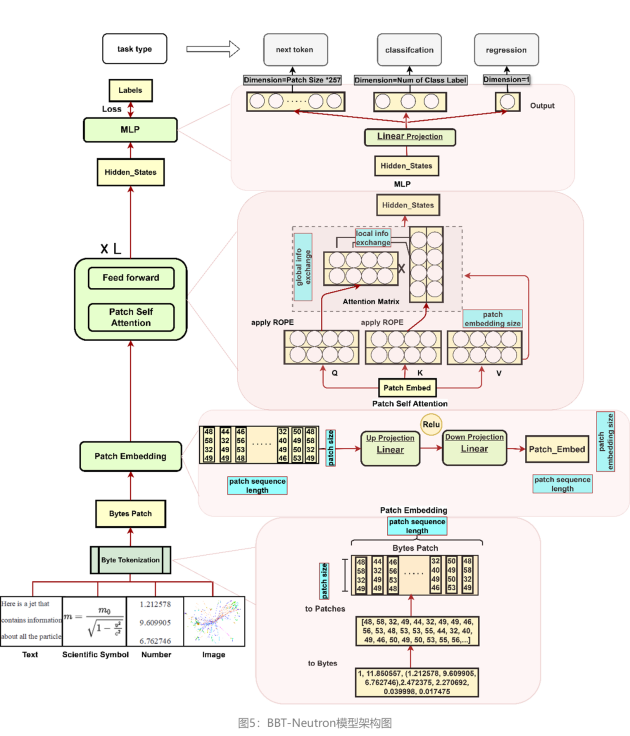
BBT-Neutron模型架构:高效捕获数值关系与多功能任务适配
BBT-Neutron模型架构主要由三个关键部分组成:Patch Embedding、Patch Self-Attention和LM Head,能够将输入序列通过字节分词转换为高维向量,使其具备了包括执行分类、回归任务在内的多种能力。这些任务在许多科学应用中非常常见,目标不一定是生成新序列,也可以是对输入分类或预测连续值。
Patch Embedding
包含两个线性层,第一层将输入patch投影到高维空间,第二层细化这一表示,产生最终的嵌入向量。
两层之间引入ReLU激活函数,使模型能够非线性地表达输入字节patch,捕捉patch内部byte之间更复杂的结构。与通常只使用单一层线性嵌入的字节级模型相比,能够提供更大的灵活性,更好地表示输入patch的细节和非线性关系。
Patch Self-Attention
在patch自注意力机制中,注意力操作在patch层面执行,每个patch嵌入包含其所有点的信息,通过矩阵乘法促进不同patch之间的信息交换,同时促进单个patch内部字节之间的交互,使模型能够有效捕捉局部和全局依赖。
LM Head
输出维度定义为Patch Size × 257,其中257代表从0到255的字节值总数,加上由256表示的填充ID,Patch Size是文本序列被划分的patch数量。这种设计允许模型独立地为每个patch生成预测,保持基于patch方法的效率和有效性。
应用于粒子物理对撞数据分析:通用架构性能达到专业领域的SOTA
开发团队在论文中分享了BBT-Neutron通用架构的首次落地实验结果,辅助粒子物理学中的关键任务——喷注来源识别(Jet Origin Identification, JoI),并已取得了突破性成果。
喷注来源识别是高能物理实验中的核心挑战之一,旨在区分来自不同夸克或胶子的喷注。在高能碰撞中产生的夸克或胶子会立即产生一束粒子——主要是强子——朝同一方向运动。这束粒子通常被称为喷注,是碰撞实验中物理测量的关键对象。识别喷注的起源对于许多物理分析至关重要,尤其是在研究希格斯玻色子、W和Z玻色子时,这些玻色子几乎70%会直接衰变为两个喷注。此外,喷注是我们理解量子色动力学(QCD,描述原子核、质子、中子、夸克的相互作用机制)的基础。来自不同类型色荷粒子的喷注在它们的可观测量上只有微小的差异,这使得准确识别喷注的起源极具挑战性。
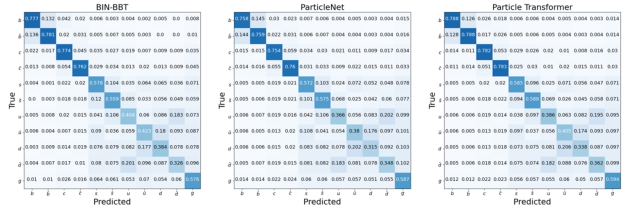
实验结果显示,该研究与最先进的专业模型(如Particle Transformer和ParticleNet,将专业物理定律融入GNN架构设计)的最佳性能持平,达到行业的SOTA(图1-3)。这个结果验证了以sequence to sequence建模方式为基础的decoder only通用架构,在学习物质世界和物理规律上具备与专业模型同等的学习能力。而传统的观念认为,seq2seq 建模不适用于时间、空间、能量等具有连续性特征的物理实在建模,只适合于人类语言这样的离散符号的建模。而且从左到右具有位置特性的学习方式,不适用于具有时空对称性的物理结构,要让模型学习专业物理定律,需要在专业模型架构中融入该领域相关结构。该论文研究的成果证明了这种观念的局限性,为表征时间、空间、能量等基础的物理量提供了一种有效方案,同时也为物理化学等专业科学领域构建一个统一模型提供了基础。
Scaling分析:发现涌现行为
文中通过与ParticleNet和Particle Transformer在JoI任务上的扩展行为的方式进行对比,在数据规模增加下的Scaling行为进行了深入分析。这些训练数据集从100到1000万事件不等,实验结果通过混淆矩阵(confusion matrix)、喷注风味标记效率(jet flavor tagging efficiency)和电荷翻转率(charge flip rate)这三个关键指标来衡量模型的表现。
混淆矩阵(Confusion Matrix)即使用了一个11维的混淆矩阵M11来分类每个喷注,根据最高预测分数归类到相应的类别, 块对角化成2×2的块,每个块对应特定的夸克种类。混淆矩阵提供了模型分类性能的全面概览,突出显示了在各种喷注类别中正确和错误预测的情况。
喷注味标记效率(Jet Flavor Tagging Efficiency)定义为每个块内值的总和的一半,不区分由夸克和反夸克产生的喷注。
电荷翻转率(Charge Flip Rate)定义为块中非对角线元素与块总和的比率,代表误识别夸克和反夸克产生的喷注的概率。
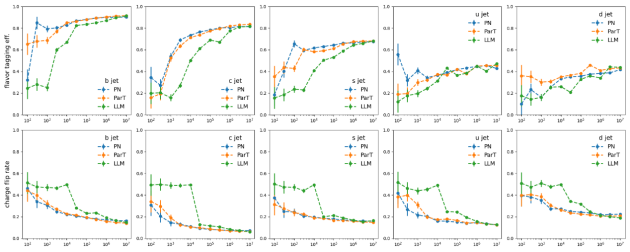
图4显示,这些模型在十一种类的粒子喷注来源鉴别的分类问题上表现出相似的性能,并且在数据集大小扩展时都显示出性能提升,Jet Flavor Tagging Efficiency, Charge Flip Rate形成了S曲线。
开发团队指出,该模型和专业模型之间出现了不同的扩展行为。BBT-Neutron的S曲线上的关键数据阈值,特别是Charge Flip Rate的数据发生到了性能突变,表现出显著的涌现现象(Model Emergence),然而该现象在ParticleNet或Particle Transformer中并没有被观察到。
可能的原因是这些专业模型纳入了特定领域的结构特征,它们采用专门设计的架构来表示粒子相互作用和分类,这可能导致随着数据规模的增加,性能提升更快达到饱和。与此相反,研究中的通用架构模型,使用统一的数据表示来处理所有物理结构。专业模型架构通过消除位置编码或相关操作来实现粒子的置换不变性(permutative invariance),BBT-Neutron不依赖置换不变性,而是采用从左到右的序列输入,这与语言模型的seq2seq范式一致。虽然这种方法需要更大的数据集来推断,但一旦超过临界数据集阈值,它就能实现显著的性能飞跃,这表明了该模型即使没有像专业模型那样明确在架构设计中纳入置换不变性,也能够通过足量数据的学习学到空间对称性。
通俗而言,当数据规模逐步增加时,该模型在性能上出现了显著跃迁。这一发现验证了通用模型在大规模科学计算任务中的可扩展性,即该模型有望成为跨领域的科学计算基座模型。
该论文研究标志着大模型在多模态数据处理与科学计算任务中的巨大潜力。随着人工智能技术与大科学装置的深度融合,在未来或许能够加速中国大对撞机CEPC等前沿科研项目的实施落地。该项目参与者、CEPC团队成员阮曼奇曾评论道,“人工智能技术将助力大科学设施的设计研发,能大幅提高其科学发现能力,更好地帮助我们探索世界的奥秘、拓宽人类的知识边界。反过来,通过总结对比在具体科学问题上观测到的AI性能差异,也能加深我们对AI技术本身的理解,更好推动AI技术的发展。”
目前BBT-Neutron科学计算基座模型已经落地到粒子物理、核聚变、强磁场、石油化工、储能、钙钛矿太阳能、飞行传感器、基因编辑等真实科研工程难题。
关于超对称技术
超越对称(上海)技术有限公司位于上海市徐汇区漕河泾开发区内,专注于研发跨学科、跨结构、跨尺度的科学基座大模型 BigBangTransformer[乾元],赋能科学计算、工业智能、空间智能、医疗健康等领域,致力于通过大模型技术攻克物理世界的复杂难题,推动人类迈进“Type II 文明“。
BBT模型发展历程
BBT模型历经三代迭代,持续探索大模型的科学应用路径:
2022年:发布BBT-1,10亿参数的金融预训练语言模型;
2023年:推出BBT-2,120亿参数的通用大语言模型;
2024年:发布BBT-Neutron,1.4亿参数的科学基座大语言模型,实现文本、数值和图像数据的多模态统一预训练
审核编辑 黄宇
-
开源
+关注
关注
3文章
3342浏览量
42490 -
数据处理
+关注
关注
0文章
598浏览量
28564 -
数据分析
+关注
关注
2文章
1449浏览量
34056 -
大模型
+关注
关注
2文章
2442浏览量
2691
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论