 传统机器学习方法和应用指导
传统机器学习方法和应用指导
在上一篇文章中,我们介绍了机器学习的关键概念术语。在本文中,我们会介绍传统机器学习的基础知识和多种算法特征,供各位老师选择。
01
传统机器学习
传统机器学习,一般指不基于神经网络的算法,适合用于开发生物学数据的机器学习方法。尽管深度学习(一般指神经网络算法)是一个强大的工具,目前也非常流行,但它的应用领域仍然有限。与深度学习相比,传统方法在给定问题上的开发和测试速度更快。开发深度神经网络的架构并进行训练是一项耗时且计算成本高昂的任务,而传统的支持向量机(SVM)和随机森林等模型则相对简单。此外,在深度神经网络中估计特征重要性(即每个特征对预测的贡献程度)或模型预测的置信度仍然不是一件容易的事。即使使用深度学习模型,通常仍应训练一个传统方法,与基于神经网络的模型进行比较。
传统方法通常期望数据集中的每个样本具有相同数量的特征,但是生物学检测数据很难满足这个需求。举例说明,当使用蛋白质、RNA的表达水平矩阵时,每个样本表达的蛋白质、RNA数量不同。为了使用传统方法处理这些数据,可以通过简单的技术(如填充和窗口化)将数据调整为相同的大小。“填充”意味着将每个样本添加额外的零值,直到它与数据集中最大的样本大小相同。相比之下,窗口化将每个样本缩短到给定的大小(例如,使用在所有样品中均表达的蛋白质、RNA)。
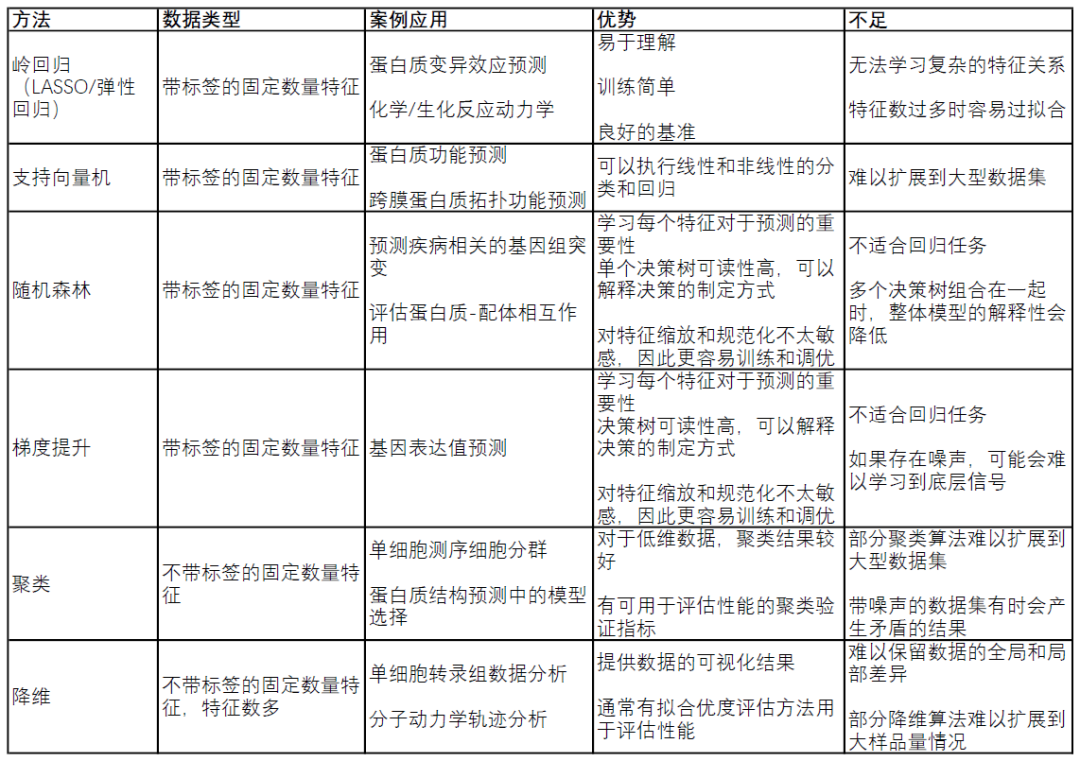
表1. 传统机器学习方法比较
02
回归模型
对于回归问题,岭回归(带有正则化项的线性回归)通常是开发模型的良好起点。因为它可以为给定任务提供快速且易于理解的基准。当希望减少模型依赖的特征数时,比如筛选生物标志物研究时,其他线性回归变体如LASSO回归和弹性网络回归也是值得考虑的。数据中特征之间的关系通常是非线性的,因此在这种情况下使用如支持向量机(SVM)的模型通常是更合适的选择。SVM是一种强大的回归和分类模型,它使用核函数将不可分的问题转换为更容易解决的可分问题。根据使用的核函数,SVM可以用于线性回归和非线性回归。一个开发模型的好方法是训练一个线性SVM和一个带有径向基函数核的SVM(一种通用的非线性SVM),以量化非线性模型是否能带来任何增益。非线性方法可以提供更强大的模型,但代价是难以解释哪些特征在影响模型。
03
分类模型
许多常用的回归模型也用于分类。对于分类任务,训练一个线性SVM和一个带有径向基函数核的SVM也是一个好的默认起点。另一种可以尝试的方法是k近邻分类(KNN)。作为最简单的分类方法之一,KNN提供了与其他更复杂的模型(如SVM)进行比较的有用基线性能指标。另一类强大的非线性方法是基于集成的模型,如随机森林和XGBoost。这两种方法都是强大的非线性模型,具有提供特征重要性估计和通常需要最少超参数调优的优点。由于特征重要性值的分配和决策树结构,这些模型可分析哪些特征对预测贡献最大,这对于生物学理解至关重要。
无论是分类还是回归,许多可用的模型都有令人眼花缭乱的变体。试图预测特定方法是否适合特定问题可能会有误导性,因此采取经验性的试错方法来找到最佳模型是明智的选择。选择最佳方法的一个好策略是训练和优化上述多种方法,并选择在验证集上表现最好的模型,最后再在独立的测试集上比较它们的性能。
04
聚类模型和降维
聚类算法在生物学中广泛应用。k-means是一种强大的通用聚类方法,像许多其他聚类算法一样,需要将聚类的数量设置为超参数。DBSCAN是一种替代方法,不需要预先定义聚类的数量,但需要设置其他超参数。在聚类之前进行降维也可以提高具有大量特征的数据集的性能。
降维技术用于将具有大量属性(或维度)的数据转换为低维形式,同时尽可能保留数据点之间的不同关系。例如,相似的数据点(如两个同源蛋白序列)在低维形式中也应保持相似,而不相似的数据点(如不相关的蛋白序列)应保持不相似。通常选择两维或三维,以便在坐标轴上可视化数据,尽管在机器学习中使用更多维度也有其用途。这些技术包括数据的线性和非线性变换。生物学中常见的例子包括主成分分析(PCA)、均匀流形逼近和投影(UMAP)以及t分布随机邻域嵌入(t-SNE)。
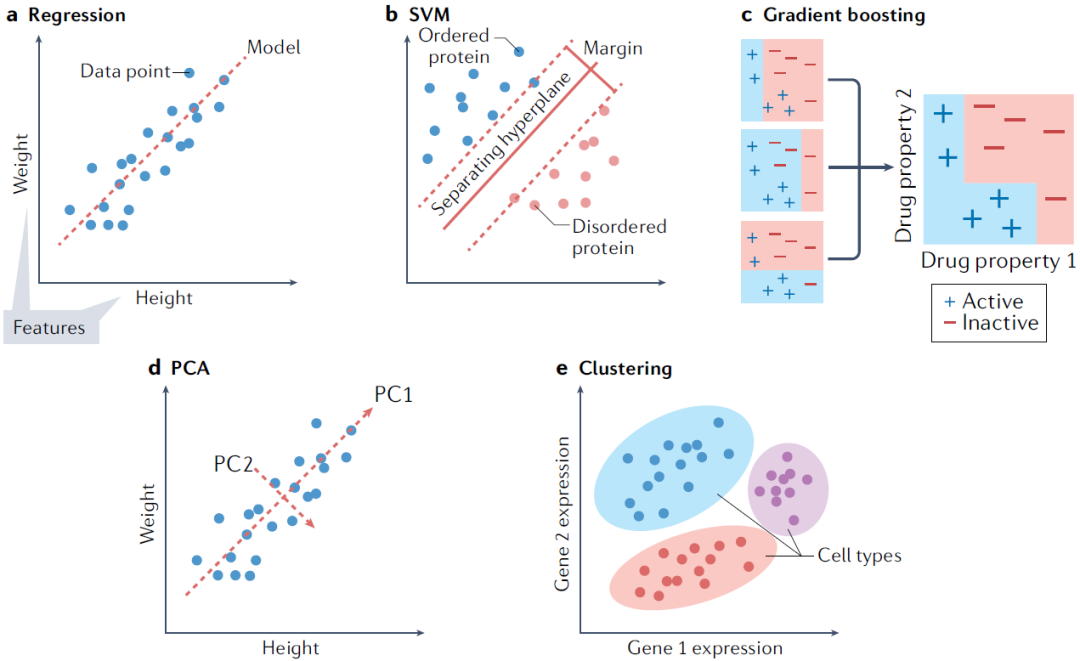
图1. 各种传统机器学习模型
本文详细介绍了传统机器学习方法和应用指导,下一篇文章将介绍深度神经网络算法模型,敬请期待。
-
神经网络
+关注
关注
42文章
4789浏览量
101549 -
机器学习
+关注
关注
66文章
8460浏览量
133387
原文标题:生物学家的机器学习指南(三)
文章出处:【微信号:SBCNECB,微信公众号:上海生物芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
DeepSeek与Kimi揭示o1秘密,思维链学习方法显成效
什么是机器学习?通过机器学习方法能解决哪些问题?

NPU与机器学习算法的关系
LLM和传统机器学习的区别
如何使用 PyTorch 进行强化学习
麻省理工学院推出新型机器人训练模型
AI大模型与传统机器学习的区别
【《时间序列与机器学习》阅读体验】+ 了解时间序列
机器学习中的数据分割方法
深度学习中的无监督学习方法综述
人工神经网络与传统机器学习模型的区别
深度学习的基本原理与核心算法
机器人视觉技术中图像分割方法有哪些
深度学习与传统机器学习的对比
机器学习8大调参技巧





 工商网监
工商网监
评论