 微软AI可以根据详细的文本描述来绘制对象
微软AI可以根据详细的文本描述来绘制对象

谷歌可能教过人工智能如何涂鸦,但绘制一些更复杂的东西对于电脑来说很难。想象一下,让一台电脑画一只“黑色的翅膀和一个短喙的黄色的鸟”;这听起来有点棘手。不过,微软的研究人员已经开发了一种基于人工智能的技术来做到这一点。根据团队发布的最新文章,它以惊人的准确性从文本描述生成图像。
系统根据您的输入找不到现有的图像,但会创建真实的图形。首席研究员何晓东在一份声明中表示:“如果你去了Bing并且寻找一只鸟,你就会得到一张鸟的照片,但是这里的照片是由计算机逐个像素地从头开始制作的。 “这些鸟可能不存在于现实世界中 - 它们只是我们计算机对鸟类想像力的一个方面。”
虽然这种绘画技术的当前形式并不完美,但不难想象,未来它可以作为画家和室内设计师的素描助手,或者是基于语音输入来精炼照片的工具。更远的是,研究人员他想象从书面脚本生成的动画电影。
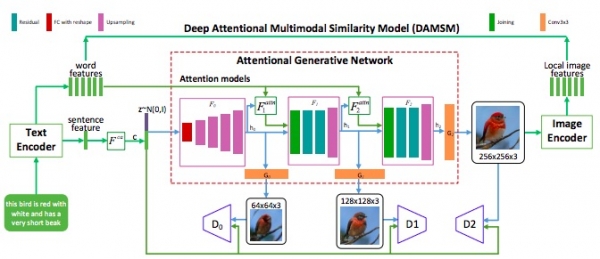
该团队开始研究计算机视觉和自然语言处理与CaptionBot,一个人工智能系统,自动为照片写字幕,然后创建一个系统回答人们问的图像称为SeeingAI的问题,如果你是盲人。目前的技术由两部分组成:一个是产生被称为生成对抗网络(GAN)的图像,另一个是判断所产生的图像的质量,称为鉴别器。绘图机器人接受了一系列图像和标题的训练,教导人工智能学习使用哪些图像处理哪些单词。团队还创建了一个人类关注的数学表示,当我们从复杂的描述中绘制图片时,我们都使用这个表示:一个红色的翅膀,一个尖锐的喙,一个黄色的翅膀。他说:“注意力是一个人的概念,我们用数学来计算注意力。”
这个绘图机器人完成了围绕计算机视觉和自然语言处理交叉部分的研究循环,何晓东和他的同事在过去五年中一直在这个领域内摸索。他们一开始研究的是一项能够自动为照片编写标题的技术——CaptionBot,然后转向能够回答人类关于图像问题(例如语音对象的位置和属性)的技术,这种技术对于盲人来说特别有用。
这些研究工作需要训练机器学习模型来识别对象、解释行为并用自然语言进行交谈。
微软研究院研究员Pengchuan Zhang补充表示,图像生成是一项比图像字幕更具挑战性的任务, 因为这个过程需要绘图机器人想象出标题中没有包含的细节。“这意味着,你需要让运行人工智能的机器学习算法想象出这个图像中缺失的部分。”
会集中注意力的图像生成
微软绘画机器人的核心是生成式对抗网络(Generative Adversarial Network,或者称为GAN)技术。该网络包含了两个机器学习模型,一个根据文字描述生成图形;另一个则作为鉴别器(discriminator),使用文本描述来判断所生成的图像的真实性。这两个模型组合既矛盾又融合,生成器试图让假的图片通过鉴别器的鉴定,鉴定器决定了自己不被愚弄,两者一起工作,鉴定器会推动生成器变得完美。
传统生成式对抗网络(GAN)在根据简单文字(例如蓝色的鸟或者常青树)描述生成图像方面做得非常好,但是当文字描述变得更复杂的时候,例如绿色的头、黄色的翅膀、红色的肚皮的鸟,质量就会停滞不前。这是因为整个句子对于生成器来说是一个单一输入,这些描述中的详细信息丢失了,结果生成的图像是一只模模糊糊的、有点绿、有点黄也有点红的鸟,而不是严格按照句子中的描述进行着色的鸟。但是,微软的该项技术尤其擅长根据复杂的句子绘制图像,而且,在标题的描述中没有提到的具体细节方面,机器人也可以填补这些空白。
这是因为,它有一点自己的常识和想象力,这要感谢它的训练数据。在鸟的例子中,机器人画的鸟通常是站在枝头上的,即使是文本内容中并没有提到这一细节也是如此,这是因为最初提供给它的图像经常出现类似的内容。
微软的绘图机器人使用了标题和图像匹配好了的数据集进行训练,这让这些模型能够学会如何将文字内容和这些内容的可视化表达相匹配。例如,这个生成式对抗网络(GAN)学会了在标题是鸟的时候生成一个鸟的图像,而且也学到了鸟的图像应该是什么样子。何晓东表示:“这是我们相信机器可以学习的根本原因。”
在人类画画的过程中,会反复查看下一步画什么,并且十分专注于正在描绘的这一部分内容当中。为了捕捉这一人类特质,微软研究人员创建了他们称之为注意力生成式对抗网络或AttnGAN的技术,它从数学上代表了人类的注意的概念。它是通过将输入的文本内容分解为单个的词语,并将其同图像中特定的区域进行匹配来完成这一任务的。
何晓东解释说:“注意力是一个人类的概念;我们把注意力的问题变成了一个计算的问题。”
该模型还会从训练数据中学习人类称之为常识的东西,并且利用这些学到的概念来填补图像中可供想象的空白部分。例如,由于训练数据中的很多图像里的鸟都是站在枝头之上的,所以除非文本内容另有详细说明,AttnGAN通常画出的鸟也都是站在枝头之上的。
Pengchuan Zhang表示:“从数据来看,机器学习算法学到了鸟应该在哪里这一常识。”作为难度测试,该团队给这个绘图机器人一些荒谬的题目,例如“漂浮在湖面上的红色双层巴士。”结果它生成了一个模糊的、湿漉漉的图像,既有点像一艘有双层甲板的船,又有点像一辆双层巴士,漂浮在群山环绕的湖面上。这个图像表明,该机器人内部产生了斗争,它知道船是漂浮在湖面上的,而文本内容却详细指定了对象是一辆巴士车。
何晓东解释说:“我们的描述可以天花乱坠,看看机器会如何反应。这台机器有一些背景知识的常识,但它仍然服从你的要求,尽管有时这些要求听起来有点荒谬。”
当然,这不是第一项将艺术和人工智能结合在一起的技术案例。
这两者的交叉有时会产生奇妙的结果。比如谷歌的人工智能绘制的这些梦幻般的图像就有了自己的艺术展,谷歌还有一个神经网络可以猜测你正在画的是什么,还有一个自动绘图机器人等等。
Facebook也一直在教导神经网络绘制一些小图形,例如飞机、汽车和动物等,甚至从照片中创建自己的Bitmoji风格的化身形象。
英伟达的研究人员使用人工智能(A.I)创建了计算机生成的名人。
实际应用
从文本到图像的生成技术可以找到很多实际应用,可以作为画家和室内设计师的草图助理,或者作为语音激活照片的细化工具。何晓东认为,如果有更多的计算能力,这项技术能够根据电影剧本生成动画电影,通过消除一些手工劳动来改善动画电影制片人的工作。
然而目前来看,微软的这项技术还不完善。如果你仔细检查图像就能找到瑕疵,例如鸟的喙是蓝色的而不是黑色的,以及水果摊位上有突变的香蕉。这些缺陷清楚地表明,创造这幅画的是电脑而不是人类。尽管如此,何晓东认为,这个AttnGAN生成的图像的质量比之前最好的GAN生成的图像质量提高了接近三倍,已经成为了通往类人类智能道路上的一个里程碑,这些类人类智能能够增强人类的能力。
何晓东进一步解释说,“对于生活在同一个世界里的人工智能和人类来说,他们必须有一种彼此交流的方式。而语言和视觉是人类和机器互相交流的两种最重要的方式。”
原文标题:微软AI可以根据详细的文本描述来绘制对象
文章出处:【微信号:IEEE_China,微信公众号:IEEE电气电子工程师】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Vibe Coding AI全栈开发实战
AI辅助编程设计之道:从Spec到Code工程实践
微软全新AI超级工厂Fairwater在亚特兰大落成
CAD如何绘制螺旋线

Labview 解析dxf文件并显示<一>
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的科学应用
微软Visual Studio 2026 发布!AI 深度融合、性能提升




评论