 一文说清楚什么是AI大模型
一文说清楚什么是AI大模型
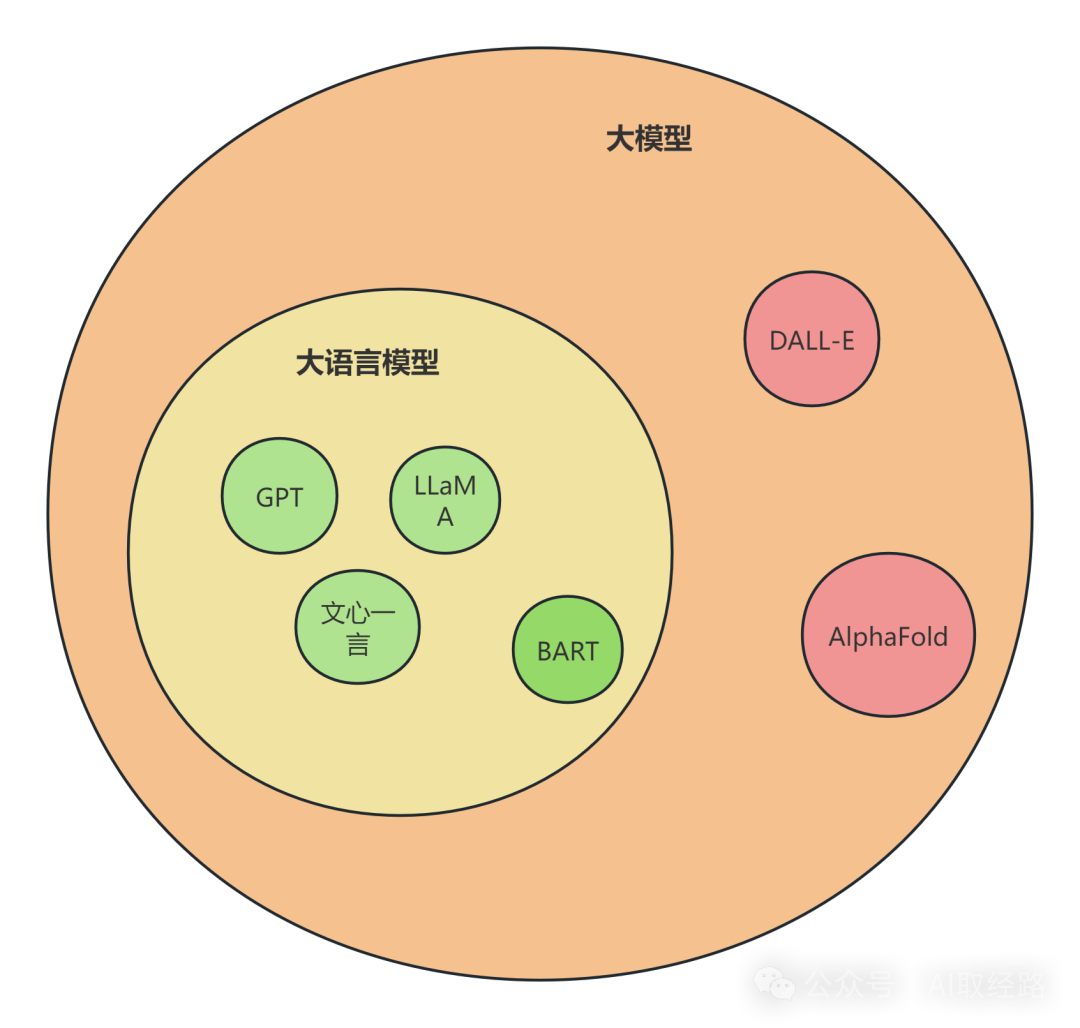
目前,大模型(特别是在2023年及之后的语境中)通常特指大语言模型(LLM, Large Language Model),但其范围也涵盖其他领域的超大规模深度学习模型,例如图像生成模型(如 DALL-E)、科学计算模型(如 AlphaFold)以及多模态模型。这些模型通过海量数据训练,展现出高度的泛用性。
比较有代表性的大语言模型(LLM)如:
| 模型 | 开发方 | 特点 |
|---|---|---|
| GPT-4 | OpenAI | 生成能力强,部分版本支持多模态输入(如图像理解) |
| 文心一言 | 百度 | 针对中文优化,适合国内应用场景 |
| LLaMA | Meta | 开源,轻量化 |
大语言模型(LLM)是近年来人工智能领域的核心热点,其训练目标通常是语言生成和理解。这些模型通过在海量文本上进行训练,能够理解、生成和推理复杂的自然语言,甚至跨领域处理任务。其特点是拥有超大规模参数、具有强大的通用性和生成能力。由具有许多参数(通常数十亿个权重或更多)的人工神经网络组成,使用自监督学习对大量未标记文本进行训练
1. 大语言模型(LLM)的核心定义
基础:大语言模型通常是基于深度学习架构(如Transformer)开发的,通过捕捉自然语言中的模式和语法规则,理解上下文和语义。
规模“大”:指参数规模(数十亿到数万亿个参数)、训练数据量(TB 级别以上的文本)、以及计算需求的巨大。
目标:预测文本中的下一个词(语言建模),或在更高层次上,生成合理的文本输出。
能力:除了文本生成,它还能执行诸如翻译、总结、分类、问答、推理、代码生成等复杂任务。大语言模型是通用模型,在广泛的任务中表现出色,而不是针对一项特定任务进行训练
现在大火的智能体(AI Agent)的大脑就是基于大语言模型,详见:
一文说清楚什么是AI Agent(智能体)
2. 大语言模型(LLM)的核心技术和特性
2.1 Transformer 架构
Transformer 是一种基于“注意力机制”的神经网络架构,由 Google 于 2017 年提出。它的核心特性是:
自注意力机制(Self-Attention):能捕获句子中每个词与其他词之间的关系,量化它们的重要性,提取上下文语义。
并行计算:相比早期的 RNN 和 LSTM,Transformer 能更高效地处理长文本。
LLM(如 GPT 系列)大多基于 Transformer 的变体。
2.1.1 看全局抓重点:注意力机制
想象你是一个班主任,班干部(Transformer)负责审阅学生的作业。如果有句子写得特别好(比如“春风拂面百花开”),班干部会特别关注这句话,并给它“打一个高分”。这就是 Transformer 的注意力机制,它知道哪些部分更重要,应该重点关注。
2.1.2 并行处理:效率高
以前的模型像流水线工人,必须按顺序一字一句地看完所有作业(比如传统的 RNN)。而班干部(Transformer)更像是一群分工明确的审稿员,可以同时看整篇作业,快速抓住重点。
2.1.3 理解句子结构:捕捉长距离依赖
如果有学生写了一篇长文章,开头提到“春天来了”,后面说“鲜花盛开”。班干部(Transformer)不会忘记开头的信息,会把“春天来了”和“鲜花盛开”关联起来。这种能力叫长距离依赖捕捉,让模型能理解前后文的语义联系。
Transformer 的注意力机制让每个词都可以关注整个句子中的其他词,而不是局限于前后相邻的词。这解决了传统 RNN 处理长文本时容易“遗忘上下文”的问题。
2.1.4 将文字变成数字:嵌入表示Embedding
班干部在看作业时,需要先把作业内容分类,比如:数学题归类到“数字”里,作文归类到“语言”里。同样,Transformer 需要先把文字转换成模型能理解的数字形式。这种表示叫“词嵌入(Word Embedding)”。Transformer 中会用“位置编码(Positional Encoding)”标记每个词的位置,确保模型理解词语在句子中的顺序。
Embedding详见:一文说清楚人工智能的嵌入(Embedding)是什么
2.2 Transformer 是如何生成答案的?
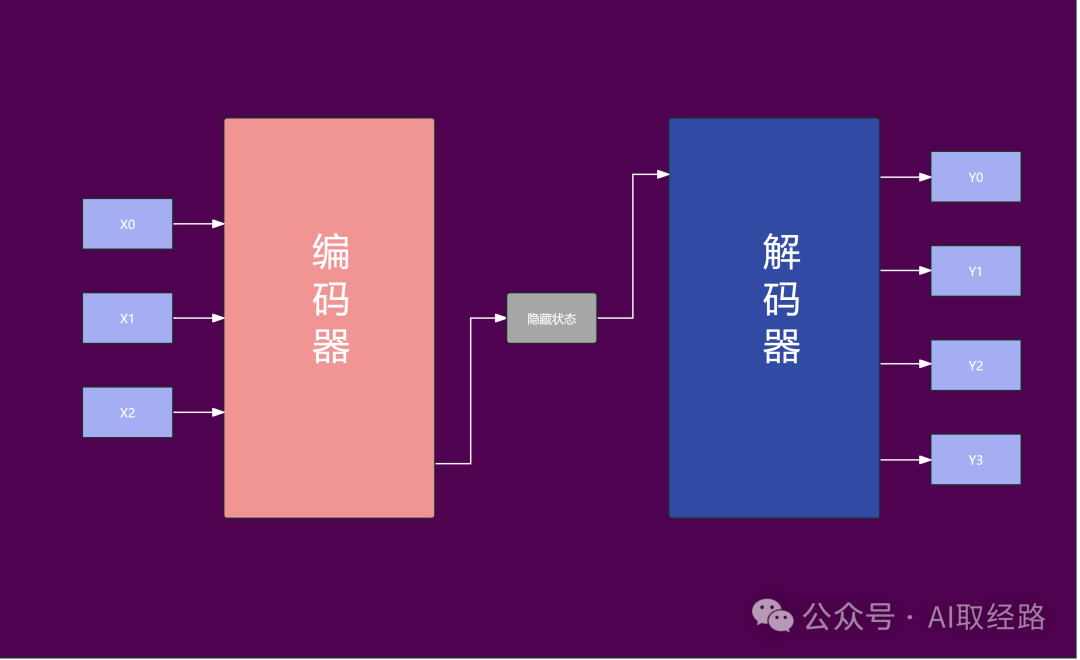
2.2.1 把重点重新组织:编码器-解码器结构
班干部(Transformer)把学生的作业总结后,用自己的话重新写一遍。这就是编码器-解码器结构的工作方式:
编码器:像一个分析员,把输入的内容(句子)理解后转化为内部的知识表示。
解码器:像一个写手,根据内部的知识表示生成输出(翻译、回答问题等)。
Transformer 的编码器负责对输入的句子进行特征提取,而解码器基于这些特征生成目标输出。这种结构广泛用于翻译和生成任务(如机器翻译、文本生成)。
2.2.2 输入和输出之间的关系:交叉注意力
班干部在总结学生的作业时,会参考原文里的句子重点(比如从题目到结尾)。这个过程叫交叉注意力,确保模型输出的内容和输入有紧密关联。
Transformer 在解码器中,模型需要关注输入的隐藏表示,通过计算解码器和编码器之间的注意力分数,确保生成的输出能准确反映输入的语义内容。
交叉注意力应用于编码器-解码器模型, GPT 是解码器-only 模型,其架构中不直接使用编码器-解码器的交叉注意力机制
2.3 为什么 Transformer 比传统方法强?
2.3.1 一眼看全局:自注意力机制
传统模型(如 RNN)像流水线工人,必须逐字逐句处理句子,而 Transformer 像一位高效的观察者,可以一眼看到全文,快速抓住重点。自注意力机制让模型对句子中的所有词进行“全局比较”,从而同时捕捉短距离和长距离的关系。
2.3.2 提高效率:并行处理
如果文章特别长,传统模型处理起来很慢,而 Transformer 像一群同时工作的专家,可以并行处理,提高效率。通过将输入句子分成块,并行计算每个词的注意力权重,Transformer 避免了序列模型的时间瓶颈,效率显著提高。
2.3.3 适应性强:预训练模型可迁移
班干部(Transformer)经过训练后,不仅能看作文,还能学会批改数学题、物理题等。这是因为它的“学习能力”很强,能根据不同的任务调整自己。模型可以先在大规模通用语料上预训练(如 GPT 或 BERT),学到语言的通用规律,再通过微调(Fine-tuning)适应特定任务。
3. 为什么“大模型”目前特指"语言模型"?
1.技术推动
大语言模型(如 GPT 系列)的出现展示了“通用人工智能”(AGI)的潜力,使得语言模型成为大模型的核心代表。
语言是人类认知和信息处理的基础,训练语言模型可以让 AI 在广泛的领域表现出色。
2.应用广泛
从对话生成到代码编写、从文档翻译到文本分析,大语言模型已经在多种场景中展示了高效性和通用性。
3.市场驱动
商业化需求(如 ChatGPT、Bard)让大语言模型成为公众认知中的“大模型”代名词。
4. 为什么叫“大”模型,还有“小”模型吗?
1.参数规模
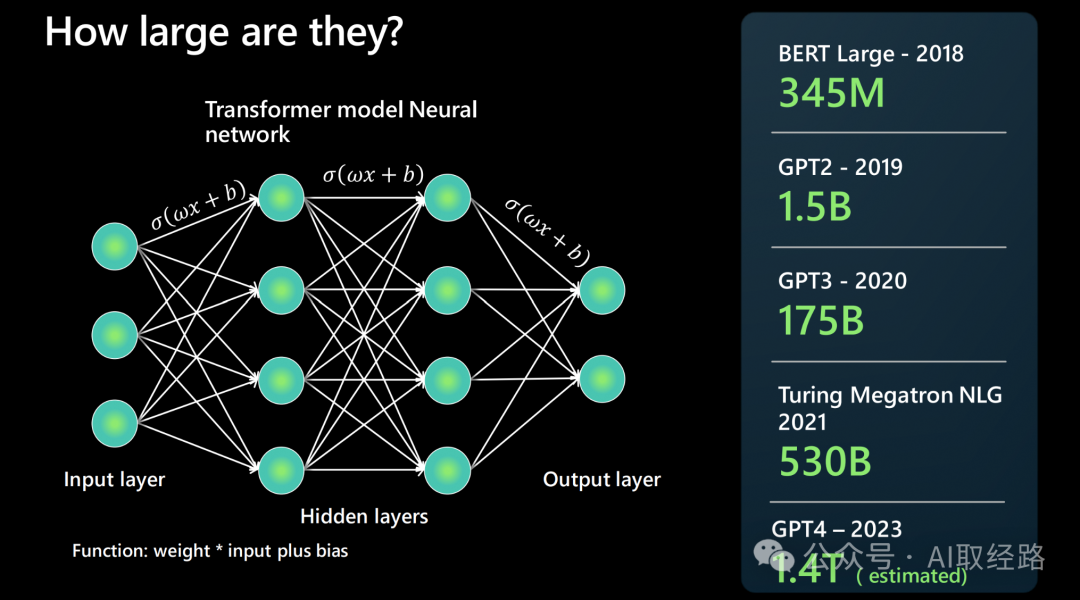
参数是模型中的可调节权重,用来捕获数据中的模式。大模型通常有数十亿到数万亿个参数。例如,GPT-3 有 1750 亿个参数,GPT-4 甚至更多。
参数数量越多,理论上模型能够捕获的复杂模式也越多,但这也意味着更高的计算和存储成本。
2.训练数据量
大模型往往需要海量数据进行训练。数据越多,模型越有可能泛化,适应更多样的场景。
例如,大语言模型可能使用来自互联网的数千TB文本数据。
3.计算资源
大模型的训练和推理(inference)需要高性能的硬件支持,比如 GPU 或 TPU 集群。
训练一个大模型可能需要数周或数月,耗费数百万美元的计算成本。
3.能力范围
大模型通常具备较强的通用性,可以跨越多个任务。例如,GPT-4 不仅可以生成文本,还能进行翻译、代码生成等多种任务。
它们还能在新任务上实现良好的零样本(Zero-shot)或少样本(Few-shot)学习能力。
不过,大模型的“更大”并不总是等于“更好”。随着参数数量的增长,模型性能的提升并非线性递增。在超过一定规模后,训练更大的模型可能仅带来微弱的精度提升,但计算资源和能耗成本会显著增加。
5.“小”模型有哪些
相对大模型,小模型是指参数数量较少、规模较小、专注于特定任务的模型。例如:
MobileNet:专为移动设备设计的图像识别模型,参数量较小,计算高效。
GPT-2 的小型版本:用于低资源环境,参数数量可能在百万级别。
LightGBM、XGBoost 等传统机器学习模型:虽然严格意义上不是深度学习模型,但也属于小模型范畴。
小模型的优点
计算效率高:可以部署在资源有限的设备(如手机或嵌入式系统)上。
训练成本低:对硬件需求较低,训练时间更短。
专注性强:通常专注于解决单一任务,性能更高效。
在实际应用中,小模型常用于边缘设备上的实时推理,而大模型则在云端完成高复杂度的任务。通过这种协作,可以在性能和效率之间找到平衡。
-
AI
+关注
关注
87文章
30998浏览量
269323 -
大模型
+关注
关注
2文章
2476浏览量
2806 -
LLM
+关注
关注
0文章
290浏览量
351
原文标题:一文说清楚什么是AI大模型
文章出处:【微信号:深圳市赛姆烯金科技有限公司,微信公众号:深圳市赛姆烯金科技有限公司】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
文心大模型生态大会:启明智显AI智能产品展现AI无限“模力”

从箱子里找出来的示例:Air780E软件指南之TCP应用

buffers内存与cached内存的区别

NONOS如何检查是否实际发送了UDP数据包?
AI大模型与小模型的优缺点
STM CUBE AI错误导入onnx模型报错的原因?
请问STM32 EXTI的脉冲发生器输出可以连接什么外设?
防止AI大模型被黑客病毒入侵控制(原创)聆思大模型AI开发套件评测4






 工商网监
工商网监
评论