 谈谈DeepSeek-v3提到的基础设施演进
谈谈DeepSeek-v3提到的基础设施演进
看DeepSeek-v3的感受是, 算法和Infra的非常紧密结合. 其实很多大模型团队的算法和Infra是非常割裂的, 完全同时懂算法和Infra的人并不多, DeepSeek这个团队就是其中之一, DeepSeek团队中应该有不少OI竞赛获奖选手, 其实对于我们这些搞过OI的人, 对于计算上的优化策略基本上都是手到擒来,很多时候把处理器的体系结构也研究的很深, 所以同时做算法和Infra是非常自然的一件事情, 而如今很多算法岗的新人大多数人的代码能力是非常有限的....
当然渣B稍微再得瑟一下, 比DeepSeek他们还更懂更底层的芯片以及它们的互联, Maybe再多懂一点数学... 昨天还跟一朋友讲了一个冷玩笑, FP8训练这些Quantization不就是Quant变渣("za"tion)么,^o^.
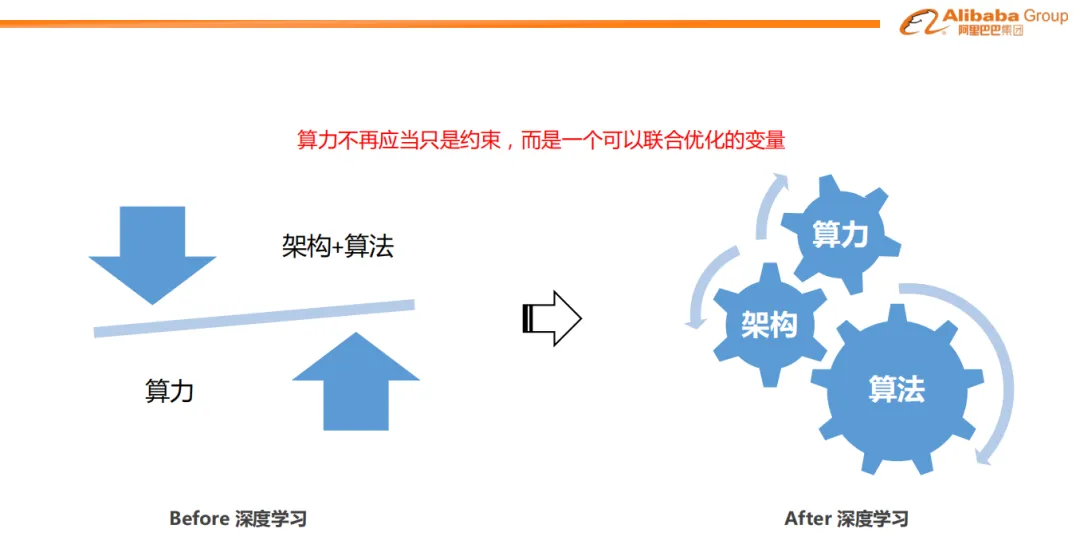
1. 算力不再应当只是约束,而是一个可以联合优化的变量
其实很多年前, 阿里妈妈团队就在推荐系统引入深度学习时做过大量的算法和算力Infra协同的工作, 非常认同周国睿老师的一句话:“算力不再应当只是约束,而是一个可以联合优化的变量”
今年年初还把这一系列的算法和算力的协同发展整理了一下, 可以参考
《谈谈AI落地容易的业务-搜广推》
其实再来说说量化交易这一块, 它和搜广推很类似的也是需要在一个时间约束下做到算力和算法的平衡, 对于很多高频交易策略其实就更难了, 涉及到一系列硬件上和算法算力的协同了, 有些时候还可以牺牲稳定性为代价, 举个例子有些高频交易的团队还在用家用CPU超频的方式来获得更快的运算速度, 另一个例子在很多网卡上连一个寄存器都要省....
对于DeepSeek/幻方有了这样的主营业务做大模型时,整个团队的火力自然是满满的...当然渣B这样的参与了国内几乎所有交易所的交易网络设计有合规问题和自身的职业操守就没有去趟高频这块...
另一方面渣B对现在的大模型Transformer架构还是有更多的不认同, 它一定不是通往AGI的终态, 因为这样的依赖极大算力的ScalingLaw的算法本质上应该是一个错误, 所以渣B更多的时间是在底层优化算力和顶层算法背后的数学原理上花了更多的精力.
在底层算力方面, 主要是GPU微架构的分析和Tensor运算相关的工作以及AI加速器高速互联等
《GPU架构演化史》
《Tensor运算》
《AI加速器互联》
在数学方面(嗯,学习J神“数学方面”), 渣B一直有一个暴论:这一次人工智能革命的数学基础是:范畴论/代数拓扑/代数几何这些二十世纪的数学第一登上商用计算的舞台。, 因此一直也在做一些专题的研究
《大模型的数学基础》
最近看到一些论文, 例如TOPOS的视角来看待多模态大模型, 还有一些Grothendieck图神经网络一类的东西, 似乎看到一些光了,但是这些东西是这个世界上为数不多英雄主义的存在, 一张纸一支笔的浪漫.
当然很多人怀疑这些代数上的东西以及GNN本身的一些稀疏计算的效率问题似乎跟AGI毫无关系. 但事实上它们可能是人脑里最精彩的存在. 昨天也到MTP时有一个观点:
MTP让我想到了Zen5的2-Ahead Branch Predictor 非常有趣的工作, 其实对于o3这样的模型, 本质上是token as an intruction.
原来GPT是一个顺序执行结果predic next token 类似于 pc++, 然后在栈上(historical tokens as stack)操作. 顺序预测下一个token
o1/o3 Large Reasoning Model 无论是MoE或者是强化学习一类的PRM, 实质上是在Token Predict上做了Divergence, 例如跳转/循环/回溯 等, PRM可以看作是一个CPU分支预测器. 从体系架构上渐渐的可以让大模型做到类似于图灵完备的处理能力.
基于这个观点, 那么当前的GPU的TensorCore/Cuda Core实际上就构成了一个执行引擎, 外面还需要一系列控制, 分支预测, 译码器, LSU来配合, 对于基础设施带来的演进还是有很多有趣的话题可以去探索的
另外一个暴论:当前的Transformer模型本身作为一种生成Token的数据路径, 而Grothendieck图神经网络一类的东西和相关的代数结构本身作为模型的控制路径, 这是跑通LRM的一条路
2. 硬件和体系架构的演进
DeepSeek-v3的实现也非常优雅, 例如考虑H800被阉割的影响, 训练没有采用TP并行. 然后针对MoE的AlltoAll做了极致的优化, 例如PXN和IBGDA等, 还有warp specialization以及dualpipe等.
相反我们看看Meta那群人, AlltoAll去年的OCP还在叫唤着Call for Action, 然后Llama3的MoE听李沐讲了一个八卦他们训练失败了...也难怪要多花10倍的钱...
回到DS团队提到的一些未来硬件的需求, 例如当前H800的132个SM中被分配了20个SM用于通信, 需要通信协处理器,以及为了减少应用程序编程的复杂性,希望这种硬件能够从计算单元的角度统一ScaleOut和ScaleUp网络。通过这种统一接口, 计算单元可以通过提交基于简单原语的通信请求.
其实这些东西渣B几年前就全部讲清楚并做了一系列POC. 在2018年的时候, 看到Transformer出来以及模型开始越来越大通信成为瓶颈时, 渣B当时在Cisco就在做AI Infra相关的预研, 第一个把深度学习模型引入到Cisco路由器中做一系列Performance Assurance和Security Assurance相关的业务.
然后2020年的时候和第四范式的一些研讨后, 然后设计和实现了NetDAM. 到如今你会发现Tesla TTPoE也是在做同样的事情.
《NetDAM专题》
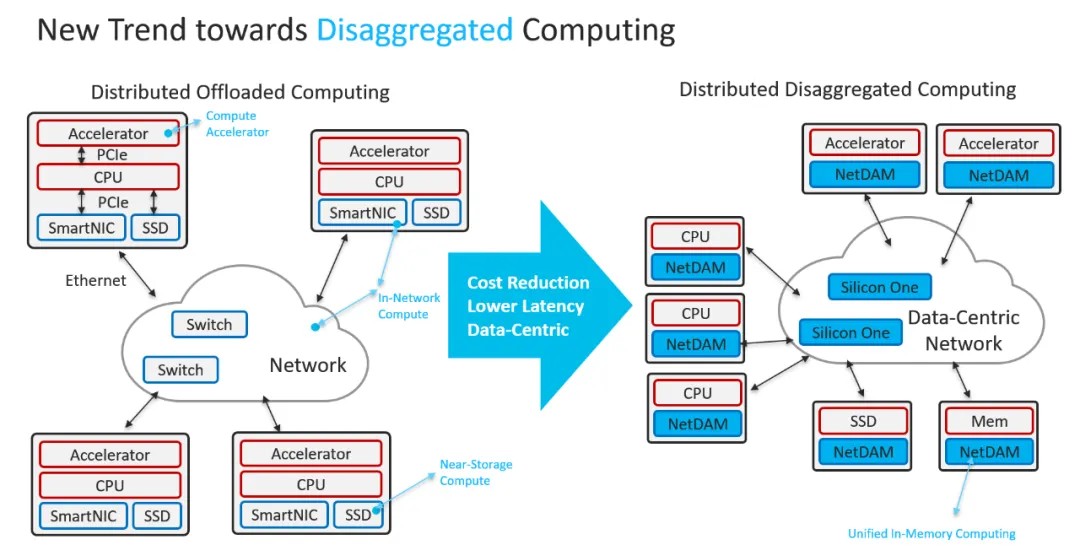
时至今日, 你会发现DeepSeek对未来硬件的演进, 都在这一套框架内完全实现.
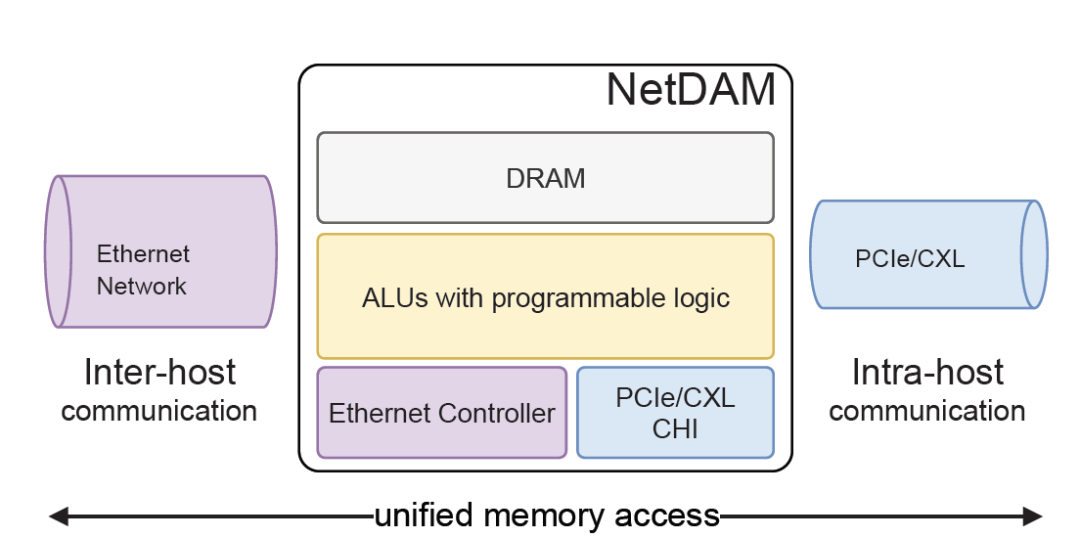
首先, 它对GPU侧是一个标准的内存接口, 通过在NetDAM上的一片内存, 基于内存语义把ScaleOut(Inter-Host)和ScaleUP(Intra-host)的通信完全融合了. 然后DS提到的Read/Write/multicast/reduce这些也是NetDAM一开始就做的功能, 例如RoCE需要多次访问GPU内存并引入CPU控制流
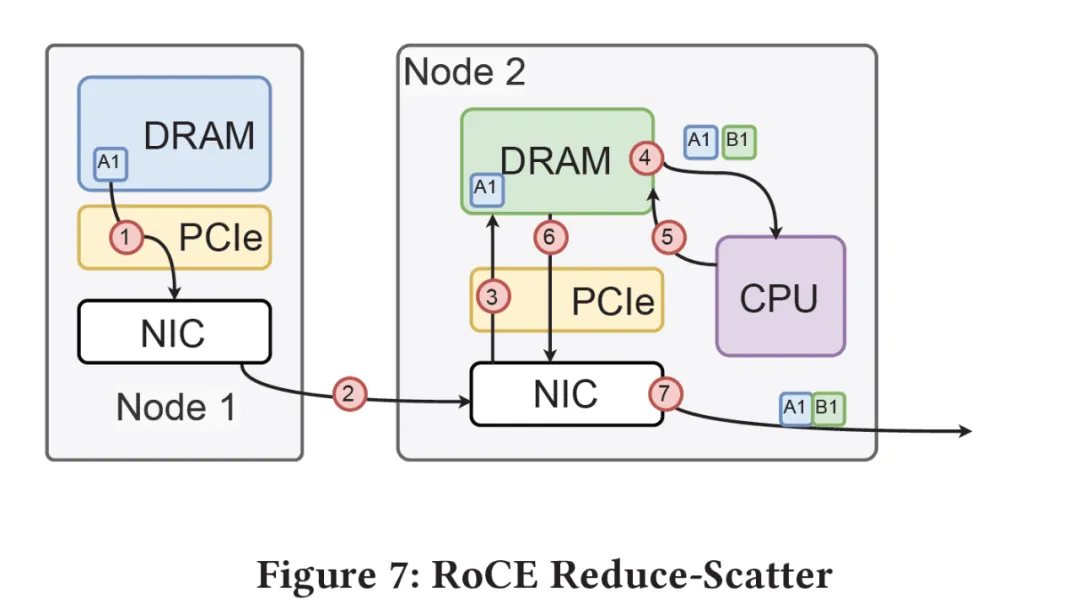
而NetDAM直接进行了卸载:
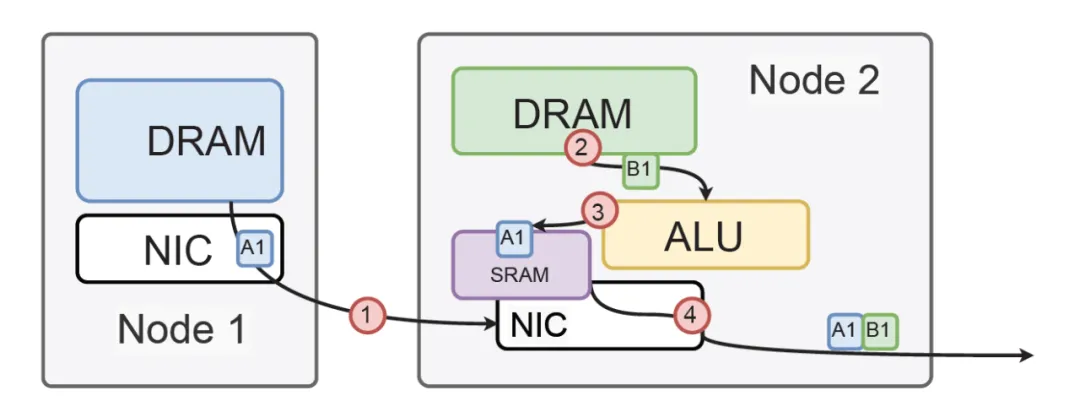
而对于DS后面提到的一系列量化和Scale相关的近内存计算, 本质上在NetDAM上是最好的附着点. 例如很多人说Mellanox延迟低, NetDAM直接bypass PCIe延迟轻松秒杀
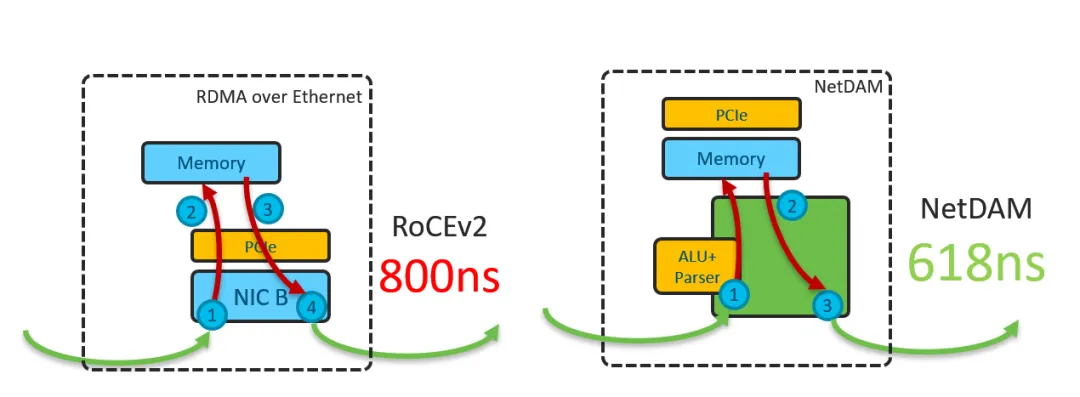
但是这个世界并不是完美的, 因为人总归是有屁股的. 例如思科当时的重心全部放在了Silicon One上, Intel守着自己的UPI在CXL上扣扣搜搜的, 而同样Nvidia在B200这一代虽然把IB和NVSwitch融合在一起做交换芯片, 但最终在未来还是分开了...
而如今呢?当一切的事情越来越清晰的时候, 或许这些厂商们会明白这个问题了...
-
芯片
+关注
关注
456文章
50889浏览量
424281 -
算法
+关注
关注
23文章
4615浏览量
92993 -
大模型
+关注
关注
2文章
2476浏览量
2806
原文标题:谈谈DeepSeek-v3提到的基础设施演进
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
雷军千万年薪挖角95后AI天才少女 DeepSeek开源大模型DeepSeek-V2关键开发者之一罗福莉
NVIDIA助力印度打造AI基础设施
智能驾驶所需的基础设施

微软贝莱德成立AI基础设施投资基金
PerfXCloud顺利接入MOE大模型DeepSeek-V2
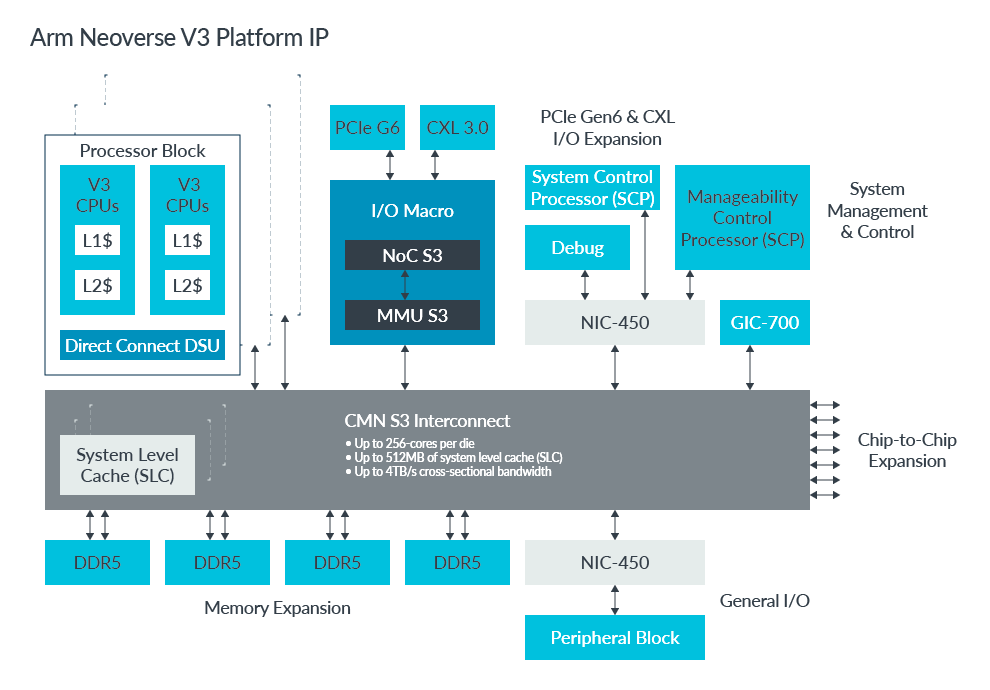
Arm Neoverse S3 系统 IP 为打造机密计算和多芯粒基础设施 SoC 夯实根基
展望2024数据中心基础设施
垂直起降机场:飞行基础设施的未来是绿色的
Neoverse S3系统IP为打造机密计算和多芯粒基础设施SoC夯实根基





 工商网监
工商网监
评论