 港大提出SparX:强化Vision Mamba和Transformer的稀疏跳跃连接机制
港大提出SparX:强化Vision Mamba和Transformer的稀疏跳跃连接机制
本文分享香港大学计算和数据科学学院俞益洲教授及其研究团队发表于 AAAI 2025 的论文——SparX,一种强化 Vision Mamba 和 Transformer 的稀疏跳跃连接机制,性能强大,代码已开源。

论文标题: SparX: A Sparse Cross-Layer Connection Mechanism for Hierarchical Vision Mamba and Transformer Networks
论文链接:
https://arxiv.org/abs/2409.09649
代码链接:
https://github.com/LMMMEng/SparX
摘要
香港大学计算和数据科学学院俞益洲教授 (https://i.cs.hku.hk/~yzyu/index.html) 及其研究团队开发了一种新型的层间稀疏跳跃连接机制 --- Sparse Cross-Layer Connection Mechanism (SparX),可以有效提升包含 Vision Mamba 和 Transformer 在内的 Vision Backbone 的性能。
不同于常规的 Vision Backbone 通过堆叠相同的基础模块来搭建网络架构,SparX 受到了人类视觉系统中神经节细胞 (Retinal Ganglion Cell) 的启发, 将网络的基础模块分为两种不同的类型:神经节层 (Ganglion Layer) 和常规层(Normal Layer)。
前者具有更高的复杂度和连接度,类似于视觉系统中的神经节细胞,而后者的连接度和复杂度都较低,类似于视觉系统中的常规细胞。通过交叉堆叠 Ganglion Layer 和 Normal Layer 构建了一种新的 Vision Backbone 网络,在图像分类、语义分割和目标检测中展现了强大的性能。
例如,基于 SparX 构建的 Vision Mamba 模型 SparX-Mamba 相较于强大的 VMamba 仍有明显提升:虽然参数量更少,SparX-Mamba-T 在 ImageNet-1K 上的 Top-1 准确率仍超越 VMamba-T 1%。此外,SparX-Mamba 在语义分割和目标检测任务上同样具备突出的性能,展现了 Mamba 模型在学习长距离关联方面的优越性。
动机
随着自注意力(Self-attention)和状态空间模型(State Space Models 或 SSMs)在 NLP 任务中的优异表现,许多工作将这些方法成功应用到了视觉领域,例如 Swin-Transformer 和 VMamba。 目前主流的 Vision Backbone 模型的设计策略为构建新的 token mixer,并据此来构建视觉网络。然而,不同层输出的特征具有一定的互补性和冗余度,因此,寻找这些特征之间的互补性,并且移除冗余的特征可以进一步提升网络的表征能力,进而提升性能。 虽然一些先前的工作(例如 DenseNet)已经利用了不同网络层的交互和复用来提升性能,但是 DenseNet 中的稠密连接具有较高的计算复杂度,使其难以直接用于比卷积更加复杂的和 SSM 算子。因此,设计一种高效的神经连接机制来挖掘和利用网络的层间互补性仍然需要进一步探索。
方法
以基于 Mamba 的模型为例,在 SparX 中 Ganglion Layer 包含用于提取局部信息的动态位置编码(Dynamic Position Encoding (DPE)),用于实现层间信息交互的 Dynamic Multi-layer Channel Aggregator (DMCA),和用于空间上下文信息建模的视觉状态空间模型(Visual State Space Model 或 VSS),而 Normal Layer 则没有 DMCA 模块。
此外,SparX 引入了两条新的跨层连接规则:
1. Sparse Ganglion Layers 将一组具有均匀间隔的层指定为更加复杂且连接度更高的 ganglion layers,而所有其余层则为复杂度和连接度都较低的 normal layers。为了控制ganglion layers的密度,进而控制网络的复杂度和连接度,研究团队引入了一个步长参数 S,即S=两个最近的ganglion layers之间的normal layers的层数加一。
此外,该规则定义了两种不同的连接类型:ganglion layer 和 norma layer 之间的内连以及两个 ganglion layers 之间的互连。为了让网络具备强大的层间特征交互且具有高效性,ganglion layer 只与处于自身和最近的前一个 ganglion layer 之间的那些 normal layers 建立内连,但是同时与多个先前的 ganglion layers 建立互连。
这种设计是因为:ganglion layer 可以被视为网络的“信息中心”,从最近的 normal layer 收集信息并与其他 ganglion layers 交换信息。一个简单的例子为:如果一个网络有 8 层并设置 S=2,则 normal layer 的索引为 {1, 3, 5, 7},而 ganglion layers 的索引为 {2, 4, 6, 8}。
2. 跨层滑动窗口(Cross-layer Sliding Window)旨在进一步提升网络高效性,其设计背后的动机是:尽管上述层间连接方式具有稀疏性,深层网络仍可能因需要存储和访问大量先前的特征图而产生较高的显存消耗。为此,受启发于经典的空间滑动窗口,引入另一个超参数 M 来限制每个 ganglion layer 仅与先前的 M 个最接近的 ganglion layers 建立互连。
基于这两条新规则,即使没有直接连接,语义信息仍然可以通过相对稀疏的内连和互连从较浅的网络层快速传递到较深的网络层。图 1 展示了一个 SparX (S=2, M=2) 的示例。
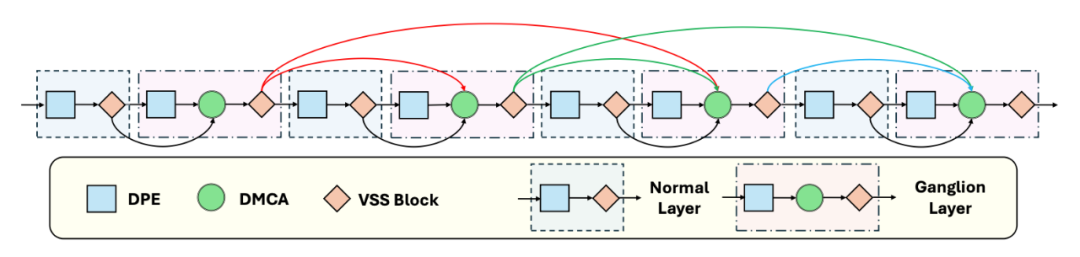
▲图1. Mamba-based SparX示例
为了选择性地从先前网络层的特征中挖掘有用的特征,从而动态的建模层间交互,研究团队提出了一个简单有效的 DMCA 模块。如下图所示,DMCA 用当前层特征作为 query,用先前层的特征作为 key/value 来构建 channel-wise cross attention。构建 channel attention 的目的是为了更好地进行通道之间的信息交互,从而获得更好的性能。
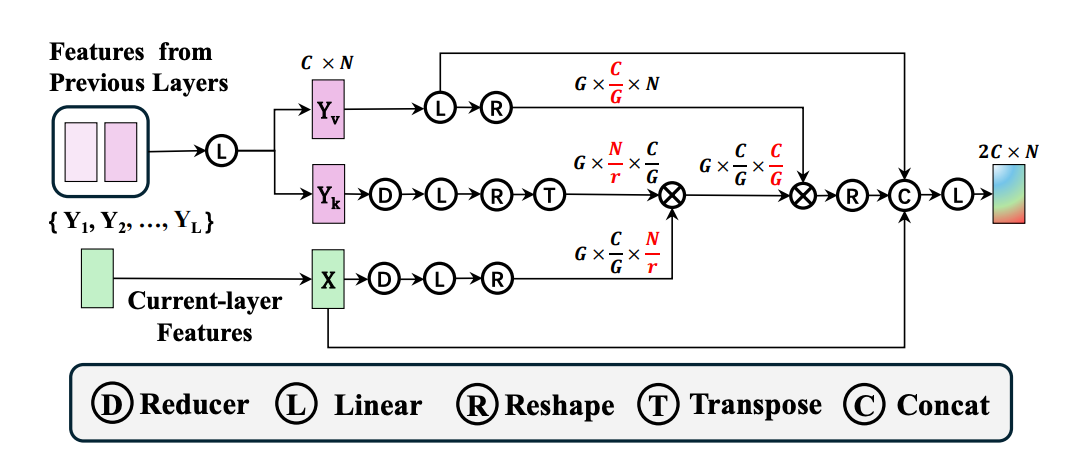
▲图2. DMCA架构图
实验结果
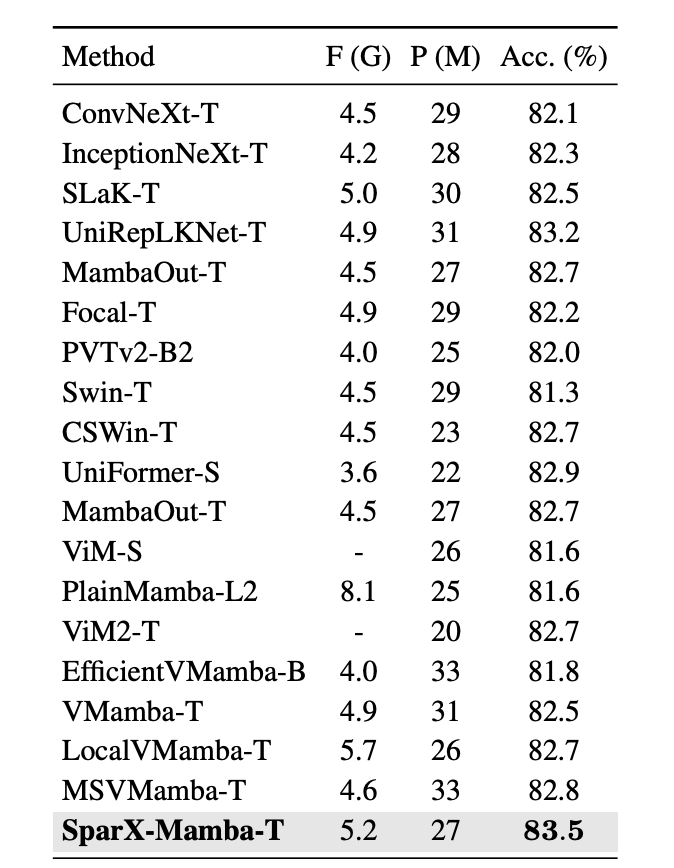
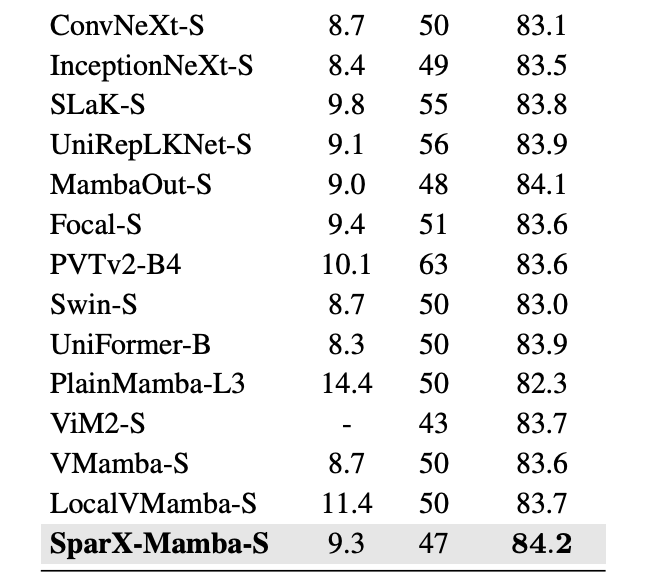
图像分类:SparX 在大规模数据集 ImageNet-1K 上表现出了卓越的性能,相较于现有方法,展现出更为出色的性能以及更好的 tradeoff。如表 1 所示,SparX-Mamba-S 仅以大约一半的参数量和 FLOPs 就超越了 VMamba-B 的性能。
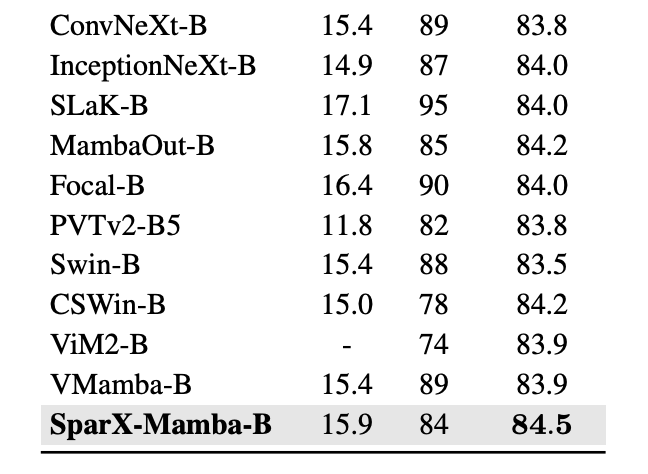
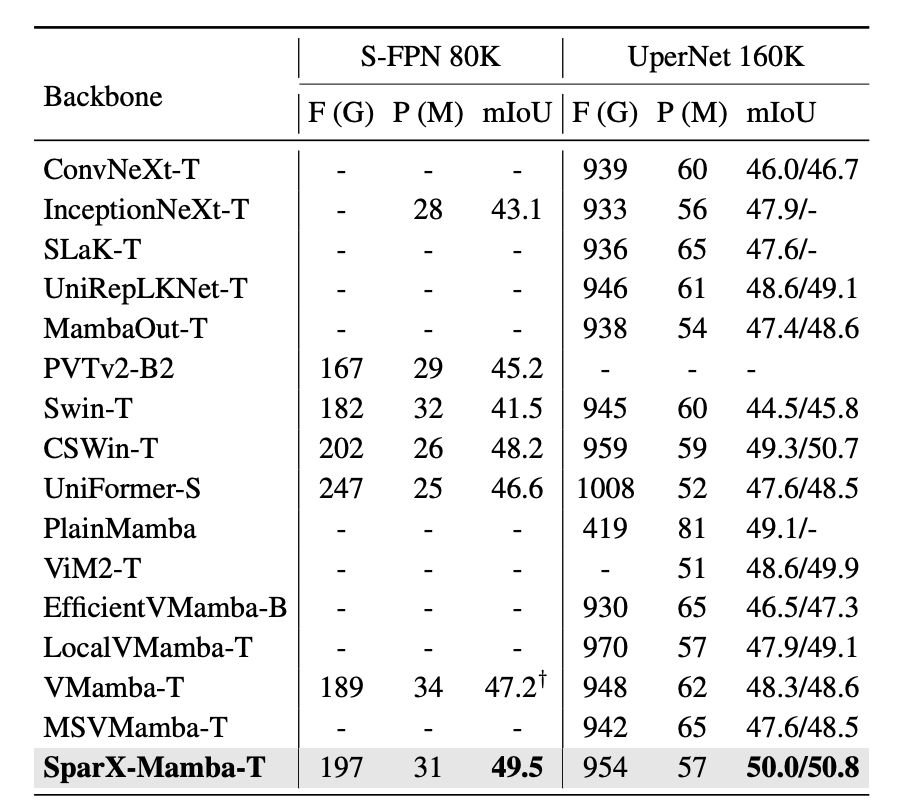
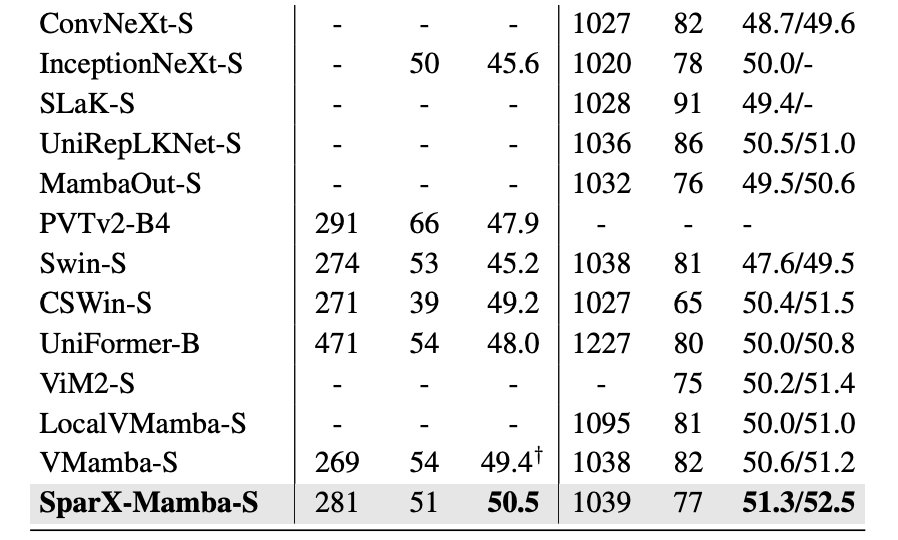
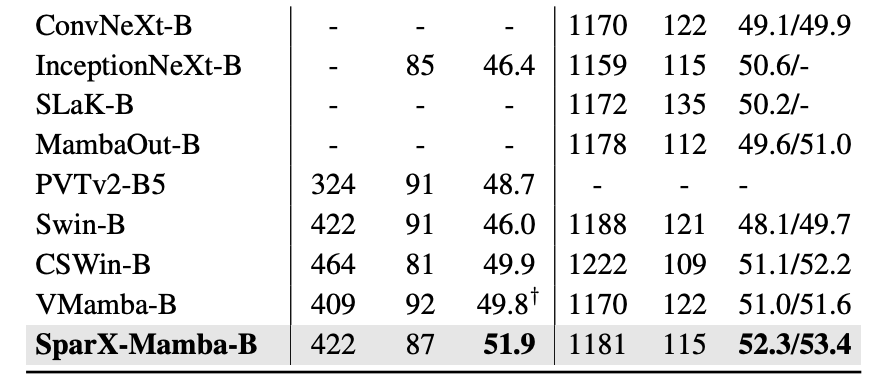
如表 2 所示,对 SparX 在 ADE20K 上也进行了全面的评估,其性能在与一些强大的 Vision Backbones 的比较中脱颖而出,并且有着好的 tradeoff。
如表 3 所示,在 COCO 2017 数据集上,SparX 同样展示出了更优的性能。值得注意的是,当使用更加强大的训练条件(3× schedule)时,SparX 展现了更加显著的性能提升。
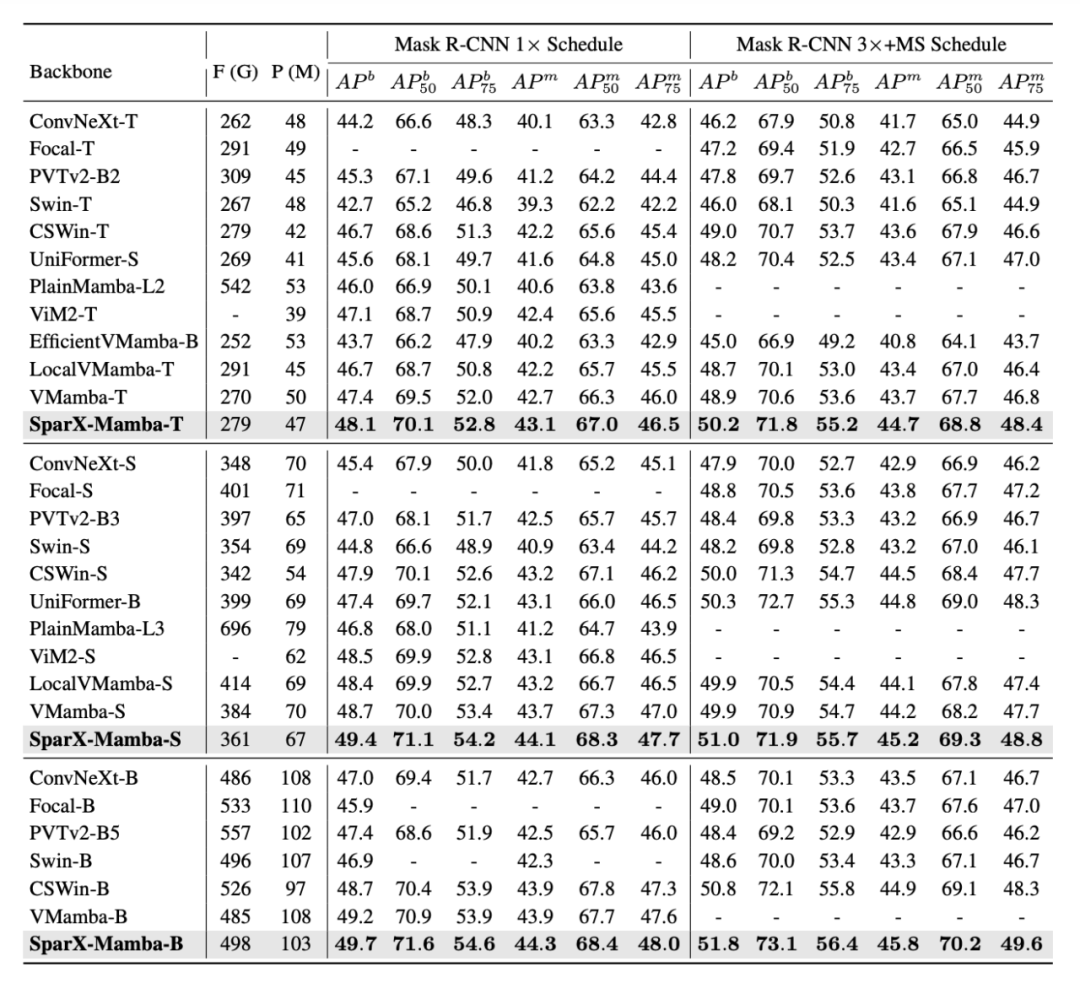
▲表3. COCO目标检测和实例分割性能对比
通用性实验
研究团队用经典的 Swin-Transformer 测试了 SparX 的通用性,为了保持公平对比,micro 设计严格保持了和 Swin 原始设计一致,例如完全相同的 patch embedding 和 token mixer。如表 4 所示,SparX 在不同任务上均取得了显著的性能提升。

▲表4. SparX用于Transformer架构时的性能
消融实验
为了验证 SparX 的有效性,研究团队构建了两种不同的稠密连接模型:1)Dense Ganglion Connections (DGC-Mamba-T):移除跨层滑动窗口(Cross-layer Sliding Window)来消除互连稀疏性;2)DenseNet-style Network (DSN-Mamba-T):完全按照 DenseNet 的策略来构建模型。
如表 5 所示,SparX 在保持最优性能的前提下还具备高效性。
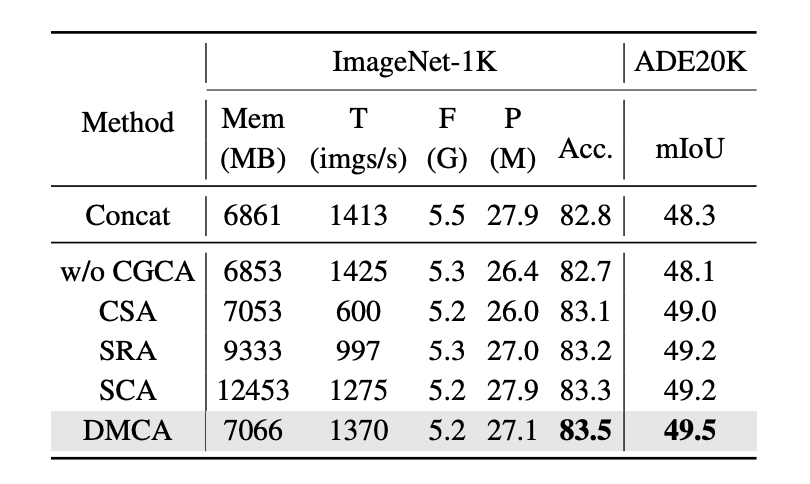
▲表5. SparX和Dense Connection的对比
可视化实验
Centered Kernel Alignment (CKA) 分析:不难发现,在表 5 消融实验中,连接度更高的模型(DGC 和 DSN)并没有带来性能提升。为了寻找背后的原因,我们进行了模型的 CKA 分析。 如图 3 所示,VMamba-T 每一层学习到的特征与相邻层非常相似,说明了模型具有大量的特征冗余。此外,DGC 和 DSN 模型可以学习到更加多样化的特征,降低了特征冗余度。与这些方法相比,SparX 不同层的特征更加多样化,从而具有更加强大的特征表达,这也是其性能更好的原因。
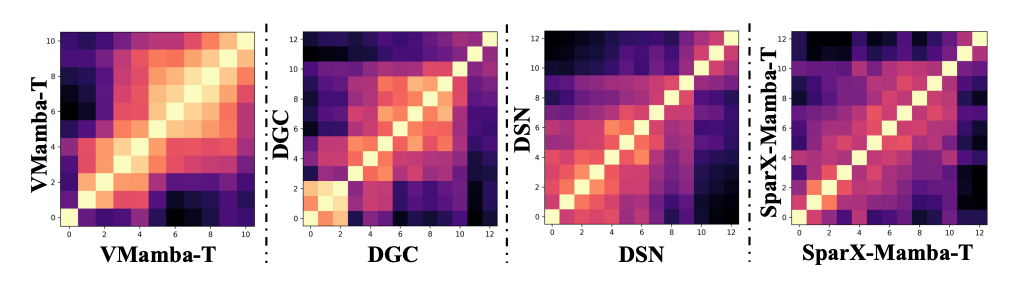
▲图3. CKA可视化
有效感受野(Effective Receptive Field 或 ERF)分析:如图 4 所示,SparX-Mamba 和其它方法相比具有更大的感受野,进一步说明了 SparX 对模型表征能力的增强效果。
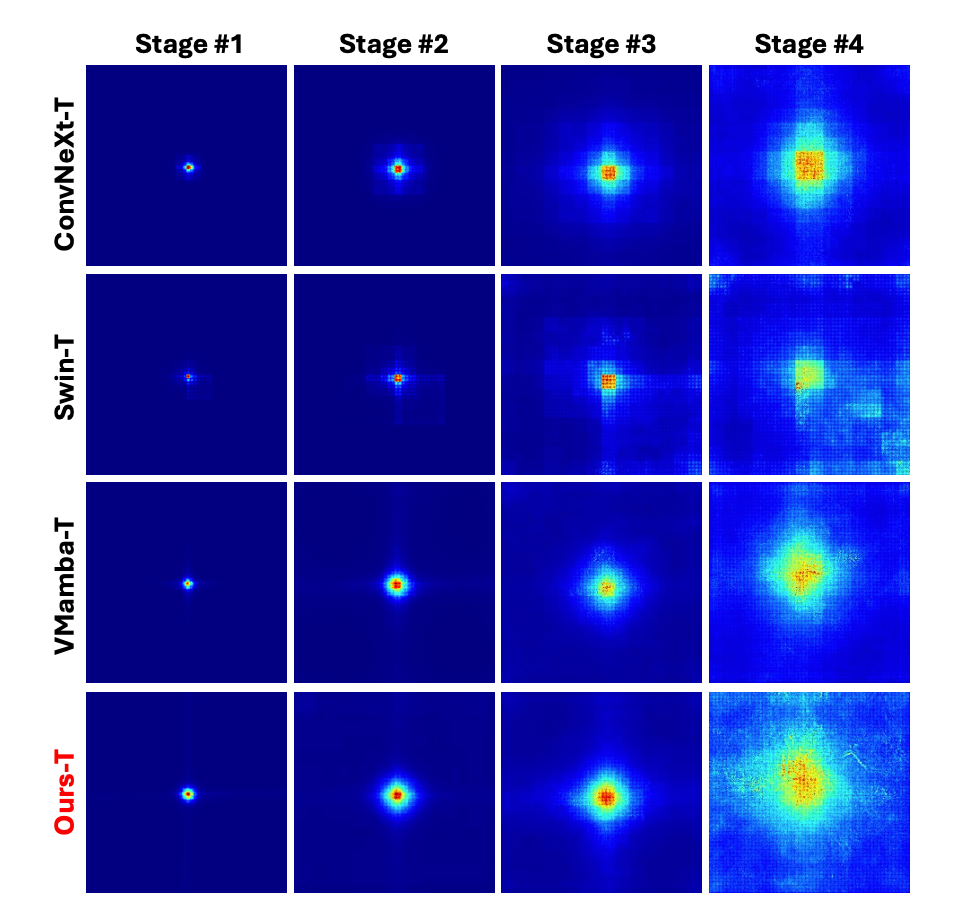
▲图4. Effective Receptive Fields可视化
-
开源
+关注
关注
3文章
3363浏览量
42544 -
连接
+关注
关注
2文章
96浏览量
20987 -
Vision
+关注
关注
1文章
198浏览量
18202
原文标题:AAAI 2025 | 港大提出SparX:强化Vision Mamba和Transformer的稀疏跳跃连接机制
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Mamba入局图像复原,达成新SOTA


HTC新头显Vive Focus Vision:强化混合现实体验
港迪技术IPO上市丨提升综合管理水平,强化公司持续经营能力
Transformer能代替图神经网络吗
Transformer语言模型简介与实现过程
Transformer架构在自然语言处理中的应用
使用PyTorch搭建Transformer模型
Transformer 能代替图神经网络吗?

【Vision Board 创客营】Vision Board上的DAC实践
一文详解Transformer神经网络模型

Vision Mamba:速度与内存的双重突破
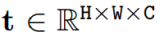





 工商网监
工商网监
评论