 基于Arm Neoverse平台的处理器革新生成式AI体验
基于Arm Neoverse平台的处理器革新生成式AI体验

作者:Arm 基础设施事业部 AI 解决方案架构师 Na Li
(Arm 工程部技术总监 Milos Puzovic 和 Arm 基础设施事业部软件工程师 Nobel Chowdary Mandepudi 参与了本文撰写)
Llama 是一个专为开发者、研究人员和企业打造的开源大语言模型 (LLM) 库,旨在推动生成式 AI 的创新、实验及可靠地扩展。Llama 3.1 405B 是 Llama 系列中性能领先的模型之一,然而部署和使用如此大型的模型对缺乏足够计算资源的个人或企业机构来说具有相当大的挑战。为了解决上述挑战,Meta 推出了 Llama 3.3 70B 模型。该模型在保持 Llama 3.1 70B 模型架构的同时,应用了最新的后训练技术以提升模型评估性能。同时,在推理、数学计算、常识理解、指令遵循和工具使用方面都有显著改进。尽管 Llama 3.3 70B 模型的体量显著减小,其性能却与 Llama 3.1 405B 模型相当。
Arm 工程团队与 Meta 紧密协作,在 Google Axion 上对 Llama 3.3 70B 模型进行了推理性能评估。Google Axion 是基于 Arm Neoverse V2 平台构建的定制 AArch64 处理器系列,通过 Google Cloud 提供。与传统的现成处理器相比,Google Axion 具备更高的性能、更低的能耗以及更强的可扩展性,充分满足了数据中心在 AI 时代的需求。
基准测试结果显示,在运行 Llama 3.3 70B 模型时,基于 Axion 处理器的 C4A 虚拟机 (VM) 可提供顺畅的 AI 体验,并在不同的用户批次大小下均达到了人类可读性水平,即人们阅读文本的平均速度,从而使开发者在基于文本的应用中,在获得与使用 Llama 3.1 405B 模型结果相当的高质量输出的同时,显著降低了对大量算力资源的需求。
Google Axion 处理器上运行
Llama 3.3 70B 的 CPU 推理性能
Google Cloud 提供的基于 Axion 的 C4A 虚拟机,最多可配备 72 个虚拟 CPU (vCPU) 和 576 GB RAM。在这些测试中,我们使用了中档高性价比的 c4a-standard-32 机器类型来部署 4 位量化的 Llama 3.3 70B 模型。为了运行我们的性能测试,我们使用了流行的 Llama.cpp 框架,该框架从 b4265 版本开始,已通过 Arm Kleidi 进行了优化。Kleidi 集成提供了优化的内核,以确保 AI 框架可以充分发挥 Arm CPU 的 AI 功能和性能。下面,我们来看看具体结果。
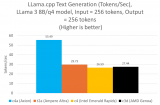
提示词编码速度是指语言模型处理和解释用户输入的速度。如图 1 所示,由于提示词编码利用了多核并行处理技术,因此在不同批次大小的测试中,其性能始终稳定在每秒约 50 个词元左右。此外,不同提示词规模测得的速度也相当。
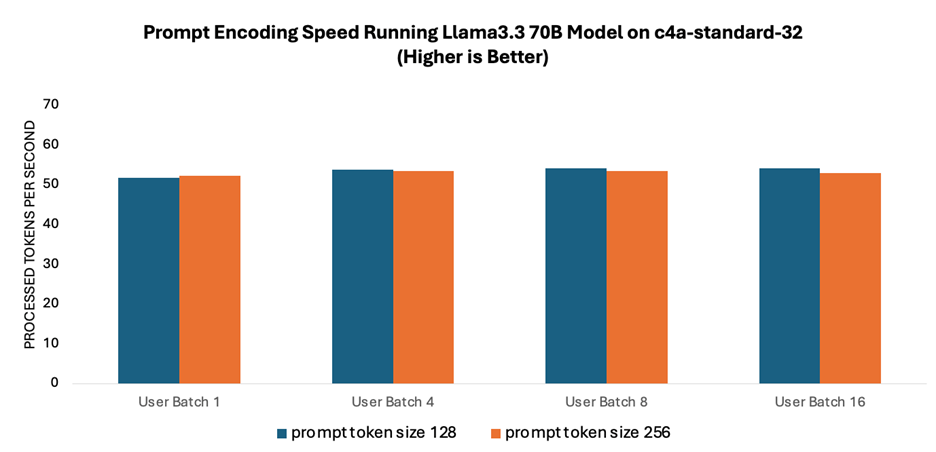
图 1:运行 Llama 3.3 70B 模型时的提示词编码速度
词元生成速度衡量的是运行 Llama 3.3 70B 模型时模型生成响应的速度。Arm Neoverse CPU 利用先进的 SIMD 指令(如 Neon 和 SVE)优化机器学习 (ML) 工作流,可加速通用矩阵乘法 (GEMM)。为了进一步提高吞吐量,尤其是在处理更大批次时,Arm 引入了专门的优化指令,如有符号点积 (SDOT) 和矩阵乘法累加 (MMLA)。
如图 2 所示,随着用户批次大小的增加,词元生成的速度相应提升,而在不同词元生成规模下测得的速度保持相对一致。这种在更大批次下实现更高吞吐量的能力,对于构建高效服务多用户的可扩展系统至关重要。
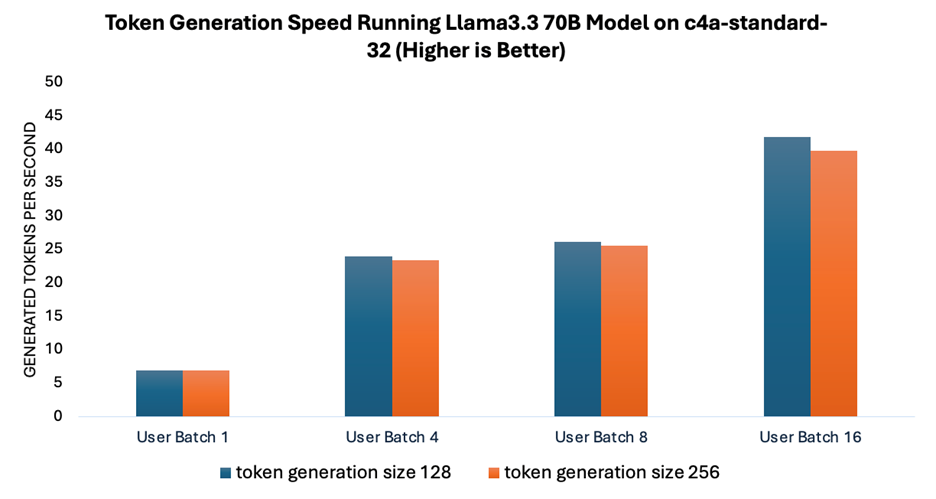
图 2:运行 Llama 3.3 70B 模型时的词元生成速度
为了评估多用户同时与模型交互时每个用户所感受到的性能,我们测量了每批次词元的生成速度。每批次词元的生成速度至关重要,因为这直接影响用户与模型交互时的实时体验。
如图 3 所示,当批次大小最多 4 时,词元生成速度可实现人类可读性的平均水平。这表明,随着系统扩展以满足多用户需求,其性能仍然保持稳定。为应对更多并发用户的需求,可以采用 vLLM 等服务框架。这些框架通过优化 KV 缓存管理显著提高了系统的可扩展性。
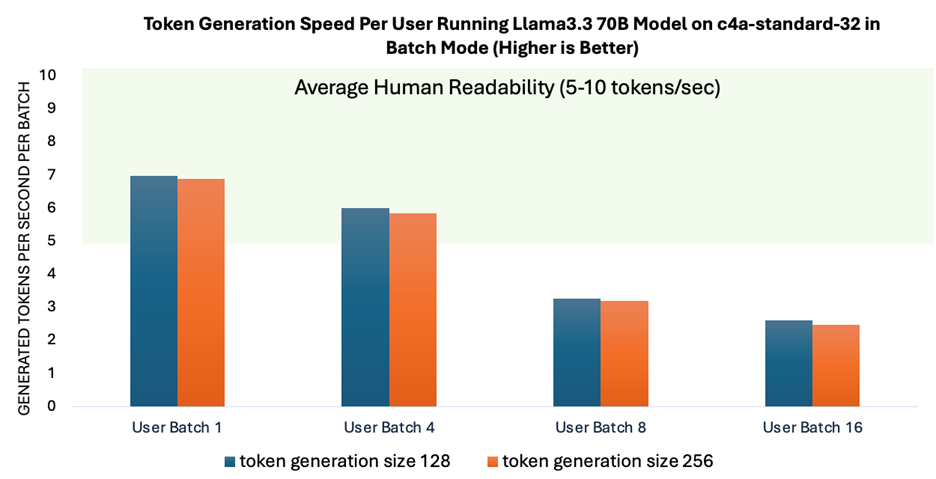
图 3:不同批次大小下,以批次模式运行 Llama 3.3 70B 模型时每个用户的提示词生成速度与人类可读性的平均水平的对比
革新生成式 AI 体验
Llama 3.3 70B 模型能够高效地发挥大规模 AI 的优势,预示着潜在的变革。由于 Llama 3.3 70B 模型使用较小的参数规模,不仅使生成式 AI 处理技术更容易被生态系统采用,同时也减少了所需的计算资源。此外,Llama 3.3 70B 模型有助于提高 AI 的处理效率,这对于数据中心和云计算工作负载至关重要。在模型评估基准方面,Llama 3.3 70B 的性能也与 Llama 3.1 405B 模型相当。
通过基准测试工作,我们展示了基于 Arm Neoverse 平台的 Google Axion 处理器在运行 Llama 3.3 70B 模型时可提供流畅高效的体验,并在多个用户批次大小测试中实现了与人类可读性水平相当的文本生成性能。
我们很荣幸能继续与 Meta 保持密切的合作关系,在 Arm 计算平台上实现开源 AI 创新,从而确保 Llama LLM 跨硬件平台顺畅、高效地运行。
-
处理器
+关注
关注
68文章
20368浏览量
255533 -
ARM
+关注
关注
135文章
9608浏览量
394147 -
Neoverse
+关注
关注
0文章
17浏览量
5003 -
生成式AI
+关注
关注
0文章
538浏览量
1141
原文标题:在基于 Arm Neoverse 平台的处理器上实现更高效的生成式 AI
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
向Intel发起重型计算挑战 ARM发布Neoverse 处理器
基于NXP iMX6Q ARM处理器的Apalis iMX6Q ARM嵌入式平台
Arm Neoverse N1软件优化指南
ARM推出了一个名叫Neoverse的处理器家族,叫板Intel
浅谈arm处理器的优势
Arm推出Neoverse处理器家族 大有对标Intel之势
ARM推出新一代Neoverse处理器平台,面向5nm及3nm工艺性能提升30%以上
Arm推出新一代平台 Neoverse V2 平台
Arm发布新一代Neoverse数据中心计算平台,AI负载性能显著提升
Google Cloud推出基于Arm Neoverse V2定制Google Axion处理器
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3

Arm技术助力Google Axion处理器加速AI工作负载推理
如何在基于Arm Neoverse平台的CPU上构建分布式Kubernetes集群



评论