 国产大模型DeepSeek推出DeepSeek-V3
国产大模型DeepSeek推出DeepSeek-V3
众所周知,过去一年间,大语言模型(LLM)领域经历了翻天覆地的变化...
回望2023年底,OpenAI的GPT-4还是一座难以逾越的高峰,其他AI实验室都在思考同一个问题:OpenAI究竟掌握了哪些独特的技术秘密?
一年后的今天,形势已发生根本性转变,据Chatbot Arena排行榜显示,原始版本的GPT-4(GPT-4-0314)已跌至第70位左右。目前,已有18家机构的70个模型在性能上超越了这个曾经的标杆。
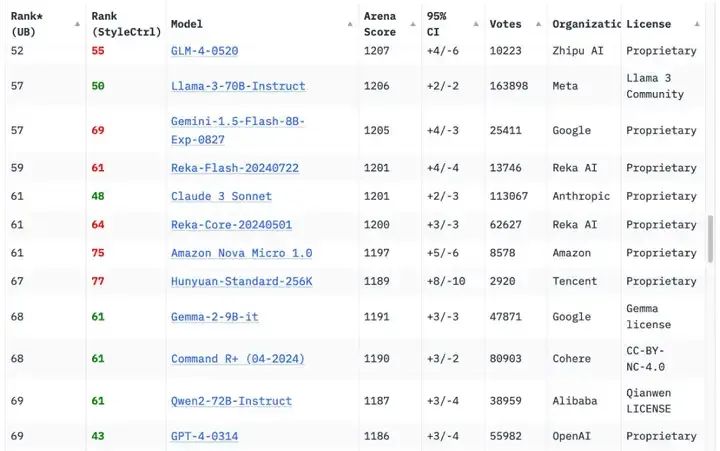
图源:Chatbot Arena
随着2025年的崭新启航,是否意味着AI圈的一颗“王炸”已悄然“引爆”?
近日,国产大模型DeepSeek推出DeepSeek-V3,一个强大的混合专家(Mixture-of-Experts, MoE)语言模型,DeepSeek-V3拥有高达6710亿的参数规模,但每次推理仅激活370亿参数。
尤其,当o1、Claude、Gemini和Llama 3等模型还在为数亿美元的训练成本苦恼时, DeepSeek-V3用557.6万美元的预算,在2048个H800 GPU集群上仅花费3.7天/万亿tokens的训练时间,就达到了足以与它们比肩的性能 。
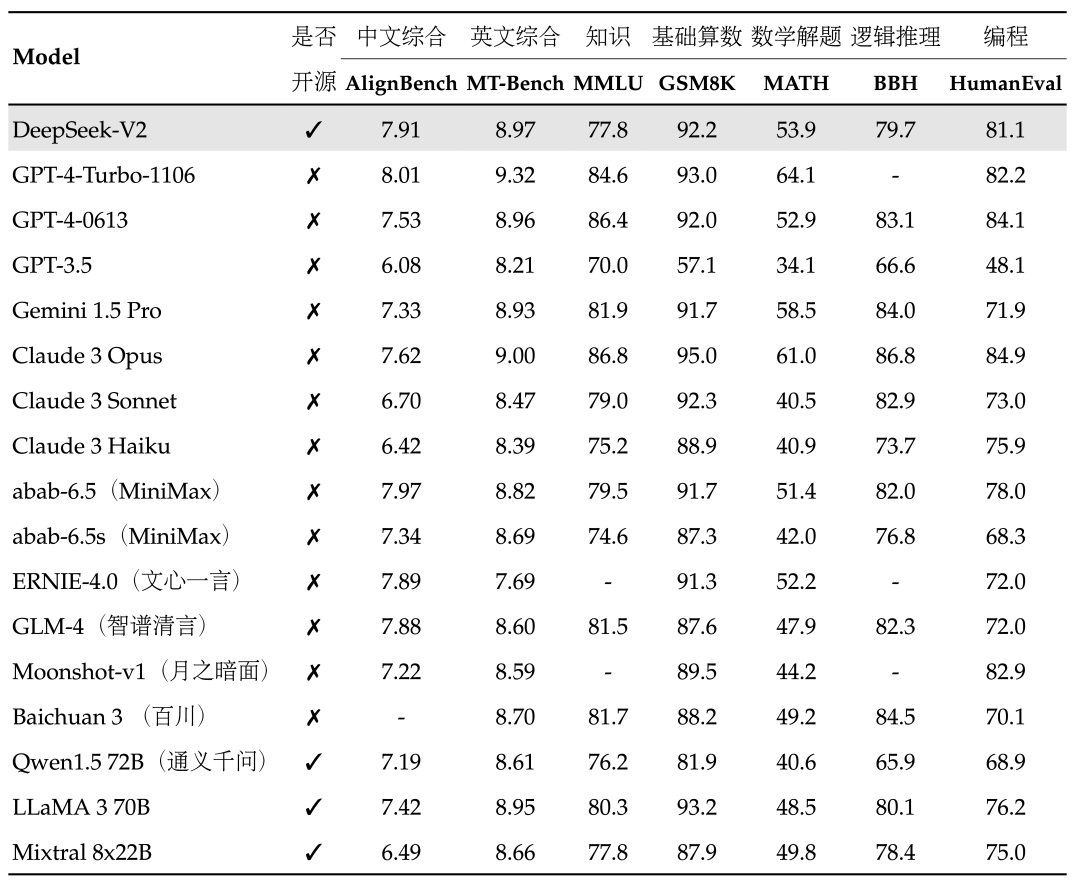
与此同时,DeepSeek-V3相比其他前沿大模型,性能却足以比肩乃至更优。
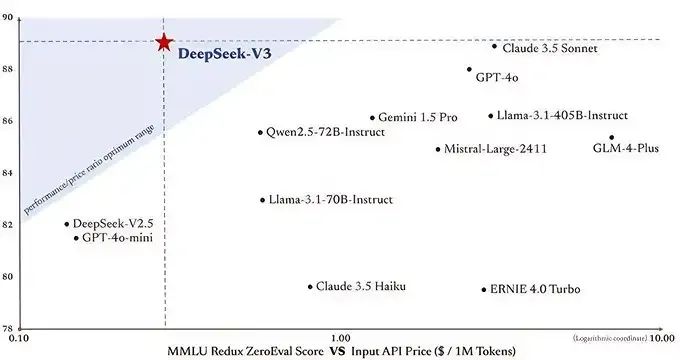
DeepSeek-V3与其他大模型性能对比
其中,这种设计使得模型在性能和效率上实现了完美平衡,在多项模型测评中,DeepSeek-V3不仅超越了Llama 3.1 405B等顶级开源模型,更在代码、数学、长文本处理等领域,与GPT-4o和Claude 3.5 Sonnet等闭源模型分庭抗礼。
其次,通过671B的总参数量,在每个token激活37B参数的精准控制下,DeepSeek-V3用14.8万亿高质量多样化token,构建出了一个能够超越所有开源模型,直逼GPT-4和Claude-3.5的AI巨人。
另外,在基础理解能力测试中,DeepSeek-V3与Claude-3.5模型面对中文脑筋急转弯“小明的妈妈有三个孩子”的问题,DeepSeek V3表现出色,不仅答对还进行了自我验证。但在英文双关语“April Fool's Day”的测试中则略显不足,未能理解其中的语言巧思,而Claude3.5Sonnet则轻松应对。
DeepSeek-V3与Claude-3.5实测对比
除此之外,DeepSeek自言,这得益于采用了Multi-head Latent Attention (MLA)和DeepSeek MoE架构,实现了高效的推理和经济高效的训练。
Multi-head Latent Attention (MLA):MLA 通过对注意力键和值进行低秩联合压缩,减少了推理时的 KV 缓存,同时保持了与标准多头注意力(MHA)相当的性能。
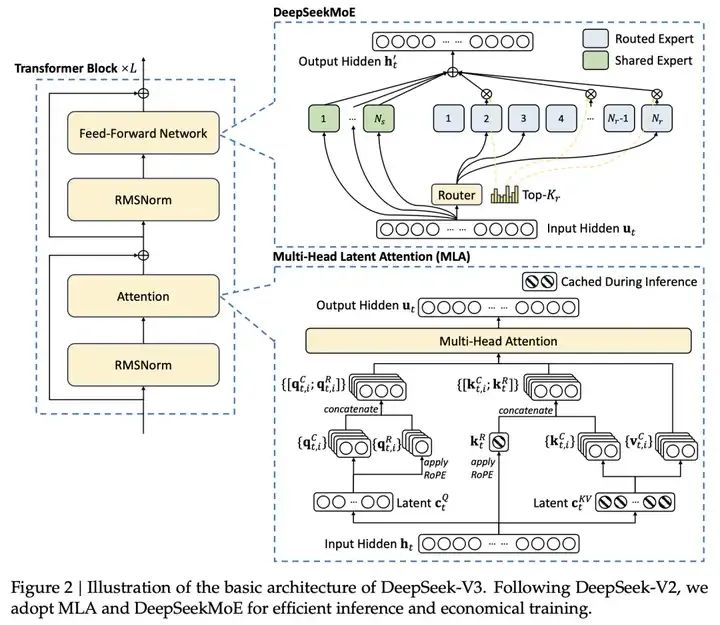
DeepSeek-V3 的核心亮点
DeepSeekMoE:DeepSeekMoE 采用了更细粒度的专家分配策略,每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个令牌激活 8 个专家,确保了计算的高效性。
因此,在系统架构层面,DeepSeek就使用了专家并行训练技术,通过将不同的专家模块分配到不同的计算设备上同时进行训练,提升了训练过程中的计算效率。
DeepSeek探索出一个精妙的解决策略,不等到最后再算总和,而是每加128个数就把当前结果转移到科学计算器上继续计算。其过程不影响速度,此技术利用了H800 GPU的特点:就像有两个收银员,当一个在结算购物篮的同时,另一个便可继续扫描新商品。
这一策略使得模型训练速度大幅提升,毕竟核心计算能提升100%的速度,而显存使用减少也非常明显,并且模型最终的效果精度损失能做到小于0.25%,几乎无损。
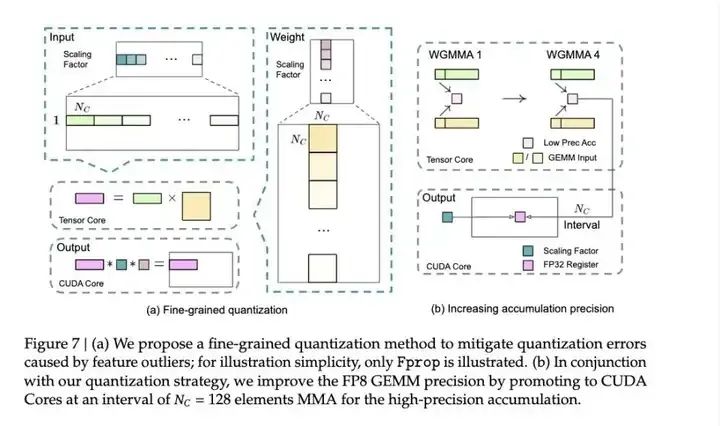
DeepSeek 提出的误差积累解决方法
但由于DeepSeek“大方”开源,Open AI水灵灵地被网友cue进行横向对比,有一种被push的支配感。
Scale AI创始人亚历山大·王 (Alexander Wang)更表示,DeepSeek-V3带来的辛酸教训是:当美国休息时,中国在工作,以更低的成本、更快的速度迎头赶上,变得更强。
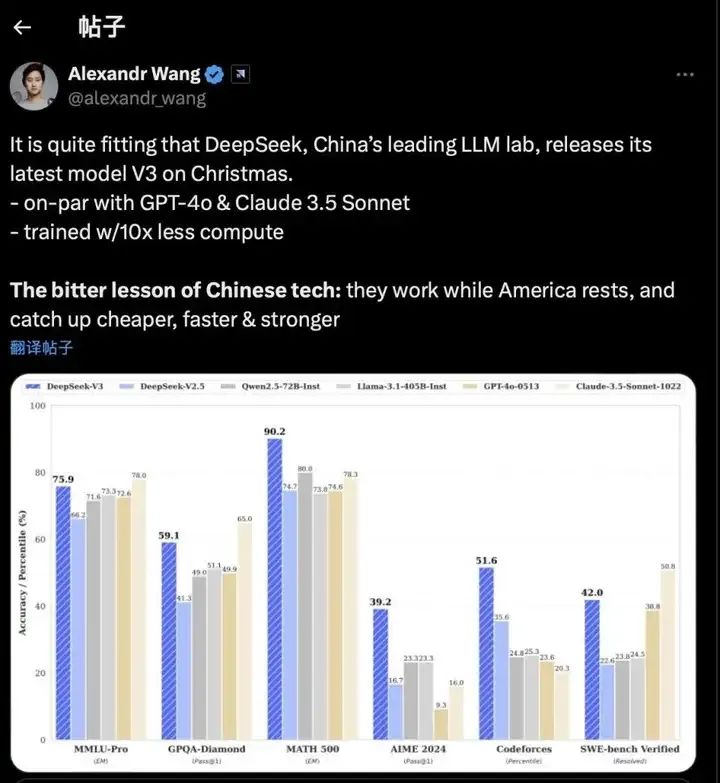
图源:X平台
简言之,这种剧变深刻折射出AI领域的变革。在2023年,超越GPT-4还是一个值得载入史册的重大突破,转眼至2024年,这一成就已然演变为衡量顶级AI模型的基准线。
而刚到来的2025年,DeepSeek用行动说明,中国大模型创业者,共同参与这场全球创新AI竞赛中。
由于篇幅受限,本次的DeepSeek V3就先介绍这么多......
想了解更多半导体行业动态,请您持续关注我们。
-
开源
+关注
关注
3文章
3368浏览量
42567 -
LLM
+关注
关注
0文章
293浏览量
352
原文标题:DeepSeek-V3横空出世,GPT-4时代终结?
文章出处:【微信号:奇普乐芯片技术,微信公众号:奇普乐芯片技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谈谈DeepSeek-v3提到的基础设施演进
雷军千万年薪挖角95后AI天才少女 DeepSeek开源大模型DeepSeek-V2关键开发者之一罗福莉
国产大模型发展的经验与教训

中国AI企业创新降低成本打造竞争力模型
零一万物正式开源Yi-Coder系列模型 PerfXCloud火速支持等你体验!
PerfXCloud顺利接入MOE大模型DeepSeek-V2

斯坦福团队抄袭国产大模型,主要责任人失联
Meta推出最强开源模型Llama 3 要挑战GPT
国产GPU在AI大模型领域的应用案例一览






 工商网监
工商网监
评论