 先进封装技术-19 HBM与3D封装仿真
先进封装技术-19 HBM与3D封装仿真
先进封装技术(Semiconductor Advanced Packaging) - 1 混合键合技术(上)
先进封装技术(Semiconductor Advanced Packaging) - 2 混合键合技术(下)
先进封装技术(Semiconductor Advanced Packaging) - 3 Chiplet 异构集成(上)
先进封装技术(Semiconductor Advanced Packaging) - 4 Chiplet 异构集成(下)
先进封装技术(Semiconductor Advanced Packaging) - 5 TSV 异构集成与等效热仿真
先进封装技术(Semiconductor Advanced Packaging) - 6 扇出型晶圆级封装(FOWLP)
先进封装技术(Semiconductor Advanced Packaging) - 7 扇出型板级封装(FOPLP)
先进封装技术(Semiconductor Advanced Packaging) - 8 3D封装与TSV技术
先进封装技术(Semiconductor Advanced Packaging) - 9 堆叠封装(PoP)技术
先进封装技术(Semiconductor Advanced Packaging) - 10 2.5D封装与异构集成技术
先进封装技术(Semiconductor Advanced Packaging) - 11 SiP 系统级封装
先进封装技术(Semiconductor Advanced Packaging) - 12 表面贴装技术 SMT
先进封装技术(Semiconductor Advanced Packaging) - 13 倒装封装 Flip Chip
先进封装技术(Semiconductor Advanced Packaging) - 14 光电共封技术(CPO) (上)
先进封装技术(Semiconductor Advanced Packaging) - 15 光电共封技术(CPO) (下)
先进封装技术(Semiconductor Advanced Packaging) - 16 硅桥技术(Si Bridge)(上)
先进封装技术(Semiconductor Advanced Packaging) - 17 硅桥技术(Si Bridge)(下)
先进封装技术(Semiconductor Advanced Packaging) - 18 TGV 玻璃通孔技术
HBM的结构
当代电子计算机的性能表现依赖于 CPU 和 DRAM 的协同配合,在计算机架构中,计算处理单元根据指令从内存中读取数据,完成计算处理后将数据存回内存。目前主流 CPU 的主频高达 5GHz,而 DRAM内存性能取决于电容充放电速度以及 DRAM 与 CPU之间的接口带宽。在高性能计算、数据中心、AI 应用中,顶级高算力芯片的数据吞吐量峰值在数百TB/s级别,但主流 DRAM 内存或显存带宽一般为几GB/s到几十GB/s量级,与TB/s量级还有较大差距。DRAM 内存带宽已经成为了制约计算机性能发展的重要瓶颈,即所谓阻碍性能提升的内存墙。
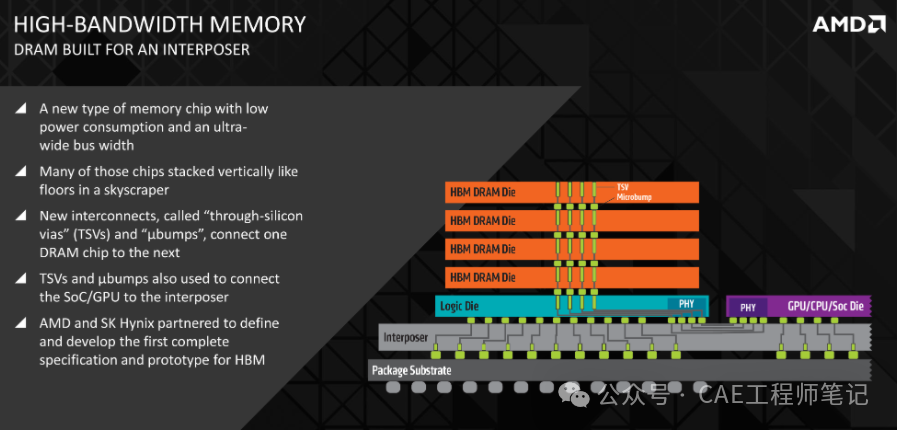
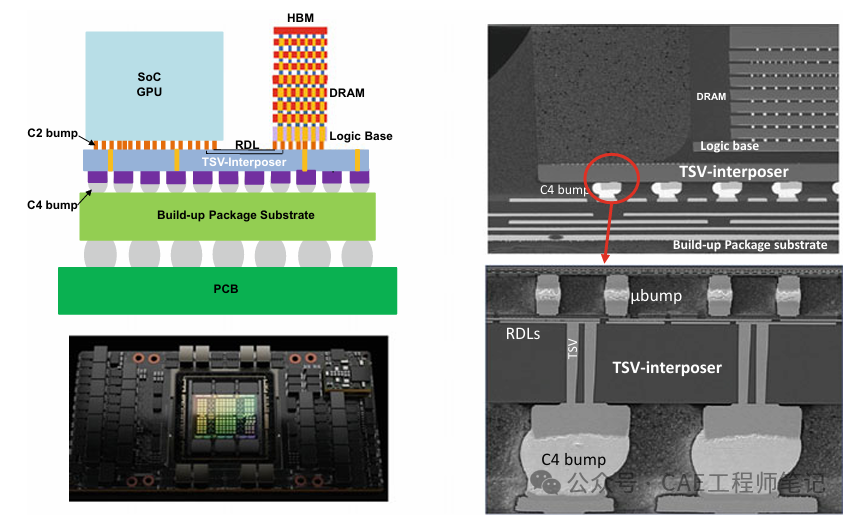
HBM 堆叠结构如上图所示,包含多层 DRAM 芯片和一层基本逻辑芯片。4层或8层甚至更多层数的 DRAM 芯片以堆叠形式整合在一起,不同 DRAM 芯片之间以及 DRAM 芯片与逻辑芯片之间用 TSV 和微凸块技术实现通道连接。每个 HBM DRAM 芯片可通过多达 8 条通道与外部相连,每个通道可单独访问1 组 DRAM 阵列,通道间访存相互独立。逻辑芯片可控制 DRAM 芯片,并提供与控制器芯片连接的接口,主要包括测试逻辑模块和 PHY 模块,其中 PHY 接口通过中间介质层与 CPU/GPU/SoC 直接高速连通,直接存取端口提供 HBM 中多层 DRAM 芯片的测试通道。中间介质层通过微凸块连接到封装基板,从而形成 SiP 系统。
HBM 堆栈没有以外部互连线的方式与信号处理器芯片连接,而是通过中间介质层紧凑而快速地连接,同时 HBM 内部的不同 DRAM 采用 TSV 实现信号纵向连接,HBM 具备的特性几乎与片内集成的RAM 存储器一样。
HBM 具有可扩展更大容量的特性。HBM 的单层DRAM芯片容量可扩展。HBM通过4层、8层以至12层堆叠的 DRAM 芯片,可实现更大的存储容量。HBM可以通过 SiP 集成多个 HBM 叠层 DRAM 芯片,从而实现更大的内存容量。
HBM 由于采用了 TSV 和微凸块技术,DRAM 裸片与处理器间实现了较短的信号传输路径以及较低的单引脚I/O速度和I/O电压,使 HBM 具备更好的内存功耗能效特性。
HBM 将原本在 PCB 板上的DDR 内存颗粒和 CPU 芯片一起全部集成到SiP 里,因此 HBM 在节省产品空间方面也更具优势。
从 HBM1 到 HBM4 的技术发展
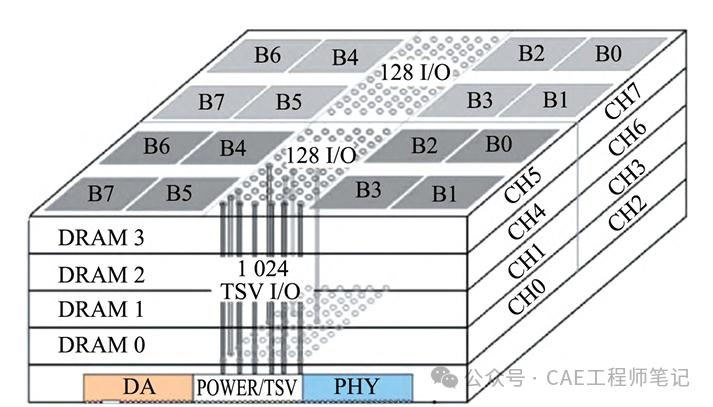
2013 年 10 月,JEDEC 发布了第一个 HBM 标准JESD235。JESD235 标准定义了具有 1024bit 接口和单引脚 1Gbit/s 数据速率的 HBM1 存储芯片,该芯片堆叠了 2个或4个 DRAM,HBM1 堆叠 DRAM 架构如下图所示,在基本逻辑芯片上,每个 DRAM 芯片具有 2个128bit 通道,共有8个阵列(B0~B7),最多支持 8个128bit 通道(CH0~CH7),总带宽为128GB/s。每个通道实质上是具有 2n 预取架构的 128 bit DDR 存储器接口,主要包括128 bit数据、8 bit 行命令地址和 6bit 列命令地址、源同步时钟、校验、数据屏蔽等信号,还包括复位、IEEE1500 测试端口和电源等公共信号。访存的读、写操作过程基本与DDR存储器芯片相同。HBM1 芯片具备半独立的行、列命令接口,支持读、写命令与其他命令并行执行,增加了命令接口带宽,提高了访存性能。
2014年,SK Hynix 与 AMD 联合开发了全球首款 HBM 产品。HBM1 的工作频率约为 1600Mbps,漏极电源电压为 1.2V,芯片密度为 2Gb。HBM1 的带宽高于 DDR4和GDDR5 产品,同时以较小的外形尺寸消耗较低的功率,更能满足 GPU 等带宽需求较高的处理器。AMD 采用 HBM1 构建了其GPU 系统封装和 RadeonR9Fury/R9Nano 视频卡。

2018 年 11 月,JEDEC 在 JESD235A 的基础上发布了 JESD235B 标准,即HBM2 技术。HBM2 充分融入了I/O高带宽存储技术、TSV工艺,支持最多12层的TSV堆叠,单片容量达到 16Gbit,使用 1024bit 总线,分成 8个相互独立的 128bit 通道,单引脚数据速率提升到 2.4Gbit/s,总带宽达到 307GB/s。HBM2 可以在全带宽下支持 2层、4层、8层和12层的 TSV堆栈,从而使系统在容量要求方面具有灵活性,堆栈容量为1GB和24GB。
相对于 SK Hynix 主导研发的 HBM1 存储芯片,三星、镁光等公司也都推出HBM2产品,且三星更为领先。
2020 年 1 月,JEDEC 更新发布 HBM 技术标准JESD235C,并于 2021 年 2 月更新为 JESD235D,以支持增加的带宽和容量,即 HBM2E。按照HBM2E 技术规范,单片最大容量为 16Gbit,支持 2层、4层、8层和12层的 TSV 堆栈,无标准高度限制,最大堆栈容量为 24GB,单引脚的数据传输速率提升到 3.2Gbit/s,匹配 1024bit 总线,单堆栈理论最大带宽为410GB/s。
2020 年,三星推出 Flashbolt HBM2E 内存,堆叠 8个 16Gbit DRAM 芯片,使用 TSV 技术实现 8 芯片堆栈配置互连。
2022 年 1 月,JEDEC 发布了 HBM3 高带宽内存标准 JESD238,即第四代 HBM 技术。HBM3在带宽、通道、存储密度、可靠性、能效等层面进行了扩充升级。定义了高达 6.4Gbit/s的数据传输速率,相当于819GB/s。将独立通道的数量从 HBM2 的8个增加到16个。支持4层、8层和12层 TSV 堆栈,并为未来扩展至 16层TSV堆栈做好了准备,支持8~32Gbit的单层存储容量,堆栈容量为 4~64GB。HBM3 引入了 ECC 技术,支持实时错误报告,满足更高级平台的可靠性、可用性和可维护性需求。I/O电压降低至1.1V,能效进一步提升。

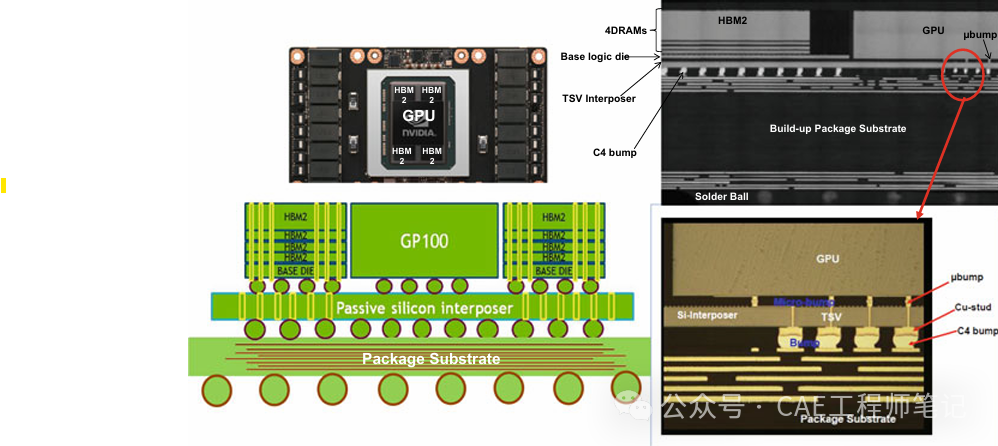
在 HBM3标准推出前,SK Hynix 就推出了 HBM3内存。SK Hynix 在 2021 年 10 月开发出全球首款 HBM3,容量是 HBM2E 的1.5倍,由 12个 DRAM 芯片堆叠成,总封装高度相同,适用于AI、HPC等容量密集型应用。如下图所示,Nvida H100 是世界上第一个正式使用 HBM3 技术的芯片。
目前,JEDEC 即将发布 HBM4 标准,与 HBM3 相比,HBM4 将每个堆栈的通道数增加一倍,并且物理占用空间更大。为了支持设备兼容性,该标准确保单个控制器可以在需要时同时与 HBM3 和 HBM4 配合使用。不同的配置将需要不同的中介层来适应不同的封装。HBM4 将指定 24 Gb 和 32 Gb 层,并可选择支持 4 层、8 层、12 层和 16 层 TSV 堆栈。

HBM 的迭代和制造已经开启竞速模式。有消息称,为了配合英伟达的新品发布节奏,SK Hynix 原计划 2026 年量产的 HBM4,将提前至 2025 年下半年量产,采用台积电 3nm 制程。三星也被传出计划在 2025 年年底完成 HBM4 开发后立即开始大规模生产,目标客户包括微软和Meta。
HBM 3D 封装仿真
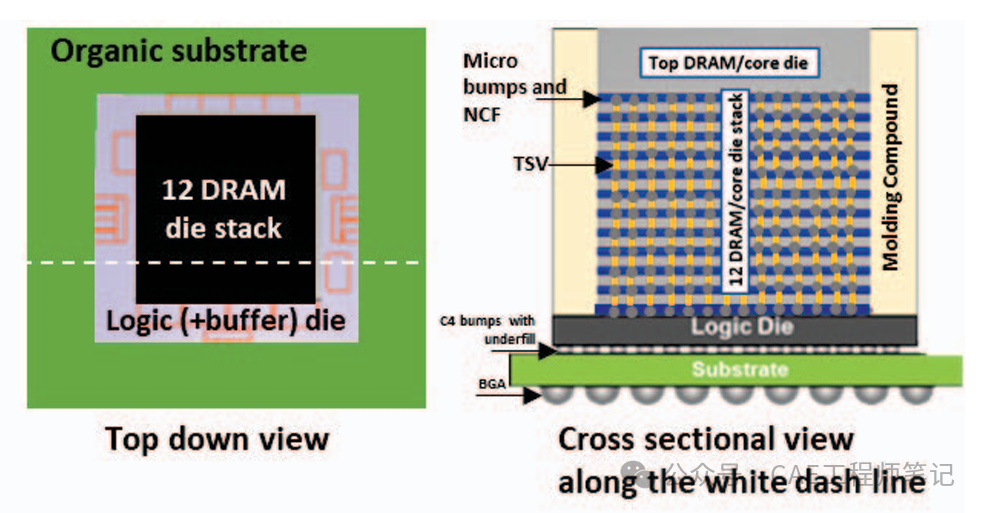
下图所示为 CASE 中模拟的单个 3D 堆叠封装 HBM。有 12 个 DRAM 芯片堆叠在逻辑芯片的顶部。基础逻辑芯片顶部有模塑料,围绕着 12 个 DRAM 芯片堆栈,单个 HBM 通过 C4 凸块或带有底部填充的铜柱微凸块连接到有机基板上。有机基板具有多层有机堆积膜和 Cu 层,BGA 焊球位于有机基板的底部,用于 PCB 表面贴装。
稳态热仿真使用 Cadence 的 Celsius Electronic Cooling 工具进行设置和执行。
如下图所示,逻辑芯片尺寸为 15×15 mm,在长度和宽度上比 HBM 芯片尺寸大 5 mm。HBM 芯片堆栈仅略微远离逻辑芯片顶部的中心。TIM 材料直接连接到 HBM 芯片堆栈顶部的裸芯片上,并连接到顶部的冷板上。

如下图所示,逻辑芯片的总功耗为 47 W,HBM 内核芯片堆栈的总功耗为 15 W,因此封装的总功耗为 62 W。
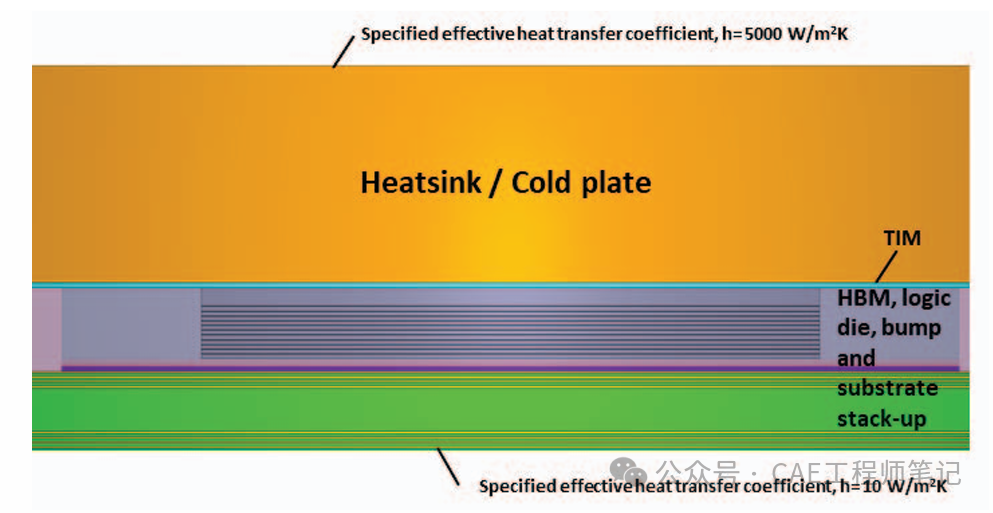
边界条件根据几何顶部和底部表面的有效传热系数设置,考虑到液体冷却,冷板顶部的有效传热系数为 5000 W/m2K,液体入口温度为 32度,基板底部为 10 W/m2K。
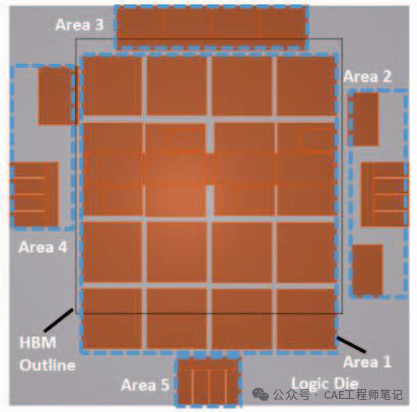
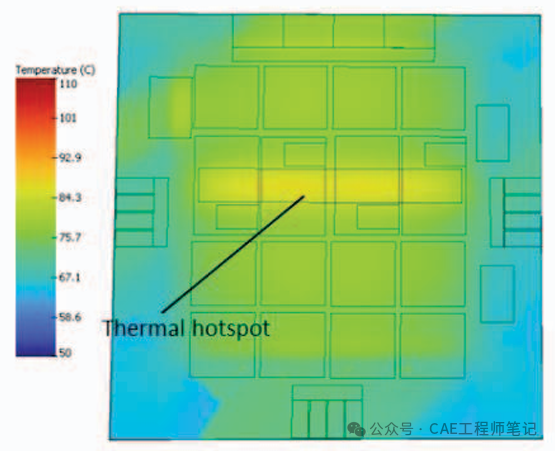
热仿真有助于定位逻辑芯片内部的热点。如下图所示,热点出现在逻辑芯片的边缘,这主要是因为,与中心区域相比,边缘区域在较小的区域集中了更多的功率,并且在中心区域,HBM 堆栈通过直接传导到连接到冷板的 TIM 带走热量,然而,对于边缘,传导路径主要通过不提供高导热性的成型材料。
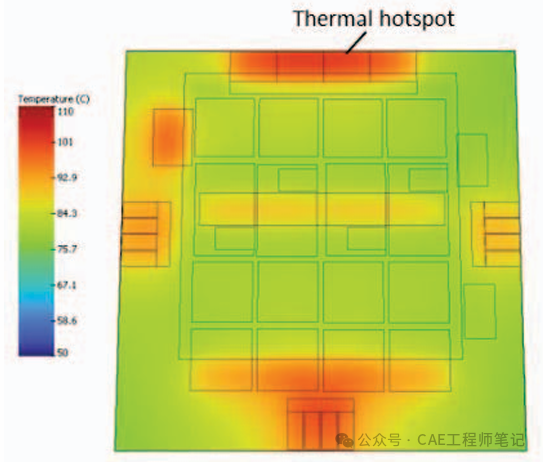
如下图所示,将冷板顶部的传热系数增加到 10000 W/m2K 后,热点温度降低了 15.74%,热点仍然出现在边缘。
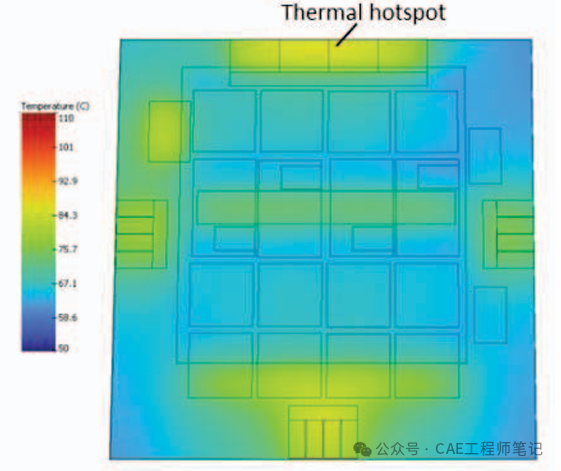
如下图所示,在逻辑芯片顶部添加dummy die有助于将温度降低 14.75%,并使温度更均匀地分布在逻辑芯片上,HBM 下方的区域比其他区域略热。
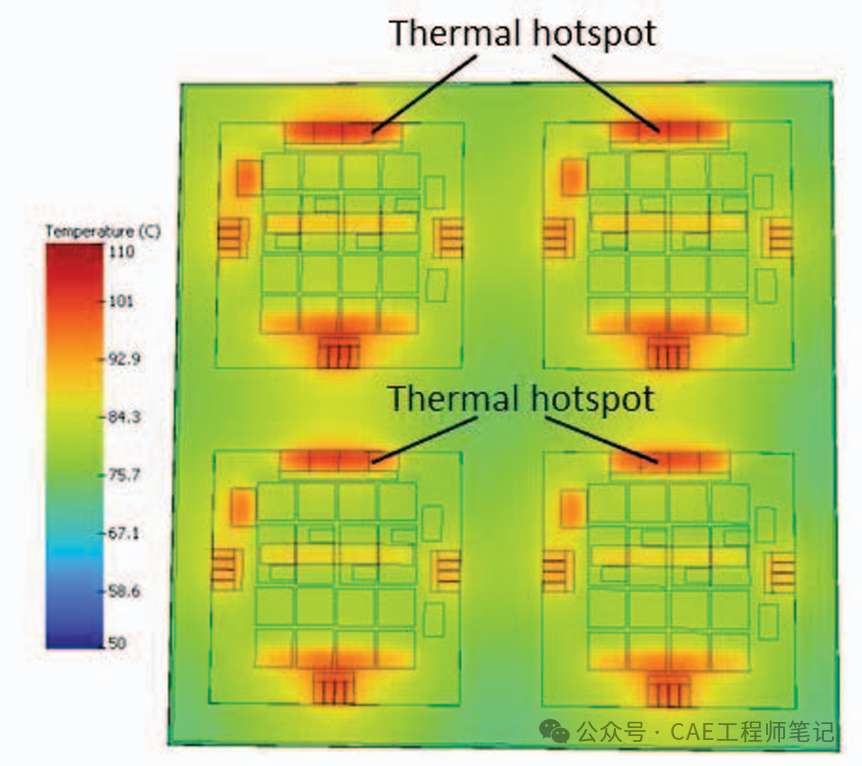
如下图所示,在四个 HBM 的情况下,热点仍然出现在逻辑芯片的边缘,但与一个 HBM 的情况相比,热点的绝对温度实际上降低了 1%。这是因为该封装的基板、TIM 和冷板尺寸较大,从逻辑芯片带走了更多的热量。
事实证明热仿真技术在预测热点方面是卓有成效的,因此可以通过更新冷却解决方案或封装结构来提出进一步的改进方案。
-
仿真
+关注
关注
50文章
4099浏览量
133719 -
3D封装
+关注
关注
7文章
135浏览量
27149 -
HBM
+关注
关注
0文章
384浏览量
14779 -
先进封装
+关注
关注
2文章
417浏览量
262
原文标题:先进封装技术(Semiconductor Advanced Packaging) - 19 HBM与3D封装仿真
文章出处:【微信号:深圳市赛姆烯金科技有限公司,微信公众号:深圳市赛姆烯金科技有限公司】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐


AD16的3D封装库问题?
3D IC先进封装对EDA的挑战及如何应对
7.2小时完成868个HBM封装端口——Cadence Clarity 3D Solver仿真案例详解
基于HFSS的3D多芯片互连封装MMIC仿真设计
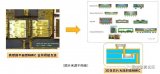
什么是先进封装?先进封装技术包括哪些技术





 工商网监
工商网监
评论