 利用Multi-Die设计的AI数据中心芯片对40G UCIe IP的需求
利用Multi-Die设计的AI数据中心芯片对40G UCIe IP的需求
越来越多的日常设备开始部署生成式人工智能,市场对大语言模型和出色算力的需求也随之日益增长。Yole Group在2024年OCP区域峰会的演讲过程中表示:“对于训练参数达到1750亿的GPT-3,我们估计需要6000到8000个A100 GPU历时长达一个月才能完成训练任务。”不断提高的HPC和AI计算性能要求正在推动Multi-Die设计的部署,将多个异构或同构裸片集成到一个标准或高级封装中。为了快速可靠地处理AI工作负载,Multi-Die设计中的Die-to-Die接口必须兼具稳健、低延迟和高带宽特性,最后一点尤为关键。本文概述了利用Multi-Die设计的AI数据中心芯片对40G UCIe IP的需求。
高带宽Die-to-Die接口用例
AI应用正在给半导体行业带来新的挑战。为支持深度学习和机器学习算法的海量数据处理任务,对更大带宽的需求不断增加,特别是对于计算和网络应用。这些AI应用对于Die-to-Die接口提出了不同的要求。本文以100Tb网络交换机和AI加速器为例。
图1为100Tb交换机示例,该交换机可用于AI数据中心,采用横向扩展方法来处理跨数据中心的海量数据。横向扩展方法在机器协同工作的网络中将工作负载分配到多台服务器上。交换机SoC不断扩展,正在接近尺寸极限,因此它被分割成更小的裸片,以提高边缘使用率。在这种情况下,Die-to-Die接口通过高速以太网在裸片之间以及向外界传输大量数据,反之亦然。
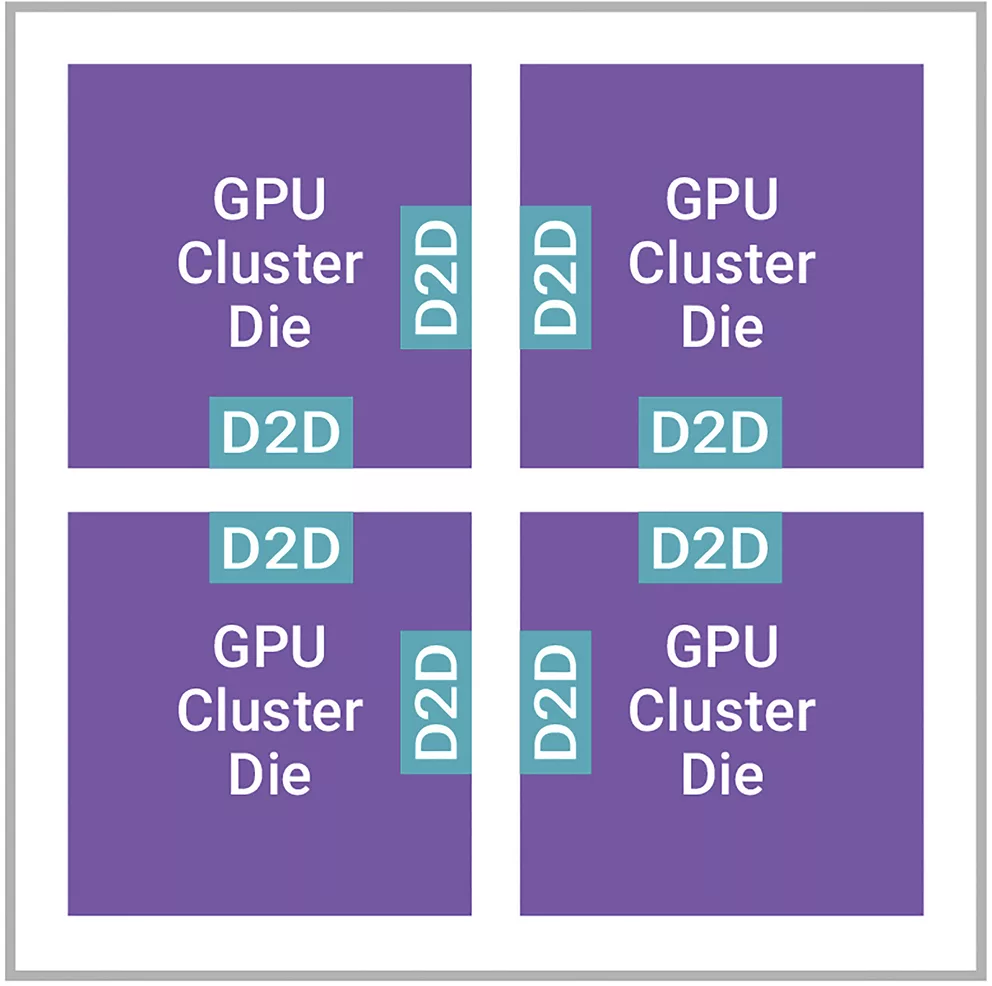
▲图1 100Tb交换机的裸片分割用例片
类似Google张量处理单元这样的AI加速器采用Multi-Die设计,为PCIe和以太网等接口配备单独的计算裸片和IO裸片。此类AI处理器在更主流的技术工艺上使用IO裸片来节省成本,并在更先进的技术工艺上使用计算裸片来提高性能和能效,从而充分发挥Multi-Die设计的优势。一些AI加速器使用图3所示的裸片分割方法,需要高带宽Die-to-Die接口来无缝传输裸片之间的数据。
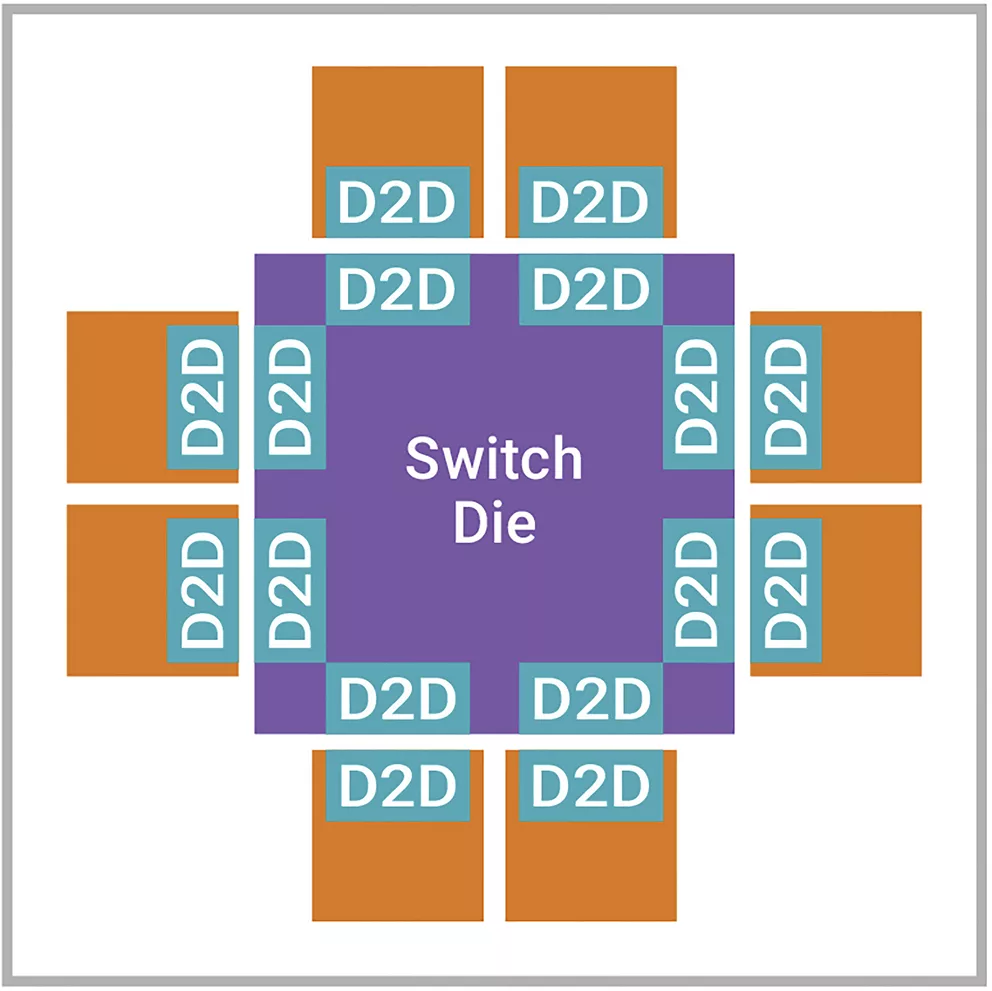
▲图2 使用AI加速器的裸片分割用例
另一个示例是裸片连接用例,其中主服务器裸片或处理器连接到AI加速器裸片,以便执行可分流到特定功能加速器的任务。在这种用例中,Die-to-Die接口用于在需要时将数据从服务器裸片发送到加速器裸片,而无需在高带宽下运行。此类用例使用标准封装技术(如有机衬底),复杂性较低。许多边缘AI和移动应用都使用此类用例。
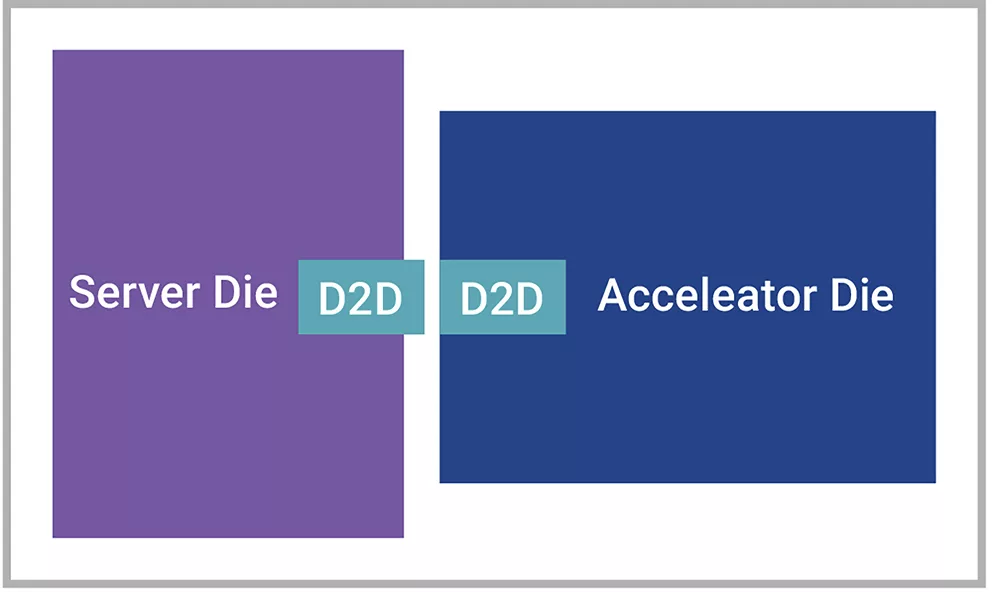
▲图3 裸片连接用例
利用40G UCIe IP为Die-to-Die连接提供最大带宽
UCIe规范已成为Die-to-Die连接的事实标准,确保裸片之间的互操作性、低延迟和实时数据传输。得益于UCIe,100Tb交换机和AI加速器等使用Multi-Die设计技术在标准封装和高级封装下实现了带宽效率更高。作为通用芯粒互联产业联盟(UCIe Consortium)的成员,新思科技在其当前经验证的UCIe IP基础上,推出了40G UCIe IP解决方案,可提供比UCIe规范高25%的带宽,而不会影响能效或面积。
40G UCIe PHY符合新的UCIe规范,实现了各种功能,可确保Die-to-Die链路可靠性和质量。PHY具有全面的可测性设计(DFT)功能,可用于已知良好裸片和生产测试,从而提高了可测试性。嵌入式信号完整性监视器(SIMs)可监测Die-to-Die链路的任务模式。监视器可以持续分析Die-to-Die信号质量,并在任务模式下执行校正措施,以实现可靠的通信。
PHY在2GHz频率下支持高达128B的接口宽度,可以利用整个PHY的带宽。对于必须以较低时钟频率运行的系统,它还在1GHz频率下支持更宽的256B接口。40G UCIe控制器支持不同的接口选项,例如流式传输、CXS、AXI,以及PCIe、CXL、AXI和CHI C2C等协议,以在Die-to-Die链路上运行标准化数据。
虽然更高的数据速率有助于AI应用实现高带宽效率并满足数据处理要求,但也带来了设计挑战。开发者必须精心设计通道规格,避免更高的插入损耗和串扰,以实现更优性能。速度较低时,可能不需要对发射器(TX)进行均衡处理。但在速度较高时,为了达到所需的信道性能,就需要进行TX均衡,比如使用2抽头前馈均衡(FFE)。此外还需要采用更强大的接收器(RX)均衡技术,例如1抽头决策反馈均衡(DFE)及连续时间线性均衡(CTLE)。Die-to-Die通道需经过大量的信号完整性和电源完整性仿真,以验证Die-to-Die链路特性和性能是否符合预期。
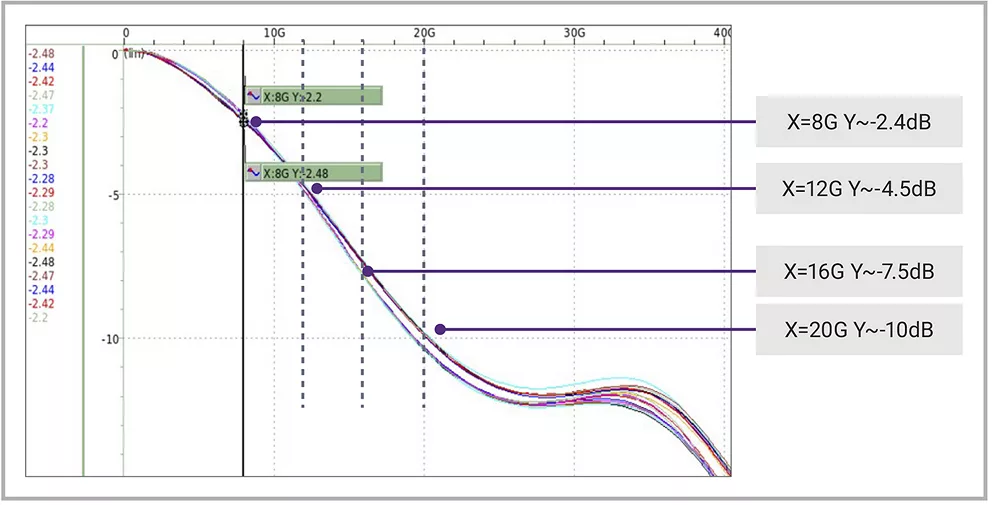
▲图4 16G奈奎斯特频率下的有损信道示例
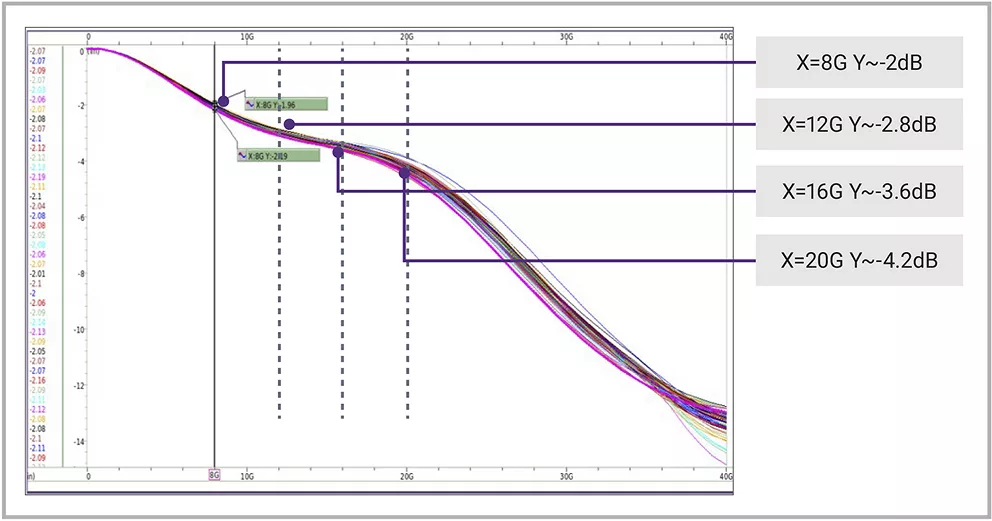
▲图5 良好渠道设计示例
40G UCIe PHY支持新兴的先进封装技术,例如硅或RDL中介层、硅桥和RDL扇出,以及传统的有机衬底封装技术。PHY为先进封装技术提供高达12 Tbps/mm的总带宽效率,为标准封装技术提供高达1.8 Tbps/mm的总带宽效率,同时运行速度高达40Gbps/pin。有机衬底封装技术虽然更为常见且比较实惠,但需要更多的布线层来支持IP实现更高速的布线。相反,先进封装技术可以改善布线密度,但也增加了封装设计所面临的挑战。了解到这种复杂性,新思科技提供了用于中介层设计的3DIC Compiler平台及UCIe-A IP参考设计。3DIC Compiler是统一的探索到签核解决方案,其中包含用于自动布线和自定义中介层设计的工具和脚本。
40G UCIe IP实现了前向时钟架构,以简化接收器架构,从而降低功耗和延迟。其中使用了四倍速率架构,对于32 Gbps/pin速度,PHY操作频率限制为8 GHz;对于40 Gbps/pin速度,PHY操作频率限制为10 GHz。此外还借助嵌入式低延迟FIFO来补偿前向时钟和本地时钟之间以及不同通道之间的偏差不匹配。通用的100MHz参考时钟用作PHY锁相环(PLL)的输入,可生成PHY和控制器所需的所有高频时钟,这样逻辑电路就无需向PHY提供高频时钟。图6为40G UCIe PHY架构。
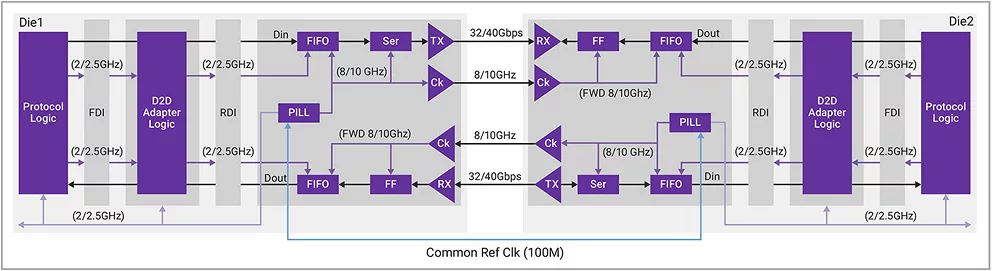
▲图6 UCIe PHY架构
UCIe未来的发展道路
3D封装具有功耗和性能优势,正逐渐成为快速Multi-Die设计的优选解决方案。
UCIe规范2.0正在促使3D封装中的Die-to-Die连接实现标准化,与2D和2.5D技术相比,其带宽更高且功耗更低。UCIe规范为3D封装定义了以下特性:
适合凸块区域的电路和逻辑,这有助于实现较低的工作频率和更简单的电路
较小的凸块间距,例如几微米
预定义的Bump-PHY的Bump图,可简化互操作性
新思科技利用3DIO IP解决方案实现了3D封装中的Die-to-Die连接。
3D封装技术正蓬勃发展,未来几年对更高数据速率的需求可能会越来越大。Die-to-Die接口也将持续演进,以支持更高的速度和能效。
业界首款40G UCIe IP解决方案,包括控制器、PHY和验证IP,提供更高算力,可满足速度更高的基于UCIe的Multi-Die设计需求。PHY的简化架构简化了IP集成,全面的监控、测试和修复功能则改善了可靠性和芯片的健康状况。新思科技走在技术发展的前沿,并将继续部署先进的IP来适应千变万化的市场需求。
-
数据中心
+关注
关注
16文章
4810浏览量
72212 -
新思科技
+关注
关注
5文章
800浏览量
50362 -
AI芯片
+关注
关注
17文章
1893浏览量
35099 -
UCIe
+关注
关注
0文章
47浏览量
1635
原文标题:当 AI 芯片遇上带宽瓶颈,看40G UCIe IP 如何打破僵局?
文章出处:【微信号:Synopsys_CN,微信公众号:新思科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Maxim 40G传输解决方案有效降低功耗、提高数据吞吐率
40G光模块选购指南
40G数据中心之铜缆布线
2023是否会成为Multi-Die的腾飞之年?
芯片革命:Multi-Die系统引领电子设计进阶之路
态路小课堂丨为40G数据中心综合布线产品选择方案!






 工商网监
工商网监
评论