 海力士展示AI专用计算内存解决方案AiMX-xPU
海力士展示AI专用计算内存解决方案AiMX-xPU
在Hot Chips 2024上,海力士专注于AI加速器的标准DRAM之外的产品。该公司展示了其在内存计算方面的最新进展,这次是用其AiMX-xPU和LPDDR-AiM进行LLM推理。其理念是,无需将数据从内存移动到计算以执行与内存相关的转换,这些转换可以直接在内存中完成,而无需遍历互连。这使得它更节能,而且可能更快。
海力士在Hot Chips 2024上展示AI专用计算内存解决方案AiMX-xPU
海力士表示,由于LLM的存储空间有限,因此对LLM非常有用。
该公司展示了采用Xilinx VirtexFPGA和特殊GDDR6 AiM封装的GDDR6内存加速器卡。

看下AiMX card:

下面是GDDR6芯片的外观。

另外,海力士提到了OCP 2023的现场演示。

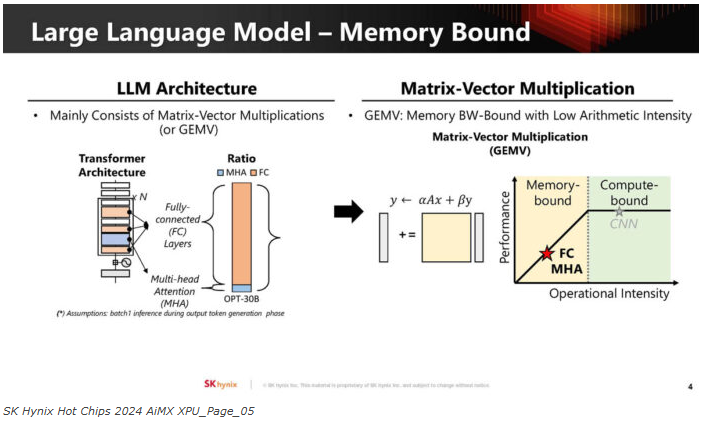
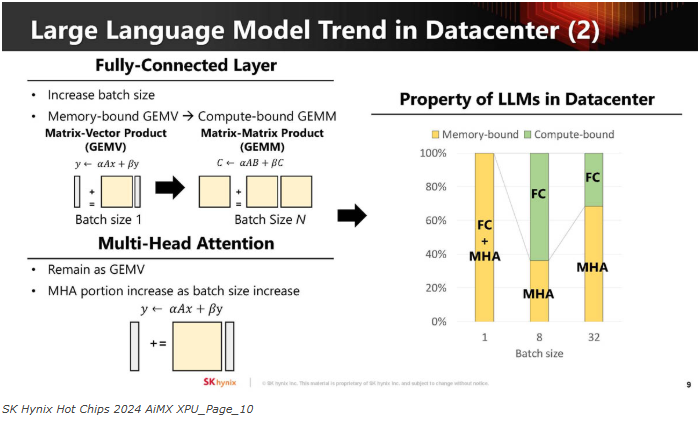
这是LLM的全连接层、Multi-Head Attention以及计算绑定部分。
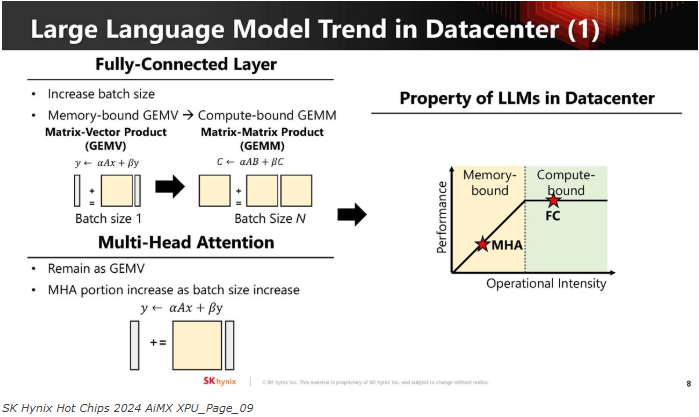
下图展示压力如何根据批量大小变化。
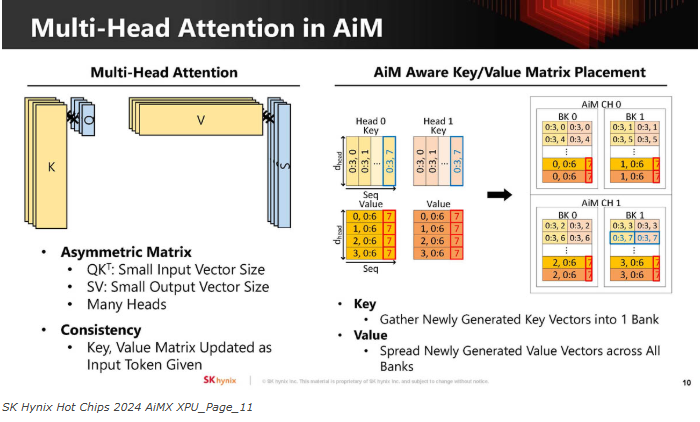
海力士将Multi-Head Attention映射到了AiM。
该公司还将内存容量增加了一倍,使用32个AIM软件包,从16GB增加到32GB。32GB对于一款产品来说可能不够,但对于一个原型机来说就足够了。尽管如此,该公司还是展示了这项技术的性能。

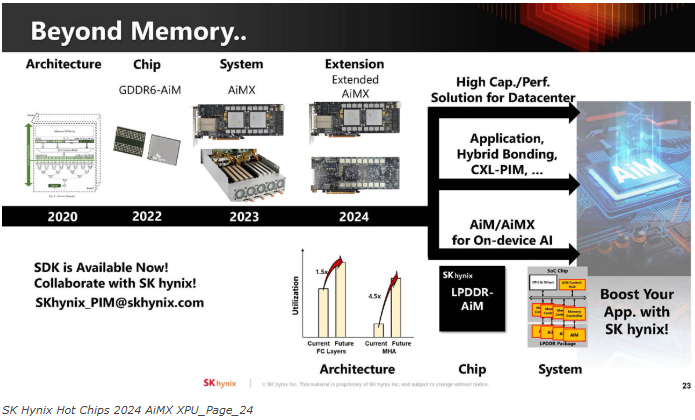
下一代演示将展示像Llama-3这样的东西,该公司也在考虑将每张卡的容量从32GB扩展到256GB。

除了关注数据中心的AI,该公司还在关注设备上的AI。我们已经看到苹果、英特尔、AMD和高通等公司在为人工智能推出NPU。
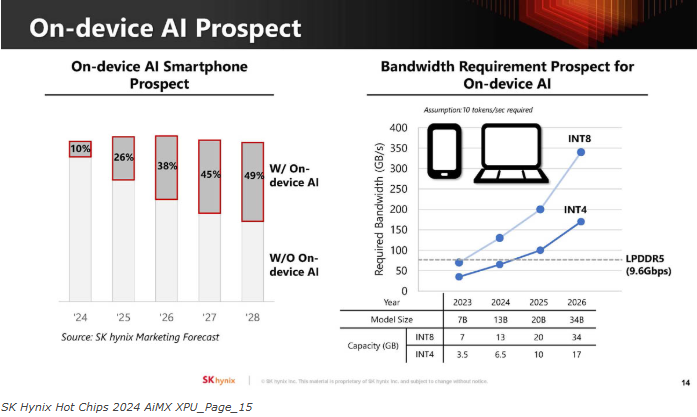
设备上的AI通常会降低批处理大小,因为这些工作负载受到内存限制。将计算移出SoC意味着它可以更节能,并且不会占用SoC上的计算芯片面积。
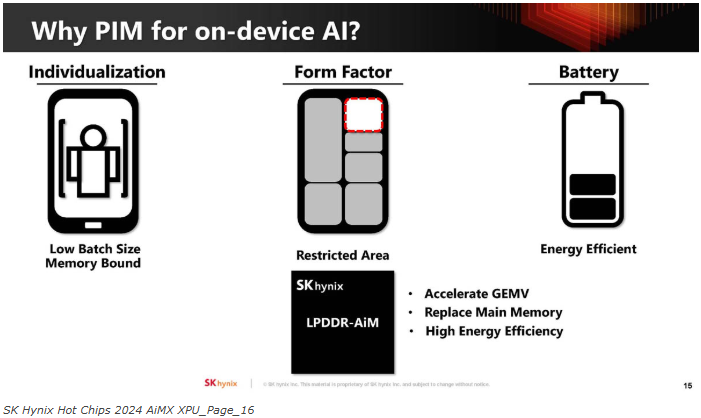
目标是在未来针对LPDDR5-AiM的产品中优化AiM。我们的目标是不更改现有的LPDDR命令,也不产生负面的性能影响。下表上的规格是预估的。
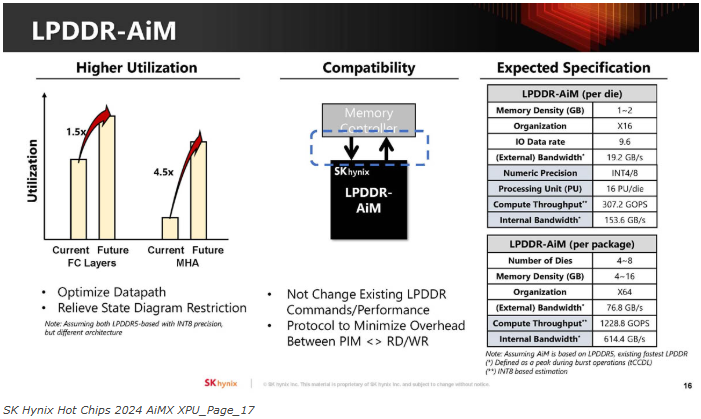
通过LPDDR5,它可以集成到移动设备的SoC上。
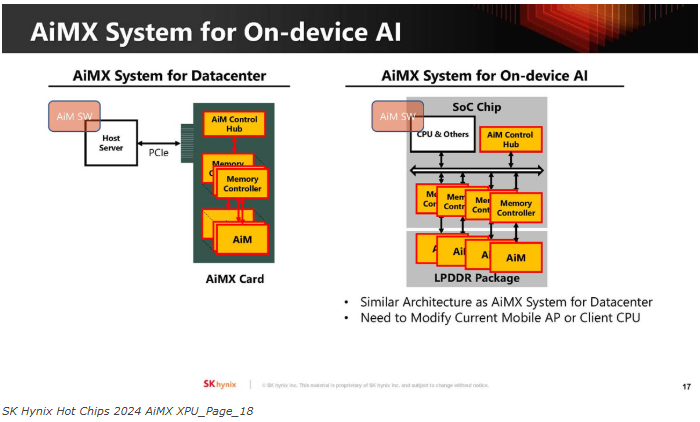
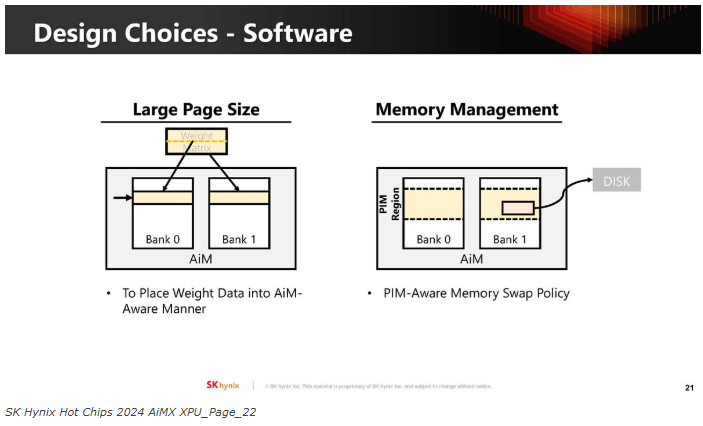
可能需要针对不同的应用程序进行不同的权衡。

其中一个挑战是在LPDDR内存的正常使用和计算需求之间进行仲裁。此外,还有可能改变芯片的热/功率要求。

另一个挑战是如何对AiM进行编程。
海力士似乎正在扩大AiM/ AiMX的使用范围和种类。
海力士表示,在GDDR6中,AiM占据了约20%的芯片面积。
总结
内存计算在成为主流之前。仍然是一个主要的SoC/芯片供应商必须选择和集成的东西。在许多方面,内存计算可能是有意义的。我们将拭目以待,看看这款产品能否从原型变成产品。
原文链接:
https://www.servethehome.com/sk-hynix-ai-specific-computing-memory-solution-aimx-xpu-at-hot-chips-2024/
-
海力士
+关注
关注
2文章
135浏览量
25971 -
soc
+关注
关注
38文章
4180浏览量
218492 -
内存
+关注
关注
8文章
3037浏览量
74144
原文标题:揭秘!海力士的推理和端侧大模型加速卡
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论