 阿里提出低计算量语音合成系统,速度提升4倍
阿里提出低计算量语音合成系统,速度提升4倍
阿里巴巴语音交互智能团队提出一种基于深度前馈序列记忆网络的语音合成系统。该系统在达到与基于双向长短时记忆单元的语音合成系统一致的主观听感的同时,模型大小只有后者的四分之一,且合成速度是后者的四倍,非常适合于对内存占用和计算效率非常敏感的端上产品环境。该研究已入选语音顶会ICASSP会议Oral论文,本文带来详细解读。
研究背景
语音合成系统主要分为两类,拼接合成系统和参数合成系统。其中参数合成系统在引入了神经网络作为模型之后,合成质量和自然度都获得了长足的进步。另一方面,物联网设备(例如智能音箱和智能电视)的大量普及也对在设备上部署的参数合成系统提出了计算资源的限制和实时率的要求。本工作引入的深度前馈序列记忆网络可以在保持合成质量的同时,有效降低计算量,提高合成速度。
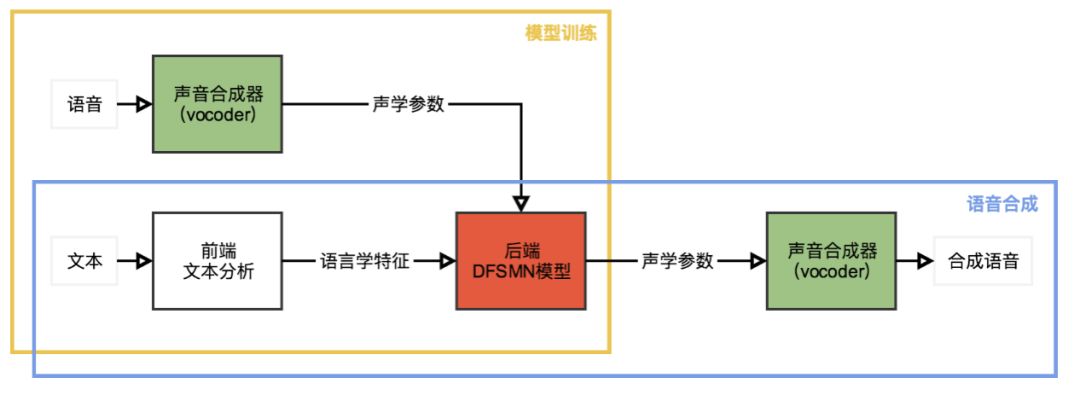
我们使用基于双向长短时记忆单元(BLSTM)的统计参数语音合成系统作为基线系统。与其他现代统计参数语音合成系统相似,我们提出的基于深度前馈序列记忆网络(DFSMN)的统计参数语音合成系统也是由3个主要部分组成,声音合成器(vocoder),前端模块和后端模块,如上图所示。我们使用开源工具WORLD作为我们的声音合成器,用来在模型训练时从原始语音波形中提取频谱信息、基频的对数、频带周期特征(BAP)和清浊音标记,也用来在语音合成时完成从声学参数到实际声音的转换。前端模块用来对输入的文本进行正则化和词法分析,我们把这些语言学特征编码后作为神经网络训练的输入。后端模块用来建立从输入的语言学特征到声学参数的映射,在我们的系统中,我们使用DFSMN作为后端模块。
深度前馈序列记忆网络
紧凑前馈序列记忆网络(cFSMN)作为标准的前馈序列记忆网络(FSMN)的改进版本,在网络结构中引入了低秩矩阵分解,这种改进简化了FSMN,减少了模型的参数量,并加速了模型的训练和预测过程。
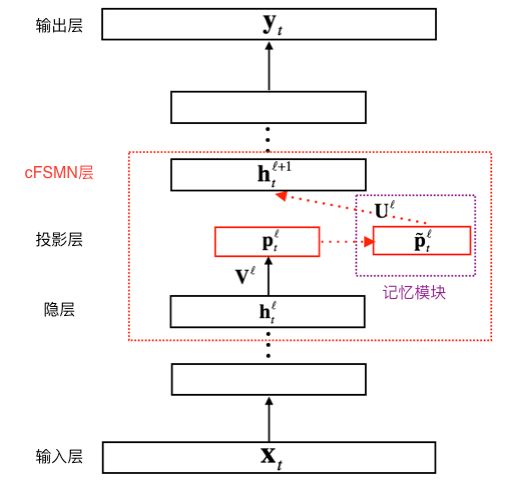
上图给出了cFSMN的结构的图示。对于神经网络的每一个cFSMN层,计算过程可表示成以下步骤①经过一个线性映射,把上一层的输出映射到一个低维向量②记忆模块执行计算,计算当前帧之前和之后的若干帧和当前帧的低维向量的逐维加权和③把该加权和再经过一个仿射变换和一个非线性函数,得到当前层的输出。三个步骤可依次表示成如下公式。
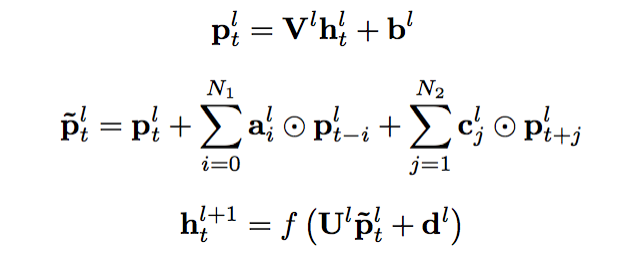
与循环神经网络(RNNs,包括BLSTM)类似,通过调整记忆模块的阶数,cFSMN有能力捕捉序列的长程信息。另一方面,cFSMN可以直接通过反向传播算法(BP)进行训练,与必须使用沿时间反向传播算法(BPTT)进行训练的RNNs相比,训练cFSMN速度更快,且较不容易受到梯度消失的影响。
对cFSMN进一步改进,我们得到了深度前馈序列记忆网络(DFSMN)。DFSMN利用了在各类深度神经网络中被广泛使用的跳跃连接(skip-connections)技术,使得执行反向传播算法的时候,梯度可以绕过非线性变换,即使堆叠了更多DFSMN层,网络也能快速且正确地收敛。对于DFSMN模型,增加深度的好处有两个方面。一方面,更深的网络一般来说具有更强的表征能力,另一方面,增加深度可以间接地增大DFSMN模型预测当前帧的输出时可以利用的上下文长度,这在直观上非常有利于捕捉序列的长程信息。具体来说,我们把跳跃连接添加到了相邻两层的记忆模块之间,如下面公式所示。由于DFSMN各层的记忆模块的维数相同,跳跃连接可由恒等变换实现。
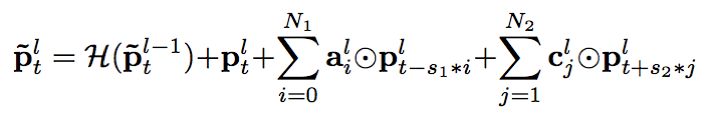
我们可以认为DFSMN是一种非常灵活的模型。当输入序列很短,或者对预测延时要求较高的时候,可以使用较小的记忆模块阶数,在这种情况下只有当前帧附近帧的信息被用来预测当前帧的输出。而如果输入序列很长,或者在预测延时不是那么重要的场景中,可以使用较大的记忆模块阶数,那么序列的长程信息就能被有效利用和建模,从而有利于提高模型的性能。
除了阶数之外,我们为DFSMN的记忆模块增加了另一个超参数,步长(stride),用来表示记忆模块提取过去或未来帧的信息时,跳过多少相邻的帧。这是有依据的,因为与语音识别任务相比,语音合成任务相邻帧之间的重合部分甚至更多。
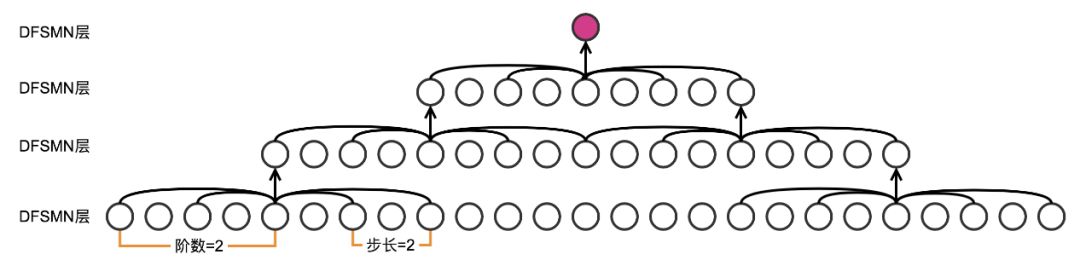
上文已经提到,除了直接增加各层的记忆模块的阶数之外,增加模型的深度也能间接增加预测当前帧的输出时模型可以利用的上下文的长度,上图给出了一个例子。
实验
在实验阶段,我们使用的是一个由男性朗读的中文小说数据集。我们把数据集划分成两部分,其中训练集包括38600句朗读(大约为83小时),验证集包括1400句朗读(大约为3小时)。所有的语音数据采样率都为16k赫兹,每帧帧长为25毫秒,帧移为5毫秒。我们使用WORLD声音合成器逐帧提取声学参数,包括60维梅尔倒谱系数,3维基频的对数,11维BAP特征以及1维清浊音标记。我们使用上述四组特征作为神经网络训练的四个目标,进行多目标训练。前端模块提取出的语言学特征,共计754维,作为神经网络训练的输入。
我们对比的基线系统是基于一个强大的BLSTM模型,该模型由底层的1个全连接层和上层的3个BLSTM层组成,其中全连接层包含2048个单元,BLSTM层包含2048个记忆单元。该模型通过沿时间反向传播算法(BPTT)训练,而我们的DFSMN模型通过标准的反向传播算法(BP)训练。包括基线系统在内,我们的模型均通过逐块模型更新过滤算法(BMUF)在2块GPU上训练。我们使用多目标帧级别均方误差(MSE)作为训练目标。
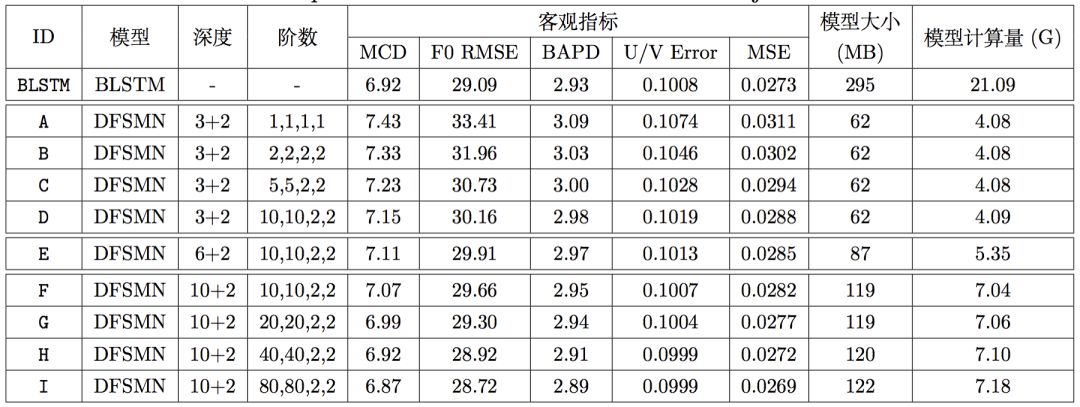
所有的DFSMN模型均由底层的若干DFSMN层和上的2个全连接层组成,每个DFSMN层包含2048个结点和512个投影结点,而每个全连接层包含2048个结点。在上图中,第三列表示该模型由几层DFSMN层和几层全连接层组成,第四列表示该模型DFSMN层的记忆模块的阶数和步长。由于这是FSMN这一类模型首次应用在语音合成任务中,因此我们的实验从一个深度浅且阶数小的模型,即模型A开始(注意只有模型A的步长为1,因为我们发现步长为2始终稍好于步长为1的相应模型)。从系统A到系统D,我们在固定DFSMN层数为3的同时逐渐增加阶数。从系统D到系统F,我们在固定阶数和步长为10,10,2,2的同时逐渐增加层数。从系统F到系统I,我们固定DFSMN层数为10并再次逐渐增加阶数。在上述一系列实验中,随着DFSMN模型深度和阶数的增加,客观指标逐渐降低(越低越好),这一趋势非常明显,且系统H的客观指标超过了BLSTM基线。
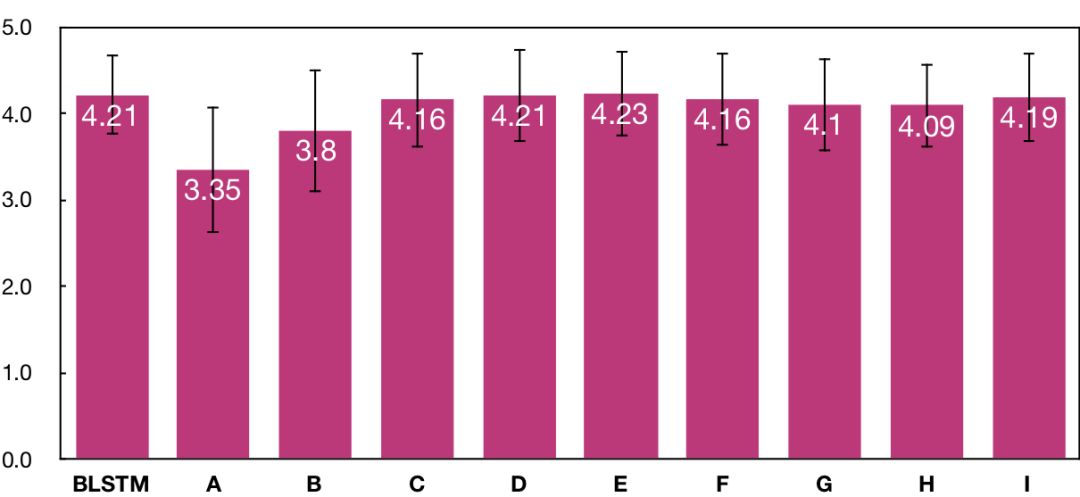
另一方面,我们也做了平均主观得分(MOS)测试(越高越好),测试结果如上图所示。主观测试是通过付费众包平台,由40个母语为中文的测试人员完成的。在主观测试中,每个系统生成了20句集外合成语音,每句合成语音由10个不同的测试人员独立评价。在平均主观得分的测试结果表明,从系统A到系统E,主观听感自然度逐渐提高,且系统E达到了与BLSTM基线系统一致的水平。但是,尽管后续系统客观指标持续提高,主观指标只是在系统E得分的上下波动,没有进一步提高。
结论
根据上述主客观测试,我们得到的结论是,历史和未来信息各捕捉120帧(600毫秒)是语音合成声学模型建模所需要的上下文长度的上限,更多的上下文信息对合成结果没有直接帮助。与BLSTM基线系统相比,我们提出的DFSMN系统可以在获得与基线系统一致的主观听感的同时,模型大小只有基线系统的1/4,预测速度则是基线系统的4倍,这使得该系统非常适合于对内存占用和计算效率要求很高的端上产品环境,例如在各类物联网设备上部署。
-
神经网络
+关注
关注
42文章
4772浏览量
100833 -
物联网
+关注
关注
2909文章
44691浏览量
373891 -
智能语音交互
+关注
关注
0文章
21浏览量
2817
原文标题:ICASSP Oral 论文:阿里提出低计算量语音合成系统,速度提升4倍
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
EMMC存储速度如何提升
基于语音识别的智能会议系统具备哪些交互功能
阿里云海外收入五年增长20倍
如何提升 ChatGPT 的响应速度
语音集成电路有哪些特点
声发射系统的技术指标:最高采样速度的选择
有效提升智能会议系统语音识别准确性案例分享

基于助听器开发的一种高效的语音增强神经网络
【解读】VTX316 TTS语音合成芯片几个很实用的应用技巧
WT3000T8-TTS语音合成芯片及应用场景介绍
玩转语音合成芯片(TTS芯片),看这一篇就够了

新型散热材料金刚石纳米膜有望将电动汽车的充电速度提升五倍






 工商网监
工商网监
评论