 KPTI实现机制及性能与开销
KPTI实现机制及性能与开销
1 KPTI概述
KPTI(Kernel PageTable Isolation)全称内核页表隔离。KPTI是由KAISER补丁修改而来。之前,进程地址空间被分成了内核地址空间和用户地址空间。其中内核地址空间映射到了整个物理地址空间,而用户地址空间只能映射到指定的物理地址空间。内核地址空间和用户地址空间共用一个页全局目录表(PGD表示进程的整个地址空间),meltdown漏洞就恰恰利用了这一点。攻击者在非法访问内核地址和CPU处理异常的时间窗口,通过访存微指令获取内核数据。为了彻底防止用户程序获取内核数据,可以令内核地址空间和用户地址空间使用两组页表集(也就是使用两个PGD)。
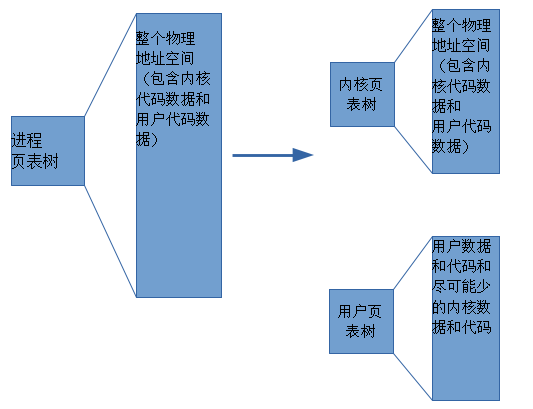
图1 修改后的进程地址空间
2 问题
当然事情并没有那么简单,有两个问题:
问题1: X86架构中,在上下文切换的间隙(注意是间隙)内存中的一部分需要对内核空间和用户空间都是有效的,也就是说在切换CR3之前内核就要开始工作了。
问题2:修改CR3时,CPU会冲刷TLB,从而带来很大的性能问题
3 KPTI实现机制
在KAISER的论文中针对这两个问题,提出了以下解决方案
3.1 影子地址空间(Shadow Address Spaces)
KPTI中每个进程有两个地址空间,第一个地址空间只能在内核态下访问,可以创建到内核和用户的映射(不过用户空间受SMAP和SMEP保护,具体可查询Intel手册)。第二个地址空间被称为影子地址空间,只包含用户空间。不过由于涉及到上下文切换,所以在影子地址空间中必须包含部分内核地址,用来建立到中断入口和出口的映射。
当中断在用户态发生时,就涉及到切换CR3寄存器,从影子地址空间切换到用户态的地址空间。中断上半部的要求是尽可能的快,从而切换CR3这个操作也要求尽可能的快。为了达到这个目的,KAISER中将内核空间的PGD和用户空间的PGD连续的放置在一个8KB的内存空间中。这段空间必须是8K对齐的,这样将CR3的切换操作转换为将CR3值的第13位(由低到高)的置位或清零操作,提高了CR3切换的速度。
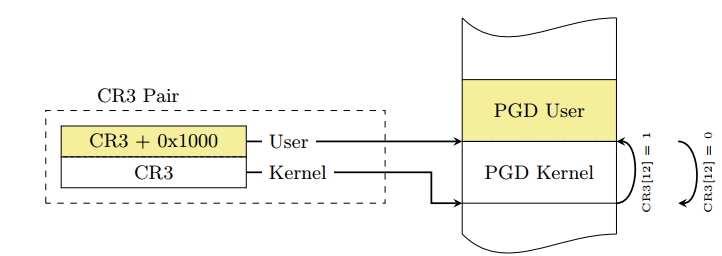
用户空间和内核空间的PGD分布示意图
3.2 内核空间的最小映射
上文提到,在从影子地址空间切换到内核地址空间的过程中,为了使得内核在CR3切换之前就能够开始工作,影子地址空间必须包含部分内核地址空间。
如下图所示,阴影处就是在陷入内核态过程中,需要映射的内核数据和代码。图a 是常规OS的进程的地址空间。图b和图c是页表隔离后的进程地址空间,两者的区别再与是否使用了SMAP和SMEP机制。
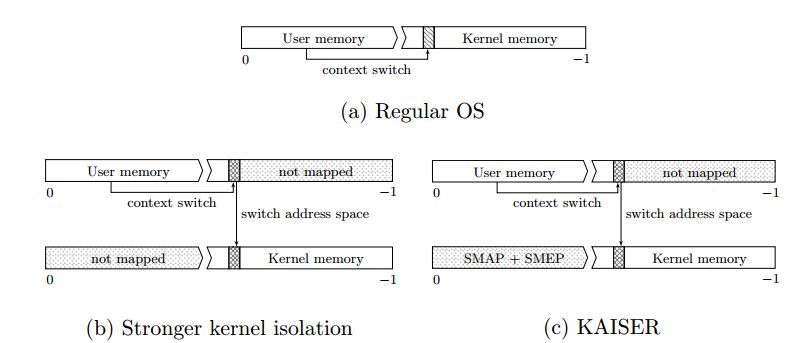
那么如何确定影子地址空间应该映射那些内核数据呢?由于中断可能发生在用户态,所以应该包含中断向量表(IDT),中断栈,中断向量。另外内核栈,GDT和TSS也应该映射到影子地址空间。
4 性能与开销(performance and overhead)
4.1 TLB
在intel手册中提到,线性地址的高位被称为页号(page number),低位被称为页偏移(page offset, 如果页大小是4K则是低12位)。物理地址的高位被称为页框(page frame)。
TLB用于加速从线性地址到物理地址的转换,本质上还是一种缓存。TLB使用页号来获取线性地址所对应的页的基地址。TLB中的每一项包含以下内容:
页号对应页的物理地址
页的访问权限(R/W,U/S )
页属性(dirty flag,memory type)
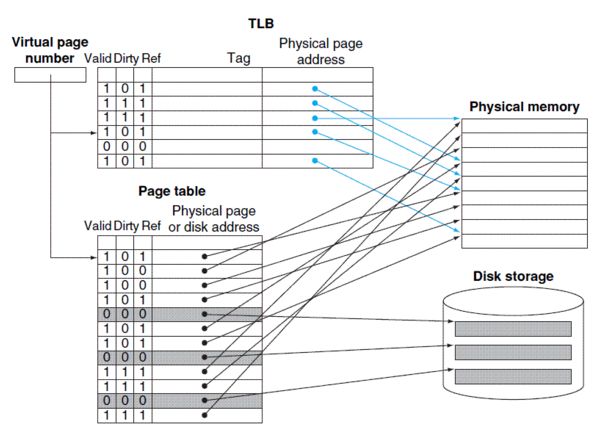
图4-1 基于TLB的访存过程
一个处理器可能包含不同类型的TLB,比如专用于取指令的TLB和用于数据访问的TLB
切换CR3时,CPU会隐式的冲刷TLB。TLB的miss penalty可以达到10 – 100 个 时钟周期(clock cycles)。内存中的一些页(比如共享库)的一些页是由所有的进程共享的。这些页由页表项的全局位(G)来标示。共享页并不会参与TLB的隐式冲刷。
有两种方法防止数据的泄露,第一种需要冲刷整个TLB,而第二种则是禁用页表项的全局位。
通过PCID的使用可以缓解由于冲刷TLB带来的性能问题。
4.2 Process-Context Identifiers(PCID)
PCID全称进程上下文标示符,CR4寄存器的PCIDE位表示是否启用CPU的PCID功能。PCIDE=1表示启用PCID。启用之后,CR3(页目基址寄存器)的低12位用来存储PCID。每个进程都有一个PCID,当未启用PCID时,CR3的低12位为全0(000H)。
Intel手册对于TLB失效的行为作出了很详细的解释,在使用mov指令修改CR3时会使TLB失效(mov to CR3),具体行为如下:
如果CR4.PCIDE = 0(表示未启用PCID),CPU会使所有与PCID 000H关联的TLB缓存项(TLB entry)失效,除了全局页。
如果CR4.PCIDE = 1(启用PCID),并且源操作数的第63位=0,源操作数的0-11位为指定的PCID。那么CPU会使所有与指定PCID关联的TLB缓存项失效。TLB中与其他PCID关联的TLB缓存项并不会失效。
如果CR4.PCIDE=1,并且源操作数的第63位=1,CPU不会对TLB做任何的失效操作。
5 代码分析
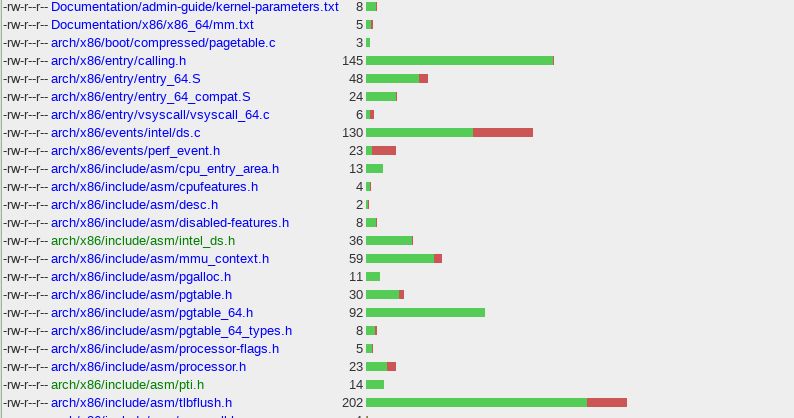
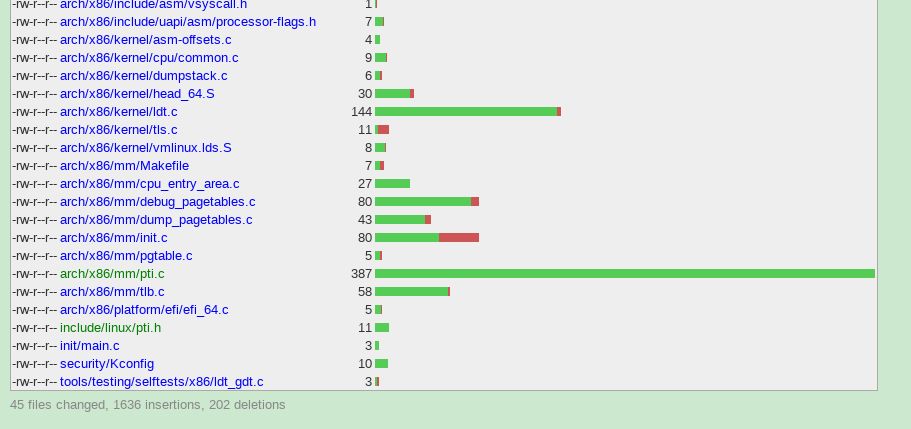
我们选取linux4.15版本作为演示,说明KPTI补丁的内核中的分布这是4.15版本和PTI(pagetable isolation)有关的diff stat. 可以看到共涉及到45个文件的修改,插入了1636行代码,删除202行代码。
增加代码行数的前三名是
mm/pti.c
arch/x86/include/asm/tlbflush.h
arch/x86/entry/calling.h
5.1 arch/x86/mm/pti.c
pti.c是补丁新增的文件. 其中的入口函数是pti_init(), 该函数在init/main.c中的mm_init()函数中调用。这个文件中的函数总共分为两种,第一种类似pti_clone_user_shared(),将内核的页表项复制到用户空间。第二种类似pti_user_pagetable_walk_p4d(unsigned long address),根据参数中的虚拟地址,得到该地址相应的页表项指针。
void __init pti_init(void)
{
if(!static_cpu_has(X86_FEATURE_PTI))
return;
pr_info("enabled\n");
pti_clone_user_shared();
pti_clone_entry_text();
pti_setup_espfix64();
pti_setup_vsyscall();
}
5.2 arch/x86/include/asm/tlbflush.h
该文件包含一系列的有关TLB flush的函数在KPTI中并不仅仅使用PCID,由于内核中的进程地址空间标示符必须从0开始。所以ASID是地址空间真正的标示符。又因为补丁中进程的地址空间有两个部分,所以我们需要两个PCID。kPCID内核空间使用的标示符。uPCID用户空间使用的标示符。
* ASID -[0, TLB_NR_DYN_ASIDS-1]
* the canonical identifier for an mm
*
* kPCID -[1, TLB_NR_DYN_ASIDS]
* the value we write into the PCID part of CR3; corresponds to the
* ASID+1, because PCID 0 is special.
*
* uPCID -[2048+1,2048+ TLB_NR_DYN_ASIDS]
* for KPTI each mm has two address spaces and thus needs two
* PCID values, but we can still do with a single ASID denomination
* for each mm.Corresponds to kPCID +2048.
#define CR3_HW_ASID_BITS 12
# define PTI_CONSUMED_PCID_BITS 1
/*
* 6 because 6 should be plenty and struct tlb_state will fit in two cache
* lines.
*/
#define TLB_NR_DYN_ASIDS 6
5.3 /arch/x86/entry/calling.h
calling.h 是系统调用的入口函数,用于处理系统调用时的寄存器保存操作。系统调用涉及到由用户态到内核态的切换。所以calling.h需要修改。
以下一系列的汇编宏指令涉及到用户PGD和内核PGD的切换. 下面我们挑选几个宏进行说明:
1. SWITCH_TO_KERNEL_CR3
该宏的任务是清楚CR3存储的PCID,并将CR3的第13置1,从而使其指向内核PGD
.macro SWITCH_TO_KERNEL_CR3 scratch_reg:req
ALTERNATIVE "jmp .Lend_\@","", X86_FEATURE_PTI
mov %cr3, \scratch_reg
ADJUST_KERNEL_CR3 \scratch_reg
mov \scratch_reg,%cr3
.Lend_\@:
.endm
2. SWITCH_TO_USER_CR3_NOSTACK该宏的任务是根据进程的ASID判断其TLB是否需要flush, 如果不需要就在CR3中标记为no_flush。随后将kPCID转换为uPCID,并使CR3指向用户PGD。这一切都在很短的时间内发生,因为它们只是对CR3寄存器的置位操作。
.macro SWITCH_TO_USER_CR3_NOSTACK scratch_reg:req scratch_reg2:req
ALTERNATIVE "jmp .Lend_\@","", X86_FEATURE_PTI
mov %cr3, \scratch_reg
ALTERNATIVE "jmp .Lwrcr3_\@","", X86_FEATURE_PCID
/*
* Test if the ASID needs a flush.
*/
movq \scratch_reg, \scratch_reg2
andq $(0x7FF), \scratch_reg /* mask ASID */
bt \scratch_reg, THIS_CPU_user_pcid_flush_mask
jnc .Lnoflush_\@
/* Flush needed, clear the bit */
btr \scratch_reg, THIS_CPU_user_pcid_flush_mask
movq \scratch_reg2, \scratch_reg
jmp .Lwrcr3_pcid_\@
.Lnoflush_\@:
movq \scratch_reg2, \scratch_reg
SET_NOFLUSH_BIT \scratch_reg
.Lwrcr3_pcid_\@:
/* Flip the ASID to the user version */
orq $(PTI_USER_PCID_MASK), \scratch_reg
.Lwrcr3_\@:
/* Flip the PGD to the user version */
orq $(PTI_USER_PGTABLE_MASK), \scratch_reg
mov \scratch_reg,%cr3
.Lend_\@:
.endm
-
处理器
+关注
关注
68文章
19396浏览量
230720 -
Linux
+关注
关注
87文章
11336浏览量
210101
原文标题:KPTI补丁分析
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
WIFI的跳频机制怎么实现的?
关于C++中的函数重载机制
智能电机控制优化实时性能与效率设计介绍
频间硬切换实现的机制,以及对RNC性能的影响
联合编码开销与安全性能的网络编码优化方案
基于循环神经网络的数据库查询开销预测






 工商网监
工商网监
评论