 神经网络瘦身:关于SqueezeNet的创新点、网络结构
神经网络瘦身:关于SqueezeNet的创新点、网络结构

今年二月份,UC Berkeley和Stanford一帮人在arXiv贴了一篇文章:
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5MB model size(https://arxiv.org/abs/1602.07360)
这篇文章做成了许多人梦寐以求的事——压缩神经网络参数。但和以往不同,原作不是在前人网络基础上修修补补(例如Deep Compression),而是自己设计了一个全新的网络,它用了比AlexNet少50倍的参数,达到了AlexNet相同的精度!
关于SqueezeNet的创新点、网络结构,国内已经有若干爱好者发布了相关的简介,如这篇(http://blog.csdn.net/xbinworld/article/details/50897870)、这篇(http://blog.csdn.net/shenxiaolu1984/article/details/51444525),国外的文献没有查,相信肯定也有很多。
本文关注的重点在SqueezeNet为什么能实现网络瘦身?难道网络参数的冗余性就那么强吗?或者说很多参数都是浪费的、无意义的?
为了更好的解释以上问题,先给出AlexNet和SqueezeNet结构图示:
AlexNet
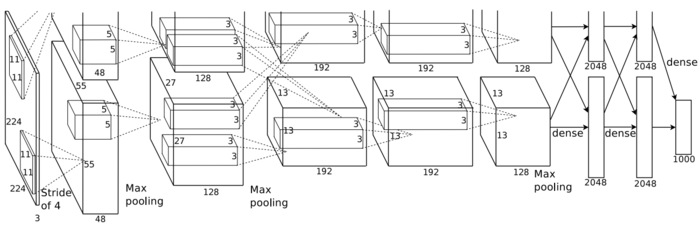
图1 AlexNet示意图
图2 AlexNet网络结构
SqueezeNet
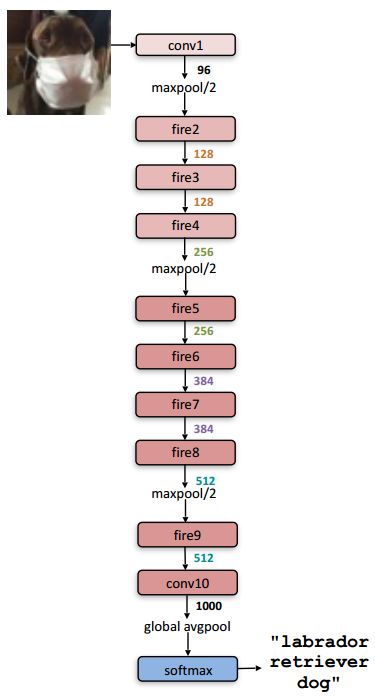
图3 SqueezeNet示意图
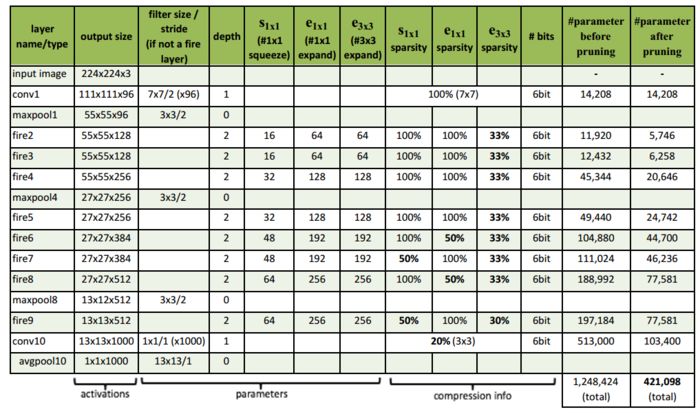
图4 SqueezeNet网络结构
为什么SqueezeNet能够以更少的参数实现AlexNet相同的精度?
下面的表格直观的展示了SqueezeNet的参数量,仅为AlexNet的1/48。
| 网络 | 参数量 |
|---|---|
| AlexNet | 60M |
| SqueezeNet | 1.25M |
乍一看,感觉非常不科学,怎么可能相差如此悬殊的参数量实现了相同的识别精度?
我们先考虑一个非常简单的例子,这个例子可以说是SqueezeNet和AlexNet的缩影:
1、一层卷积,卷积核大小为5×5
2、两层卷积,卷积核大小为3×3
以上两种卷积方式除了卷积核大小不同,其它变量均相同,为了方便后文计算,定义输入通道数1,输出通道数为C(两层卷积为C'),输出尺寸N×N。
按照目前的理论,神经网络应该尽可能的采用多层小卷积,以减少参数量,增加网络的非线性。但随着参数的减少,计算量却增加了!根据上面的例子,大致算一下,为了简便,只考虑乘法的计算量:
5×5一层卷积计算量是25×C×N×N
3×3两层卷积的计算量是9×C×(1+C')×N×N
很明显25C<9C(1+C')。
这说明了什么?说明了“多层小卷积核”的确增大了计算量!
我们再回过头考虑SqueezeNet和AlexNet,两个网络的架构如上面4幅图所示,可以看出SqueezeNet比AlexNet深不少,SqueezeNet的卷积核也更小一些,这就导致了SqueezeNet计算量远远高于AlexNet(有待商榷,需要进一步确认,由于Fire module中的squeeze layer从某种程度上减少了计算量,SqueezeNet的计算量可能并不大)。
可是论文原文过度关注参数个数,忽略计算量,这样的对比方式貌似不太妥当。事实上,目前最新的深层神经网络都是通过增加计算量换来更少的参数,可是为什么这样做效果会很好?
因为内存读取耗时要远大于计算耗时!
如此一来,问题就简单了,不考虑网络本身架构的优劣性,深层网络之所以如此成功,就是因为把参数读取的代价转移到计算量上了,考虑的目前人类计算机的发展水平,计算耗时还是要远远小于数据存取耗时的,这也是“多层小卷积核”策略成功的根源。
关于Dense-Sparse-Dense(DSD)训练法
不得不说一下原作的这个小发现,使用裁剪之后的模型为初始值,再次进行训练调优所有参数,正确率能够提升4.3%。 稀疏相当于一种正则化,有机会把解从局部极小中解放出来。这种方法称为DSD (Dense→Sparse→Dense)。
这个和我们人类学习知识的过程是多么相似!人类每隔一段时间重新温习一下学过的知识,会增加对所学知识的印象。我们可以把“隔一段时间”理解为“裁剪”,即忘却那些不怎么重要的参数,“再学习”理解为从新训练,即强化之前的参数,使其识别精度更高!
-
神经网络
+关注
关注
42文章
4842浏览量
108163
原文标题:神经网络瘦身:SqueezeNet
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
神经网络结构搜索有什么优势?
卷积神经网络模型发展及应用

基于神经网络结构在命名实体识别中应用的分析与总结

一种新型神经网络结构:胶囊网络
一种改进的深度神经网络结构搜索方法




评论