 Ringbuffer的性能优化方法
Ringbuffer的性能优化方法
本文转载于极术社区
作者:非典型程序员
Ringbuffer(循环缓存)是软件中非常常用的数据结构之一, 在互联网应用、数据库应用等中使用广泛。处理器执行 Ringbuffer 的效率与其存储系统处理共享数据的性能息息相关。
本文旨在介绍 Ringbuffer 的性能优化方法。本文介绍基于 mutex 的 Ringbuffer 实现、阻塞的无锁实现以及非阻塞的无锁实现,并且比较和分析这些不同的实现在 Arm 服务器平台上的性能。
声明:本文介绍的针对 Ringbuffer 实现的优化方法来自于 Ola Liljedahl 的研究。Ola 现任 Arm 公司的架构师,长期专注于网络软件的性能优化设计,尤其是可扩展的多线程共享存储编程。针对 Arm A 系列处理的多线程性能,他开发了一个可扩展的多线程并行库progress64(github.com/ARM-software/progress64)。
本文分析了 Ola 提出的主要优化手段,并且在 Arm服务器上重现了 Ola 的优化以验证其实际效果。博客中使用的代码只是示例代码(https://github.com/wangeddie67/ringbuffer_opt_demo),其功能完备性和鲁棒性都不能满足实际应用的需求。
介绍
Ringbuffer 通常由一个包含数据的数组和指向队列头(Head)和队尾(Tail)的指针构成(如图 1 左边所示)。指针只能按照一个方向移动。当指针移动到数组结尾时,指针会折回到队列开始。
Head 指针表示下一个可以弹出的数据;当数据弹出队列(称为 Dequeue)时,Head 指针加 1。Tail 指针表示下一个可以压入数据的单元;当数据压入队列(称为 Enqueue)时,Tail 指针加 1;
从逻辑上看,Ringbuffer 中的数组形成了一个环(如图 1 右边所示)。头和尾指针在这个环上沿着相同的方向移动。这就是 Ringbuffer 名称的由来。
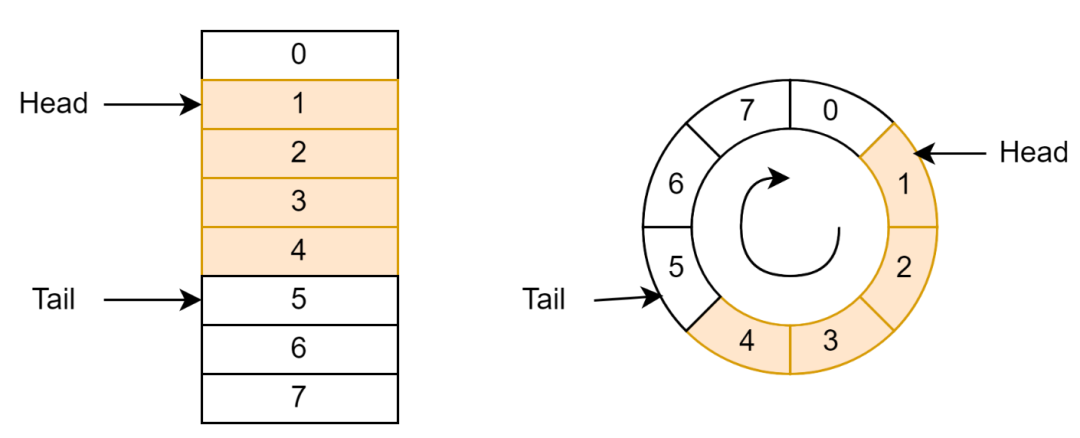
图 1 Ringbuffer 示意图
向 Ringbuffer 压入单元的程序称为生产者(Producer),从 Ringbuffer 弹出单元的程序称为消费者(Consumer),如图 2 所示。一个 Ringbuffer 通常具有很多的生产者和消费者,每个生产者和消费者都是不同的线程或进程。这些线程或进程会被调度到系统中的不同处理器核心上,而 Ringbuffer 则是不同处理器核心之间共享的数据。
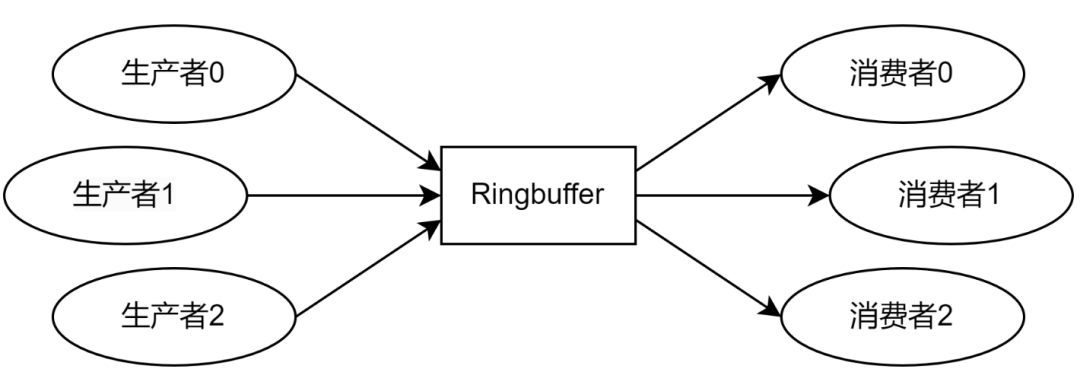
图 2 生产者和消费者
基于 Mutex 的 Ringbuffer 实现
为了保证共享数据的功能正确,通常使用 mutex 来进行保护 Ringbuffer,以保证只有一个生产者或消费者能够访问或操作 Ringbuffer。
基于 Mutex 的 Ringbuffer 声明
Ringbuffer 的数据结构如代码块 1 所示。
// Entry in ring buffer
class BufferEntry
{
public:
void *mp_ptr; // Pointer to data entry.
};
class RingBuffer
{
public:
int m_mutex; // Mutex for shared pointers.
unsigned int m_size; // The number of physical entries.
unsigned int m_head; // Head pointer.
unsigned int m_tail; // Tail pointer.
BufferEntry *mp_entries; // Pointer to physical entries.
};
代码 1 基于 Mutex 的 Ringbuffer 声明
数据数组中每个单元BufferEntry只提供一个指针,指针指向实际需要进入 Ringbuffer 的数据结构。当 Enqueue 和 Dequeue 时,只需要复制数据结构的指针即可,而不需要复制数据,从而减少数据拷贝的开销。
基于 Mutex 的 Ringbuffer 的 Enqueue 和 Dequeue 函数
图 3 展示了 Enqueue 和 Dequeue 的流程图。图 3 左边展示的是阻塞操作的流程图;右边展示的是非阻塞操作的流程图。如果实现的是阻塞式的操作,那么函数一直重复检查空满条件,直到 Ringbuffer 的满足操作所需的空满条件;如果实现的是非阻塞式的操作,那么函数可以在检查空满条件失败后直接退出。
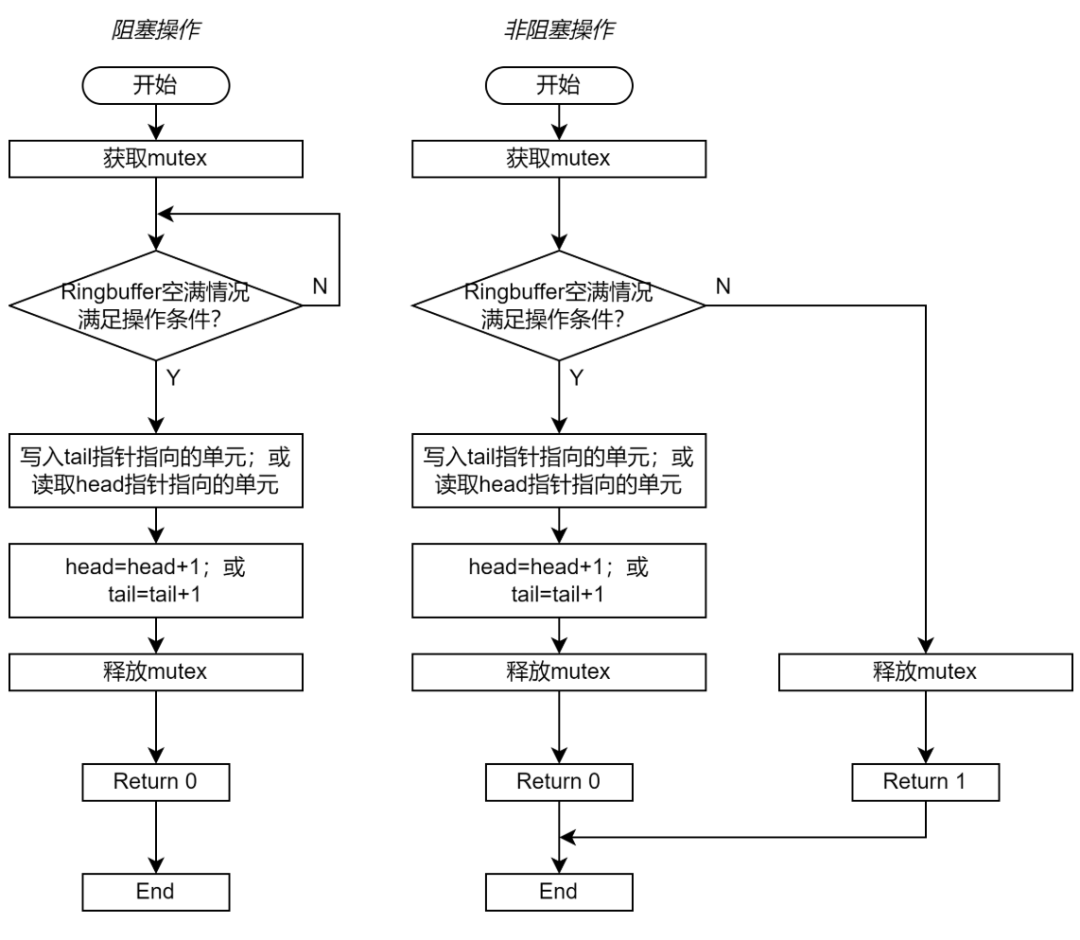
图 3 基于 Mutex 的 Ringbuffer 实现流程图
循环队列的空满控制有很多种方法。在本系列文章的示例中采用逻辑单元和物理单元的控制方法。head 和 tail 的范围并不只限于物理单元的数量,而是可以一直累加。访问单元时,将(head MOD size)或(tail MOD size)得到对应的物理单元。
对于 Enqueue 操作,需要 Ringbuffer 不为满,即m_head+m_size!=m_tail(head 和 tail 之差不大于物理单元的数量)。
对于 Dequeue 操作,需要Ringbuufer 不为空,即m_head!=m_tail (head 和 tail 没有指向同一个单元)。
基于 Mutex 的 Ringbuffer 实现如下:
// Blocking Enqueue Function int enqueue_ringbuf(RingBuffer *ring_buffer, void *entry) { // Lock mutex. lock(&ring_buffer->m_mutex); // Ringbuffer is full. Do nothing. while (ring_buffer->m_head + ring_buffer->m_size == ring_buffer->m_tail); // Enqueue entry. int enq_ptr = ring_buffer->m_tail % ring_buffer->m_size; ring_buffer->mp_entries[enq_ptr].mp_ptr = entry; // Increase tail pointer. ring_buffer->m_tail = ring_buffer->m_tail + 1; // Unlock mutex. unlock(&ring_buffer->m_mutex); return 0; } // Blocking Dequeue Function int dequeue_ringbuf(RingBuffer *ring_buffer, void **entry) { // Lock mutex. lock(&ring_buffer->m_mutex); // Ringbuffer is empty. Do nothing. while (ring_buffer->m_head == ring_buffer->m_tail); // Dequeue entry. int deq_ptr = ring_buffer->m_head % ring_buffer->m_size; *entry = ring_buffer->mp_entries[deq_ptr].mp_ptr; ring_buffer->mp_entries[deq_ptr].mp_ptr = NULL; // Increase head pointer. ring_buffer->m_head = ring_buffer->m_head + 1; // Unlock mutex. unlock(&ring_buffer->m_mutex); return 0; }
代码 2 基于 Mutex 的 Ringbuffer 实现
Lock 和 Unlock
Ringbuffer 最多允许一个生产者或一个消费者对于 Ringbuffer 进行操作。这需要通过锁标志m_mutex进行控制。考虑到 pthread 中的 mutex API 引入的系统调度开销过大,这里采用__sync_val_compare_and_swap原语实现 lock 和 unlock 操作。
type __sync_val_compare_and_swap(type* ptr, type oldval, type newval);
__sync_val_compare_and_swap原语提供了同步和原子 CAS 操作两个功能,其功能核心是 CASAL 指令。原语将ptr指向的变量与oldval比较,如果值相同则将ptr指向的变量修改为newval,并返回ptr指向变量的旧值;反之,则不修改ptr指向的变量,并返回ptr指向变量的值。同时,原语保证了 load/store 的同步,即在指令序上先于原语的 load/store 已经完成,指令序上晚于原语的 load/store 不会执行。
用__sync_val_compare_and_swap原语实现的 lock 和 unlock 功能如下:
// Lock function
void lock(int *mutex)
{
while (__sync_val_compare_and_swap(mutex, 0, 1) != 0)
{
}
}
// Unlock function
void unlock(int *mutex)
{
__sync_val_compare_and_swap(mutex, 1, 0);
}
代码 3 lock 和 unlock 函数的实现
mutex变量为 0 表示mutex释放;变量为 1 表示mutex锁定。在 lock 函数中,如果当前mutex为 0(释放),则更新为 1(锁定),并且 lock 函数返回 0;反之则 lock 函数返回 1。 基于 mutex 的 ringbuffer 实现的完整源码请参见(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/mutex_blkring.h)。
测试框架
测试程序包含一个控制测试过程的主线程和多个充当生产者和消费者的子线程。主线程首先创建并初始化 Ringbuffer,并且创建指定数量的子线程,最后等待子线程结束。子线程数量可以配置。 每个子线程即使生产者也是消费者。每次测试迭代从队列中读取一个单元,再将这个单元(不做额外操作)插入队尾,即一次 Dequeue 和一次 Enqueue 操作。整个测试过程需要执行的 Enqueue 和 Dequeue 操作数量相同。如果将一部分线程设置为生产者,另一部分线程设置为消费者,那么数据单元一定由生产者向消费者移动。这可能在互联结构中出现具有方向性的数据流,从而加强测试结果与线程调度的核心的物理位置的关系。 为了保证子线程同步启动测试,子线程首先会陷入 barrier。当所有子程序都创建完成后,子线程从 barrier 退出。每个线程执行的测试迭代数量都相同。
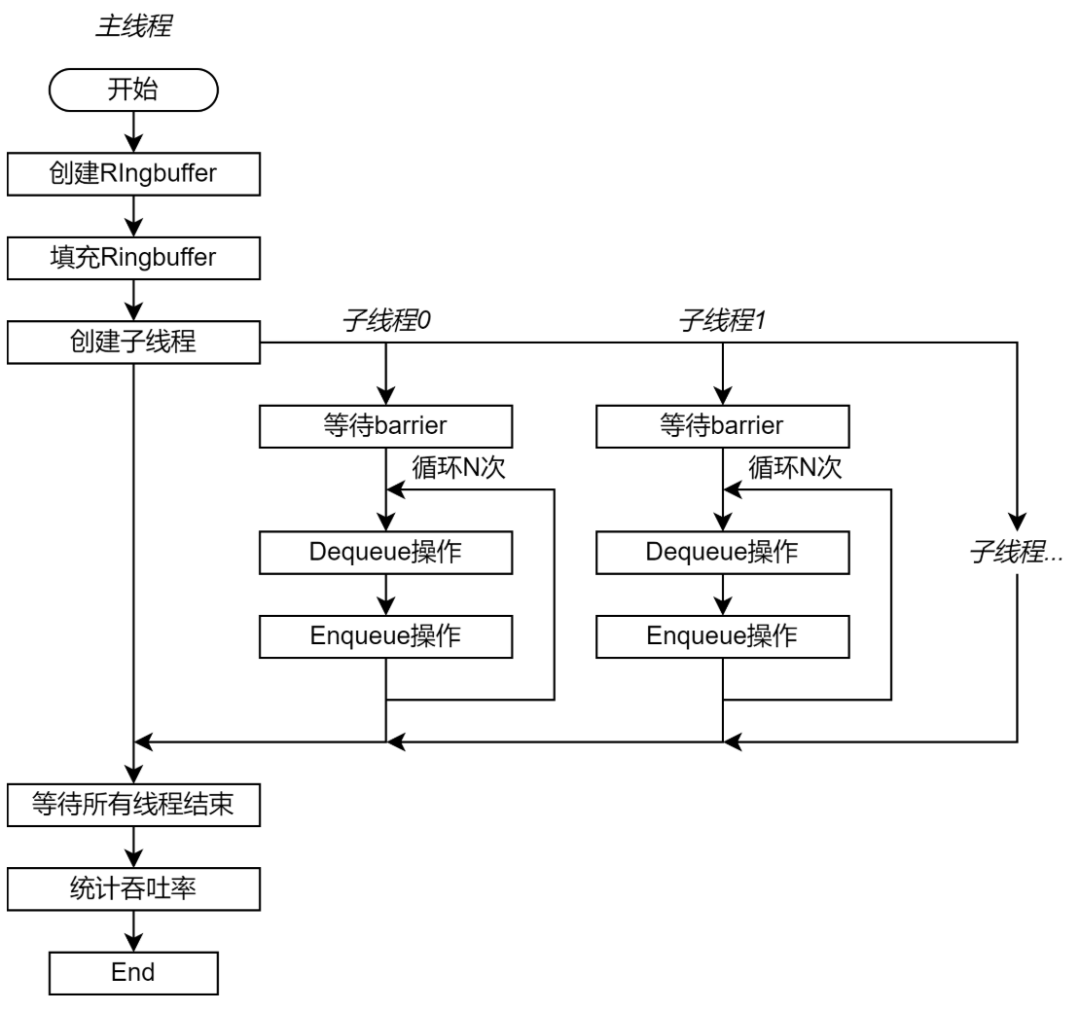
图 4 测试程序流程图 每个子线程独立统计测试阶段完成的时间,并且分别计算操作的吞吐率。这是为了避免统计过程引入新的共享数据。最后,主线程获取每个子线程统计的操作吞吐率,并且求和得到总吞吐率。吞吐率用每秒执行的 Enqueue 或 Dequeue 操作数量表示,即 op/s。 由于 Ringbuffer 的性能与存储系统的性能有直接关联,因此子线程调度到的核心对于具体实现具有很大的关系。为了保证测试的稳定性,需要将子线程调度到指定的核心(绑核)。如果不做绑核,那么相同实现的相同配置的不同测试结果可能会大相径庭,测试结果偏差极大。 测试框架的源码请参见https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/testbench/testbench.cc)。
基于 Mutex 的 Ringbuffer 实现的测试结果
测试采用的 Arm 服务器具有 32 个 N1 处理器,使用 CMN600 作为互联结果。测试用的 Arm 服务器上并没有区分 NUMA 结点,因此采用自然映射的关系,即子线程 0 调度到 CPU0;子线程 1 调度到 CPU1,以此类推。 图 5 展示了基于 Mutex 的 Ringbuffer 的性能测试结果。显然,随着子线程数量的增加,Ringbuffer 的吞吐率显著降低。当使用 2 个子线程时,吞吐率为 3985230 op/s;当使用全部 32 个子线程时,吞吐率为 323111 op/s。前者是后者的 12.3 倍。
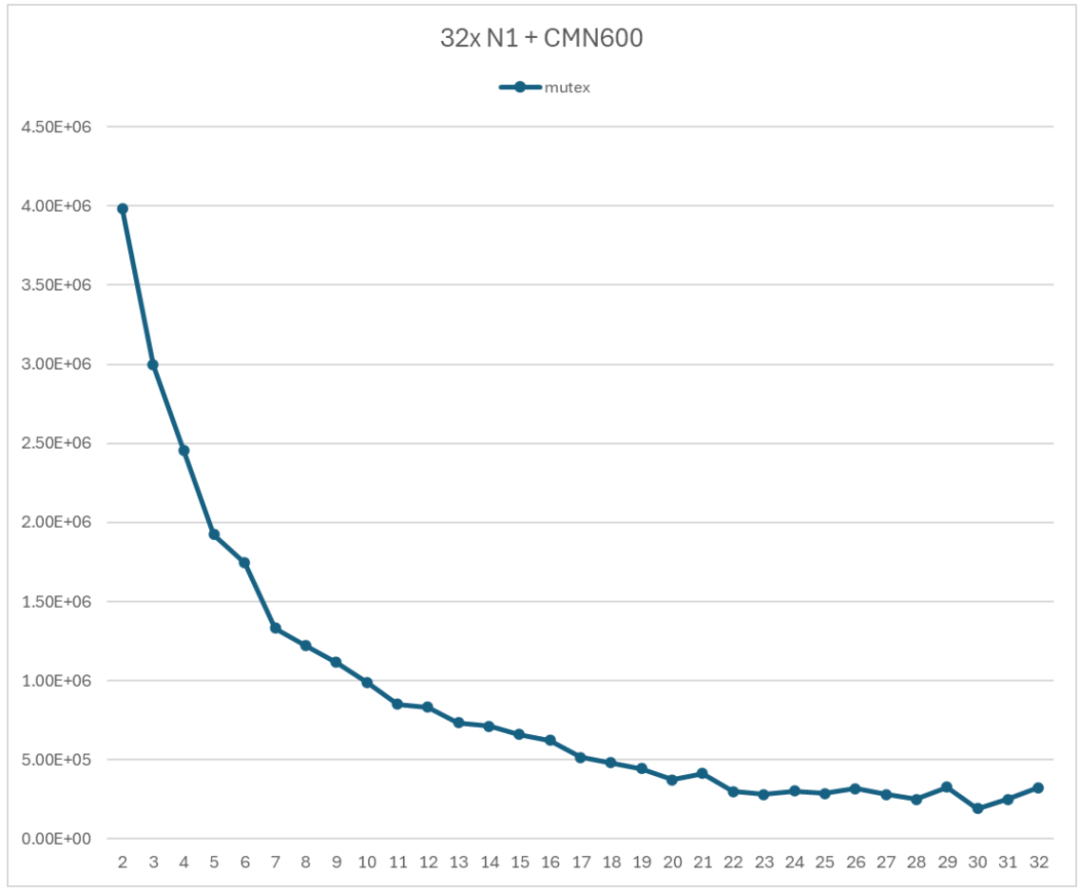
图 5 基于 Mutex 的 Ringbuffer 性能测试
图 5 展示的性能测试结果是典型的以多线程竞争为主导的性能曲线。随着参与竞争的子线程数增加,在竞争 mutex 上花费的时间就更多,导致性能快速下降。 使用 perf 工具对于启动 16 个线程的测试程序进行热点分析,热点分析结果如图 6 所示。图中橙色部分提示了lock函数占用了程序执行时间的 91%。因此,对于 Ringbuffer 进行优化的首要步骤就是采用无锁的实现方式。 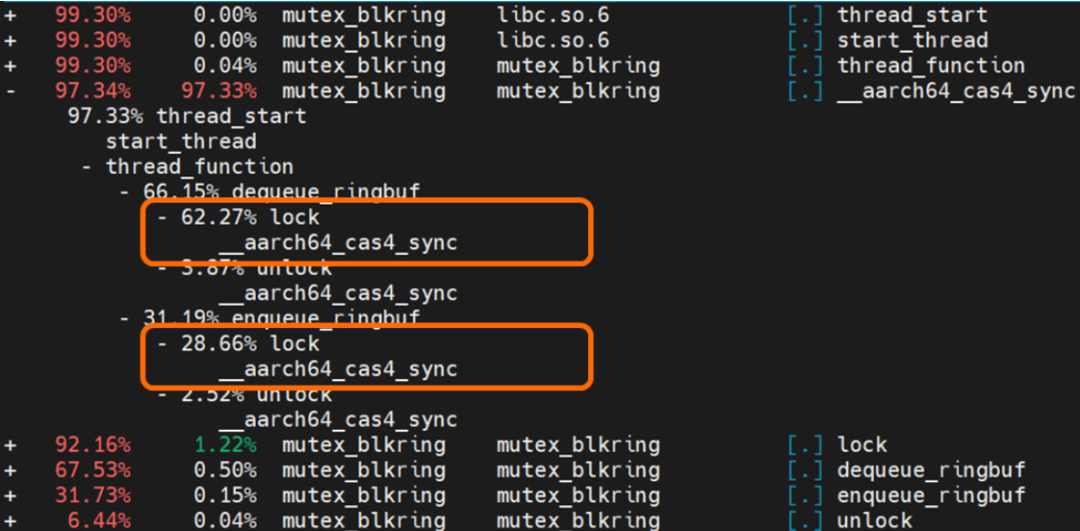 图 6 Perf 热点分析结果
图 6 Perf 热点分析结果
无锁 Ringbuffer 实现
对于多线程共享程序,需要使用 mutex 来保护对于共享变量的 load-modify-store 代码序列,从而保证功能正确性。但是 mutex 的竞争引入了非常明显的性能开销。因此,需要探索无锁的 Ringbuffer 实现。
用原子操作替代锁
除了 mutex,另一种可以保护共享变量的方法是原子操作。单个原子操作就是由 load-modify-store 三个部分构成。原子操作保证,在完成 load-modify-store 序列之前,被访问的地址不会被其他指令访问。典型的原子操作包括 Compare-and-swap (CAS),以及 Arm 提供的 LDADD 等原子操作。如果有多个 PE 针对同一个共享变量发起多个原子操作,那么这些操作只能按照某种顺序串行,而不能并行。执行顺序取决于硬件实现。 CAS 保证了对于 mutex 的操作都是串行的。例如 PE1 执行原子操作 CAS(x, 0, 1),同时 PE2 执行原子操作 CAS(x, 0, 2):
如果 PE1 先读取到 x 的值,那么 PE1 的 CAS 操作成功;PE2 读取到的 x 的值是 PE1 更新后的值=1,CAS 操作失败。最后 PE1 中返回值是 0;PE2 中返回值是 1;x 的值是 1。
如果 PE2 先读取到 x 的值,那么 PE2 的 CAS 操作成功;PE1 读取到的 x 的值是 PE2 更新后的值=2,CAS 操作失败。最后 PE1 的返回值是 2;PE2 的返回值是 0;x 的值是 2。
在 Ringbuffer 实现中,特别需要保护的就是被所有生产者和消费者共享的 head 和 tail 指针。可以用__atomic_fetch_add原语来实现指针的原子指令并且实现指针的累加。 __atomic_fetch_add原语的声明如下,其核心指令是 LDADD。原语读取ptr指向的变量,然后将变量累加val后的新值会写到原来的位置;同时,原语将ptr指令的变量的旧值返回。
type __atomic_fetch_add (type *ptr, type val, int memorder)将__atomic_fetch_add原语应用到 head 或 tail 指针上,则可以将存储在内存中的指针变量加 1,并且同时将加 1 前的旧值返回。这就相当于将目前 head/tail 指针指向的单元分配给了当前的 Enqueue 或 Dequeue 的生产者或消费者,同时与其他生产者或消费者同步了更新后的指针。
Enqueue 和 Dequeue
图 7 展示了 Enqueue 和 Dequeue 的流程图。
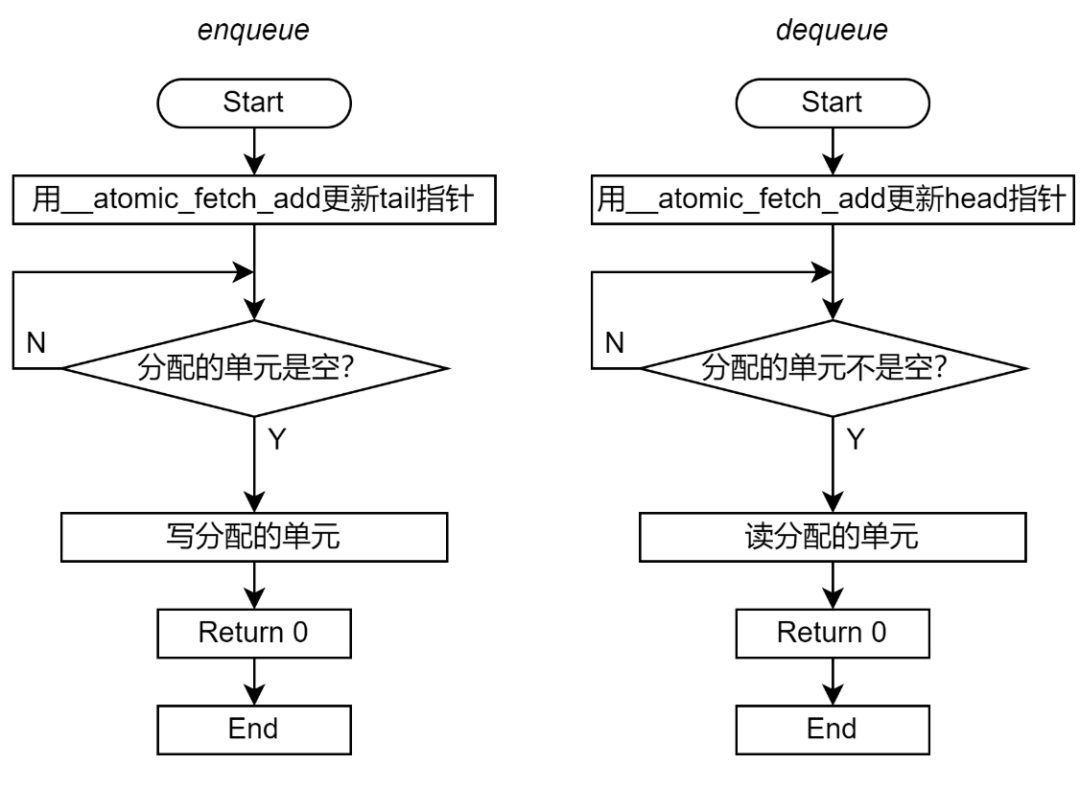
图 7 无锁 Ringbuffer 实现流程图(使用原子操作替换 mutex) 相对于基于 mutex 的 Ringbuffer 实现,无锁 Ringbuffer 实现从软件和硬件两方面的优化。 从软件的角度,无锁 Ringbuffer 的关键区要小很多。在基于 mutex 的 Ringbuffer 实现(图 8 左侧)中,锁保护了整个 Enqueue 和 Dequeue 过程,每个 Enqueue 和 Dequeue 过程都只能串行执行。在无锁 Ringbuffer 实现(图 8 右侧)中,原子指令只保护了对于 head 或 tail 指针的累加。除了__atomic_fetch_add必须串行,其他部分都是可以并行的,从而增加了程序的并行度。
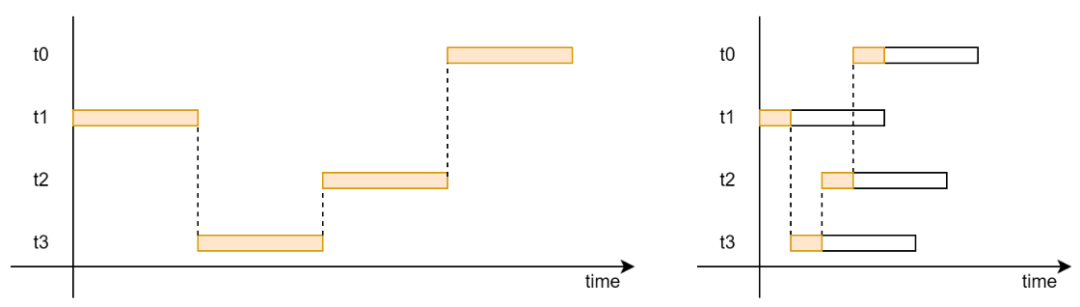
图 8 基于 mutex 的 Ringbuffer 实现和无锁 Ringbuffer 实现的关键区(着色部分)对比 从硬件的角度,原子指令引入更少的 snoop 操作。使用常规的 load 指令读取数据后,在 PE 侧的缓存中的数据副本的状态为 Share(共享)。所有访问这个数据的 PE 的缓存都会具有这个共享数据的副本。当共享数据被某个 PE 修改后,需要大量的 snoop 去失效其他 PE 中的所有副本。 使用原子指令读取数据之后,数据的缓存状态为 Exclusive(独有),即只有一个 PE 具有这个共享数据的副本。当另一个 PE 也执行原子操作后,只需要一个 snoop 就可以将已经存在副本清除。 从带宽的角度,更少 snoop 数量意味着 snoop 通信占用的通信带宽更少,提供给数据通信的带宽就会更高。从延迟的角度,load/store 操作需要等到其引起的所有 snoop 都完成才能被标识为完成。更少的 snoop 数量意味着等待 snoop 完成的时间更短。 无锁 Ringbuffer 同时从这两方面优化中受惠,暂时没有办法定量分析出哪一个优化的作用更大。一般来说,缩小关键区的作用更大。
逻辑单元序号
上述的无锁 Ringbuffer 仍然可能导致功能错误。例如一个 Ringbuffer 有 16 个物理单元。首先为生产者 A 分配的逻辑单元是 16;随后,为生产者 B 分配的单元是 32;这两个单元映射到相同的物理单元 0。虽然单元分配和指针更新是串行的,但是对于数据单元的访问是并行的,因此并不能保证生产者 B 访问物理单元 0 时,生产者 A 一定完成了操作。可能生产者 A 和生产者 B 同时查询到单元是空闲,进而同时对这个物理单元进行写入。此时无法保证写入单元的究竟是生产者 A 的数据还是生产者 B 的数据。 为了解决这样的问题,Ola 提出,给每个单元增加一个域来表示其对应的逻辑单元序号。只有当逻辑单元序号与 head/tail 指针一致的时候才能进行访问。当 Dequeue 单元的时候,需要更新逻辑单元序号,将单元的序列号增加物理单元的总数。 还是上面的例子,当生产者 A 和 B 同时查询到内存是空闲时,由于单元的序列号与生产者 A 分配的单元匹配,那么生产者 A 可以操作这个单元;生产者 B 则因为序列号不匹配而不能访问,需要继续等待。 增加逻辑单元序号后的 Enqueue 和 Dequeue 流程图如图 9。
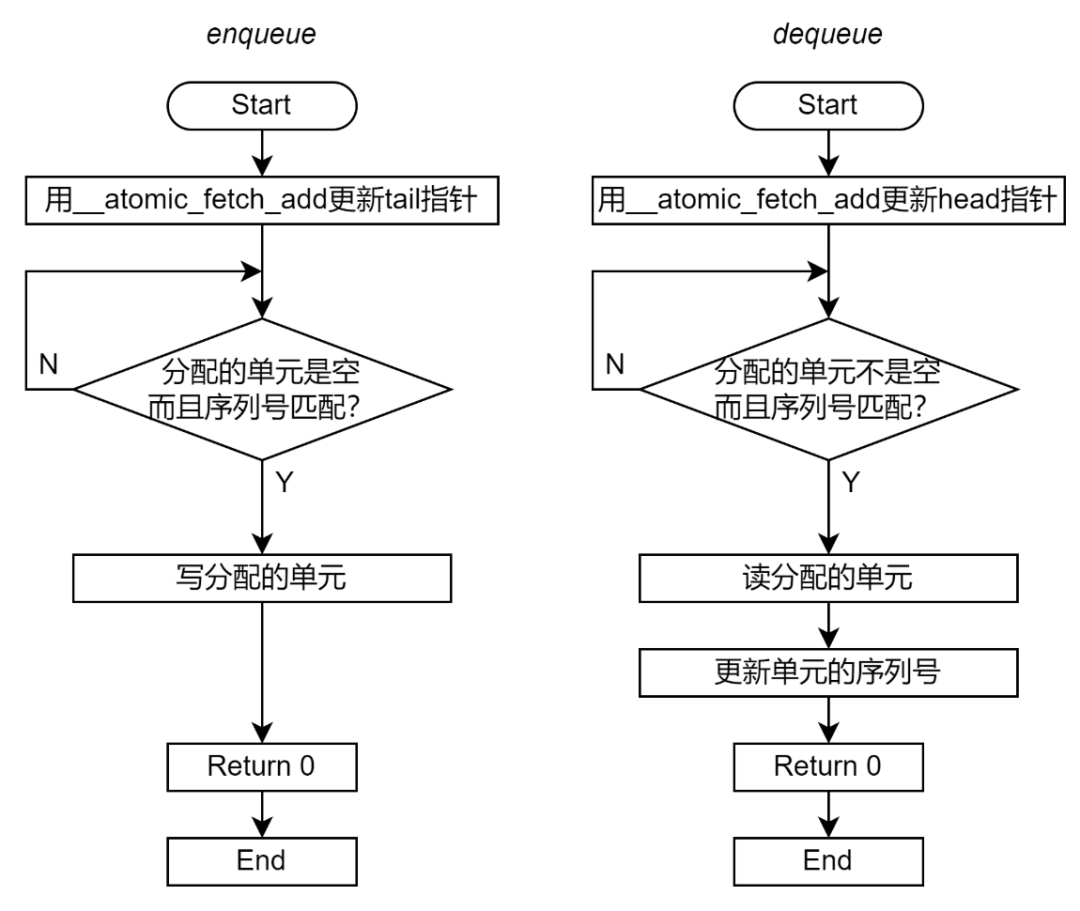
图 9 无锁 Ringbuffer 实现流程图(使用原子操作替换 mutex)
无锁 Ringbuffer 声明
无锁 Ringbuffer 的声明如下。Ringbuffer 不需要 mutex 进行保护。
// Entry in ring buffer
class BufferEntry
{
public:
unsigned int m_sn; // Sequential number.
void *mp_ptr; // Pointer to data entry.
};
class RingBuffer
{
public:
unsigned int m_size; // The number of physical entries.
unsigned int m_head; // Head pointer.
unsigned int m_tail; // Tail pointer.
BufferEntry *mp_entries; // Pointer to physical entries.
}
代码 3 无锁 Ringbuffer 声明
无锁 Ringbuffer 的 Enqueue 和 Dequeue 函数
Enqueue 和 Dequeue 函数的实现如下。
// Blocking Enqueue Function
int enqueue_ringbuf(RingBuffer *ring_buffer, void *entry)
{
// Update the tail pointer.
int sn = __atomic_fetch_add(&ring_buffer->m_tail, 1, __ATOMIC_RELAXED);
int enq_ptr = sn % ring_buffer->m_size;
// Check the data entry until empty.
unsigned int entry_sn;
void *entry_ptr;
do
{
// Replace load by atomic load.
// entry_sn = __atomic_load_n(&ring_buffer->mp_entries[enq_ptr].m_sn, __ATOMIC_RELAXED);
// entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, __ATOMIC_RELAXED);
entry_sn = ring_buffer->mp_entries[enq_ptr].m_sn;
entry_ptr = ring_buffer->mp_entries[enq_ptr].mp_ptr;
} while (entry_sn != sn || entry_ptr != NULL);
// Write entry.
// Replace store by atomic store.
// __atomic_store_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, entry, __ATOMIC_RELEASE);
ring_buffer->mp_entries[enq_ptr].mp_ptr = entry;
return 0;
}
// Blocking Dequeue Function
int dequeue_ringbuf(RingBuffer *ring_buffer, void **entry)
{
// Update the head pointer.
int sn = __atomic_fetch_add(&ring_buffer->m_head, 1, __ATOMIC_RELAXED);
int deq_ptr = sn % ring_buffer->m_size;
// Check the data entry until not empty.
unsigned int entry_sn;
void *entry_ptr;
do
{
// Replace load by atomic load.
// entry_sn = __atomic_load_n(&ring_buffer->mp_entries[deq_ptr].m_sn, __ATOMIC_RELAXED);
// entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, __ATOMIC_ACQUIRE);
entry_sn = ring_buffer->mp_entries[deq_ptr].m_sn;
entry_ptr = ring_buffer->mp_entries[deq_ptr].mp_ptr;
} while (entry_ptr == NULL || entry_sn != sn);
// Read entry.
*entry = entry_ptr;
// Replace store by atomic store
// __atomic_store_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, 0, __ATOMIC_RELAXED);
ring_buffer->mp_entries[deq_ptr].mp_ptr = 0;
// Update sequence number.
// Replace store by atomic store
// __atomic_store_n(&ring_buffer->mp_entries[deq_ptr].m_sn, sn + ring_buffer->m_size, __ATOMIC_RELEASE);
ring_buffer->mp_entries[deq_ptr].m_sn = sn + ring_buffer->m_size;
return 0;
}
代码 4 无锁 Ringbuffer 的 Enqueue 和 Dequeue 函数
Enqueue 和 Dequeue 函数中对于数据单元的 load/store 操作可以进一步被原子操作__atomic_load_n和__atomic_store_n取代。代码 4 中的注释给出了可以替换的原子操作。
无锁 ringbuffer 实现的完整源码请参见(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/lockfree_blkring.h)。
使用原子操作数据单元的无锁 Ringbuffer 实现的完整源码请参见(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/atomic_blkring.h)。
无锁 Ringbuffer 性能测试结果
无锁 Ringbuffer 的性能如图 10 所示。曲线 mutex 表示基于 mutex 的 Ringbuffer 实现;lockfree 和 atomic 表示无锁 Ringbuffer 实现(lockfree 使用普通 load/store 操作数据单元;atomic 使用原子 load/store 操作数据单元)。
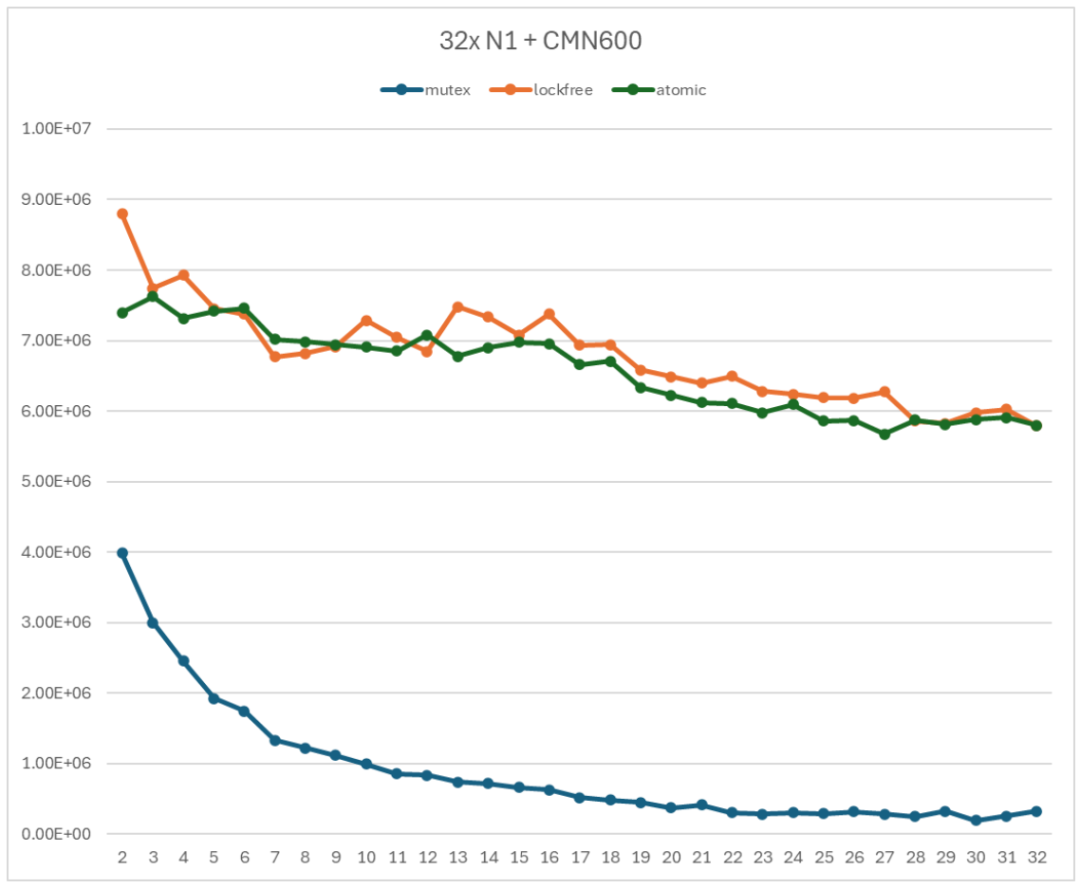
图 10 无锁 Ringbuffer 性能测试
从图 10 中可以发现,相对于基于 mutex 的 Ringbuffer 实现,无锁 Ringbuffer 实现的性能得到了很大的提升。用 atomic 曲线和 mutex 曲线进行比较。当只有 2 个线程时,无锁 Ringbuffer 实现的吞吐率是基于 mutex 的 Ringbuffer 实现的吞吐率的 1.86 倍;当使用 32 个线程时,无锁 Ringbuffer 实现的吞吐率是基于 mutex 的 Ringbuffer 实现的吞吐率的 18 倍。
从图 10 中可以发现,对于数据单元的访问是否使用原子操作对于性能的影响并不明显。两条曲线基本上是重合的。这是因为测试的 ringbuffer 提供了足够的单元,多个线程共享 Ringbuffer 单元的竞争并不强烈。
无锁 Ringbuffer 实现的吞吐率还是会随着子线程数增加而降低,但是并不如基于 mutex 的 Ringbuffer 强烈。当使用 2 个子线程时,吞吐率为 7394830 op/s;当使用全部 32 个子线程时,吞吐率为 5800350 op/s。前者是后者的 1.27 倍。
利用 Perf 分析程序热点只能定位到特点在 enqueue 和 dequeue 函数,无法提供进一步的信息。因此使用 Arm 的 top-down 工具对于微架构执行情况进行详细分析,得到的结果如图 11。
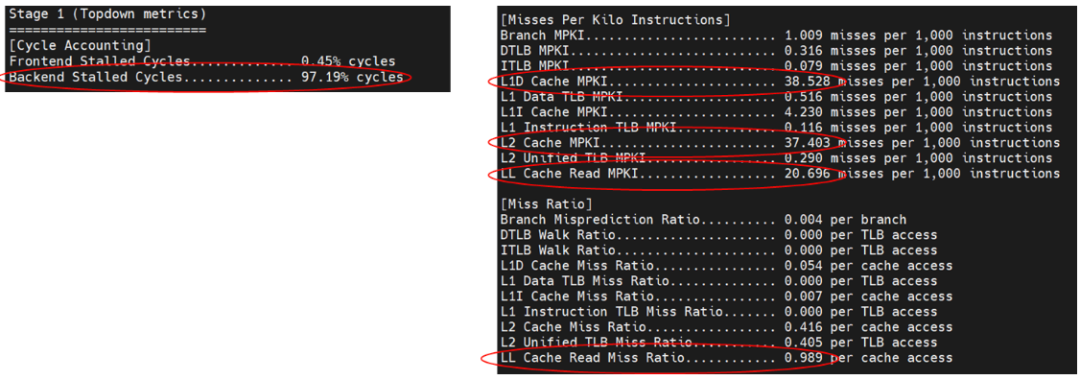
图 11 利用 Top-down 对无锁 Ringbuffer 进行性能分析
图 11 中用红圈标注了主要注意的指标。首先,程序明确属于后端瓶颈的程序,后端阻塞周期高达 97%。其次,L1、L2 和 LC(Last-level cache)明显高于其他异常情况,这表示程序中存在大量的数据竞争。最后 L1、L2 和 LC 的数据缺失率属于同一量级,这表示数据竞争是全局性的,需要通过系统的最后一级缓存才能得到解决。top-down 的分析结果提示,无锁的 ringbuffer 实现仍然导致了大量的全局性的数据冲突。
无锁 Ringbuffer 的对齐改进
通过对于程序的分析,符合上述特征的共享数据只有 head 和 tail 指针。因为 head 和 tail 指针处于相同的缓存行。这就导致生产者和消费者仍然在竞争同一个缓存行。可以通过对与 Ringbuffer 的数据结构进行缓存行对齐,减少不同生产者和消费者竞争同一个缓存行的情况。
Ringbuffer 实现的缓存行对齐包含两个部分:
head/tail 指针的对齐。将 head 指针和 tail 指针分别放置到不同的缓存行。这可以通过 C 语言原语 alignas 实现。
class RingBuffer
{
public:
alignas(64) unsigned int m_size;
alignas(64) unsigned int m_head;
alignas(64) unsigned int m_tail;
alignas(64) BufferEntry *mp_entries;
}
代码 5 对齐的无锁 Ringbuffer 的声明
这样只有生产者竞争 tail 指针所在的缓存行;消费者竞争 head 指针所在的缓存行。
数据单元的对齐。这是为了避免访问不同单元的线程因为单元处于相同缓存行而产生竞争。比如访问物理单元 0-3 的线程实际上在竞争同一个缓存行。
这一部分可以通过空间换效率的方式实现。一个缓存行(64B)中可以放置 4 个单元(每个单元 16B,8B 指针和 8B 序列号)。在初始化时分配 4 倍的单元,在 Enqueue 和 Dequeue 每次都只使用 4 对齐的序号。逻辑单元 0 对应到物理单元 0;逻辑单元 1 对应到物理单元 4;依次类推。
物理单元序号计算方法如下:
int enq_ptr = (sn % ring_buffer->m_size) * 4;
代码 6 对齐的无锁 Ringbuffer 映射逻辑单元到物理单元
对齐后的无锁 ringbuffer 的内存分布如下。其中红色部分是实际访问的数据单元。绿色部分是没有使用到的数据单元。
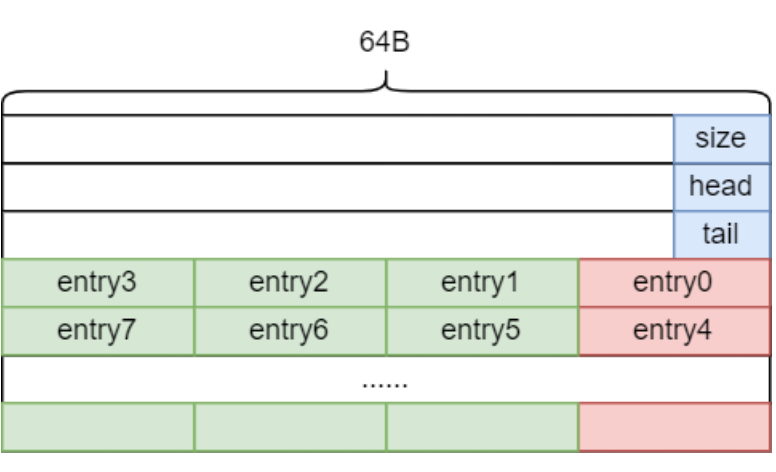
图 12 对齐后的无锁 Ringbuffer 的内存分布
需要说明的是,当物理数据单元数量远大于生产者和消费者数量时,数据单元的对齐对于性能的影响非常微小。因为共享一个缓存行的线程数量很小,最多只有 4 个。
缓存行对齐的无锁 ringbuffer 实现的完整源码请参见(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/align_blkring.h)。
对齐的无锁 Ringbuffer 性能测试结果
缓存行对齐的无锁 Ringbuffer 的性能如图 13 所示。曲线 mutex 表示基于 mutex 的 Ringbuffer 实现;lockfree 和 atomic 表示无锁 Ringbuffer 实现(lockfree 使用普通 load/store 操作数据单元;atomic 使用原子 load/store 操作数据单元);align 表示缓存行对齐后的无锁 Ringbuffer 实现。
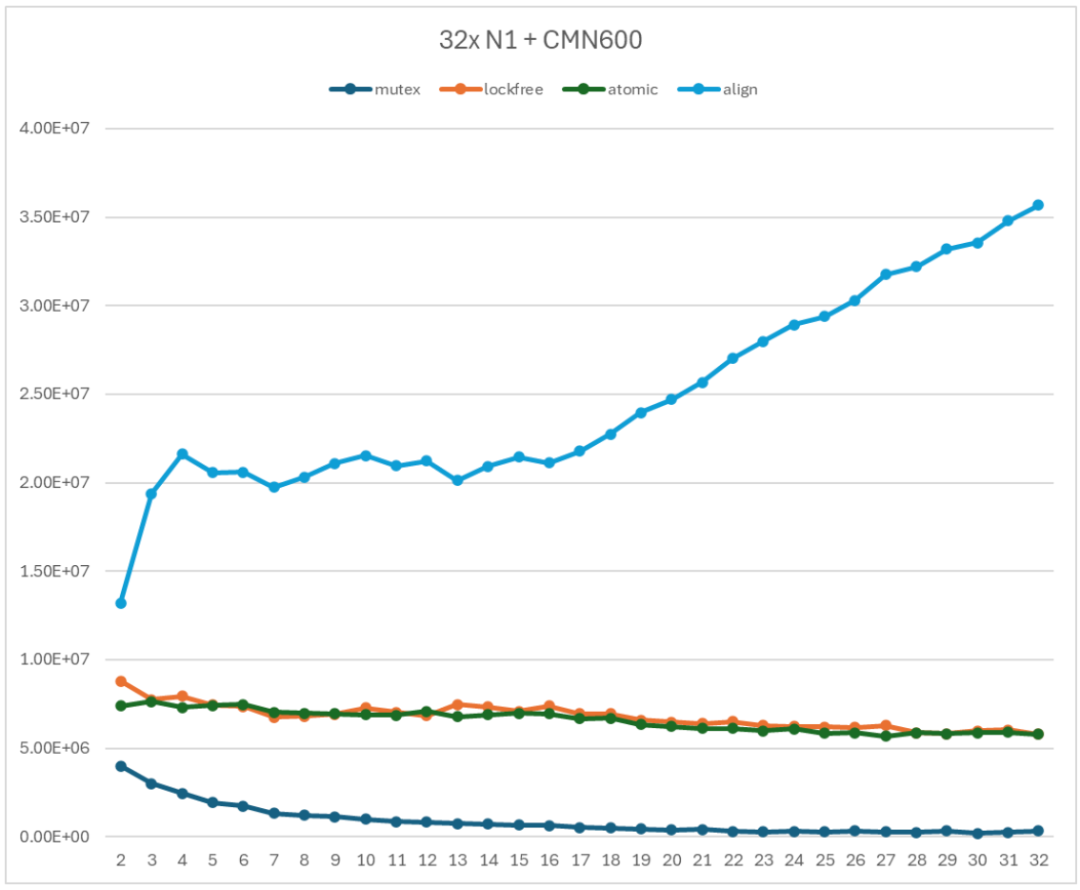
图 13 对齐的无锁 Ringbuffer 性能测试
缓存行对齐的无锁 Ringbuffer 实现的性能曲线随着子线程数量的增加呈现增长的趋势。具体来说,
首先,当子线程数小于 16 时,吞吐率随着子线程数增加而趋向于一个稳定的值。这个稳定值受限于是互联网络能够提供的最大带宽。
其次,当子线程数大于 16 时,吞吐率随着子线程数增加而增加。这与互联结构的拓扑有关系。当子线程数大于 32 时,新的子线程被分配到互联结构的另一半部分,从而使得能够利用的带宽增加。
用 align 曲线和 mutex 曲线进行比较。当只有 2 个线程时,无锁 Ringbuffer 实现的吞吐率是基于 mutex 的 Ringbuffer 实现的吞吐率的 3.31 倍;当使用 16 个线程时,无锁 Ringbuffer 实现的吞吐率是基于 mutex 的 Ringbuffer 实现的吞吐率的 33.8 倍。当使用 32 个线程时,无锁 Ringbuffer 实现的吞吐率是基于 mutex 的 Ringbuffer 实现的吞吐率的 110 倍。
缓存行对齐的无锁 Ringbuffer 实现的性能曲线与基于 mutex 的 Ringbuffer 实现和无锁 Ringbuffer 的实现有本质上的不同,呈现了一种互联带宽测试的规律。这表示缓存行对齐的无锁 Ringbuffer 实现能够充分利用互联网络提供的通信性能,是一个非常有利于系统规模扩展的 Ringbuffer 实现。
非阻塞 Ringbuffer 实现
前文介绍的无锁 Ringbuffer 实现存在一个重大的功能缺陷,就是上述实现只能构建阻塞式的 Ringbuffer。当生产者或消费者进入 Enqueue 或 Dequeue 函数后,生产者或消费者的程序会一直尝试操作,直到操作成功才能推出 Enqueue 或 Dequeue 函数。
在实际软件更加倾向于实现非阻塞的 Ringbuffer。因为当 Enqueue 或 Dequeue 操作不成功时,软件可以主动进行线程调度或休眠,将处理器资源让渡给可以进行操作的线程或任务。这有利于提高资源利用率。
指针保护
这里分三个步骤来推演非阻塞 Ringbuffer 的实现。
第一步。为了能够实现非阻塞的 Ringbuffer,那么仍然需要在 Enqueue 和 Dequeue 函数的开始的时候检查队列的空满情况。如果 Ringbuffer 不满足进行 Enqueue 或 Dequeue 的条件,则退出函数并且返回错误代码。
考虑到这一点,非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的流程应当如下图:
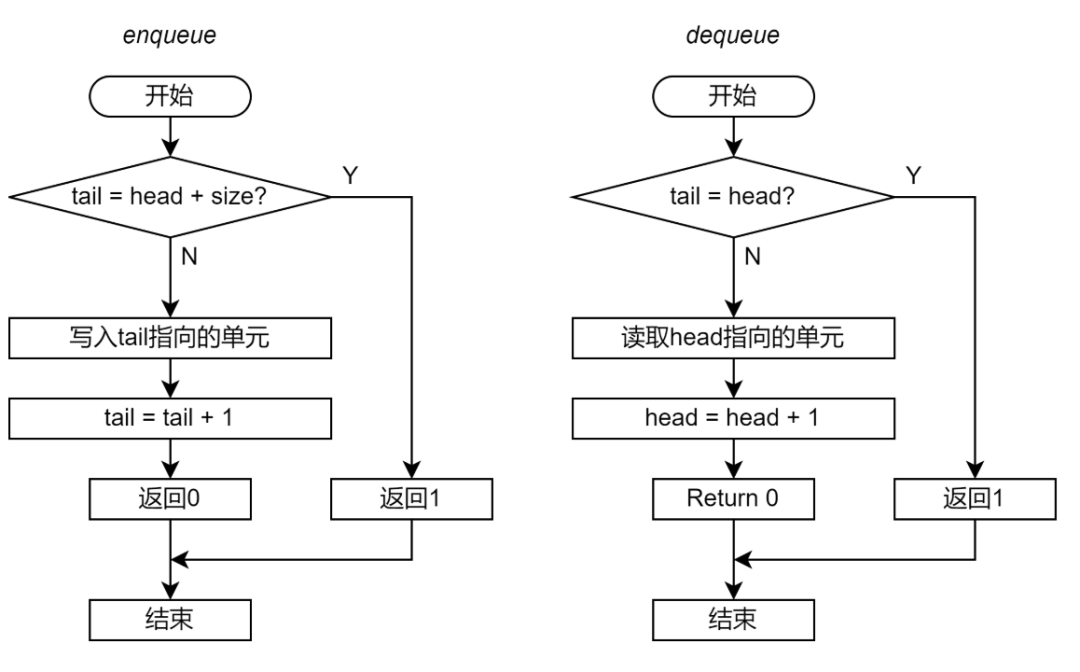
图 14 非阻塞无锁 Ringbuffer 实现的流程图(第一步)
第二步。非阻塞实现要使用原子指令替代 mutex 保护指针。但是原子指令可以保护对于一个共享变量的 load-modify-store 序列,但是不能保证对于多个共享变量的 load-modify-store 之间的原子性。因此,Enqueue 中只能用原子指令保护 tail 指针;Dequeue 中只能用原子指令保护 head 指针。
考虑到这一点,非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的流程应当如下图:
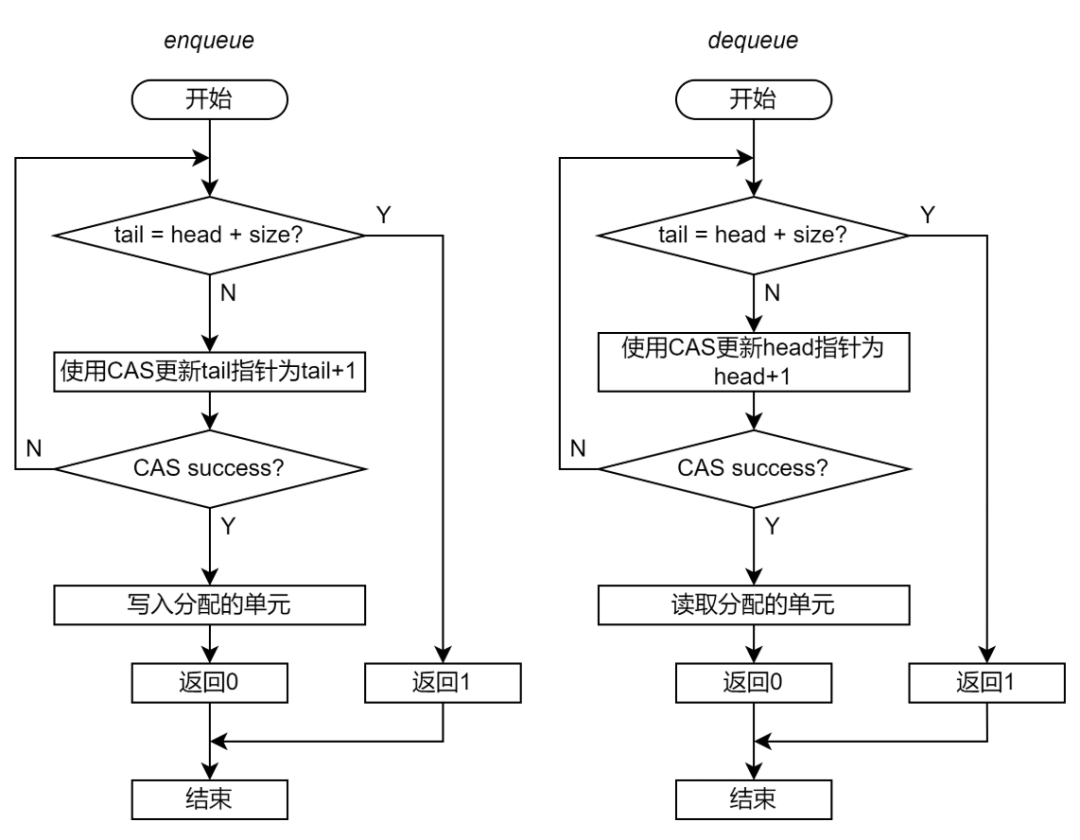
图 15 非阻塞无锁 Ringbuffer 实现的流程图(第二步)
以 enqueue 为例,函数首先读取指针判断空满条件。如果 Ringbuffer 不满,则执行 CAS(tail_addr, tail, tail+1)。
如果 CAS 成功,则表示从判断空满条件到更新 tail 这段时间,没有其他线程修改了 tail 指针,那么可以将 tail 指向的单元分配给当前线程,并且更新 CAS。
如果 CAS 失败,则表示从判断空间条件到更新 tail 这段时间,其他线程修改了 tail 指针。此时,需要返回函数开始的地方重新判断空满条件。
这种方法可以保证 tail 指针的更新是原子的,每个生产者都是在最新的 tail 值基础上进行更新。
这里使用的是__atomic_compare_exchange_n原语。
bool __atomic_compare_exchange_n (type *ptr, type *expected, type desired, bool weak, int success_memorder, int failure_memorder)
__atomic_compare_exchange_n读取ptr指向的变量,与expected指向的变量比较。如果两者数值相同,则更新ptr指向的变量为desired,并且返回真。如果数值不同,则将读取的数值赋值给expected指向的变量,同时返回假。
第三步。从生产者的角度,Enqueue 函数需要在检查空满条件后分配一个单元给当前线程,并且让其他生产者知道更新后的 head 或 tail 值。第二步中引入的 CAS 操作保证了这一点。另一方面,消费者需要等到分配的单元被填充后才能知道指针的更新。也就是说,生产者和消费者看到指针更新的时间不同。
因此,非阻塞无锁 Ringbuffer 引入了两组指针分别针对生产者和消费者,即 prod_head/prod_tail,和 cons_head/cons_tail,如图 15 所示。
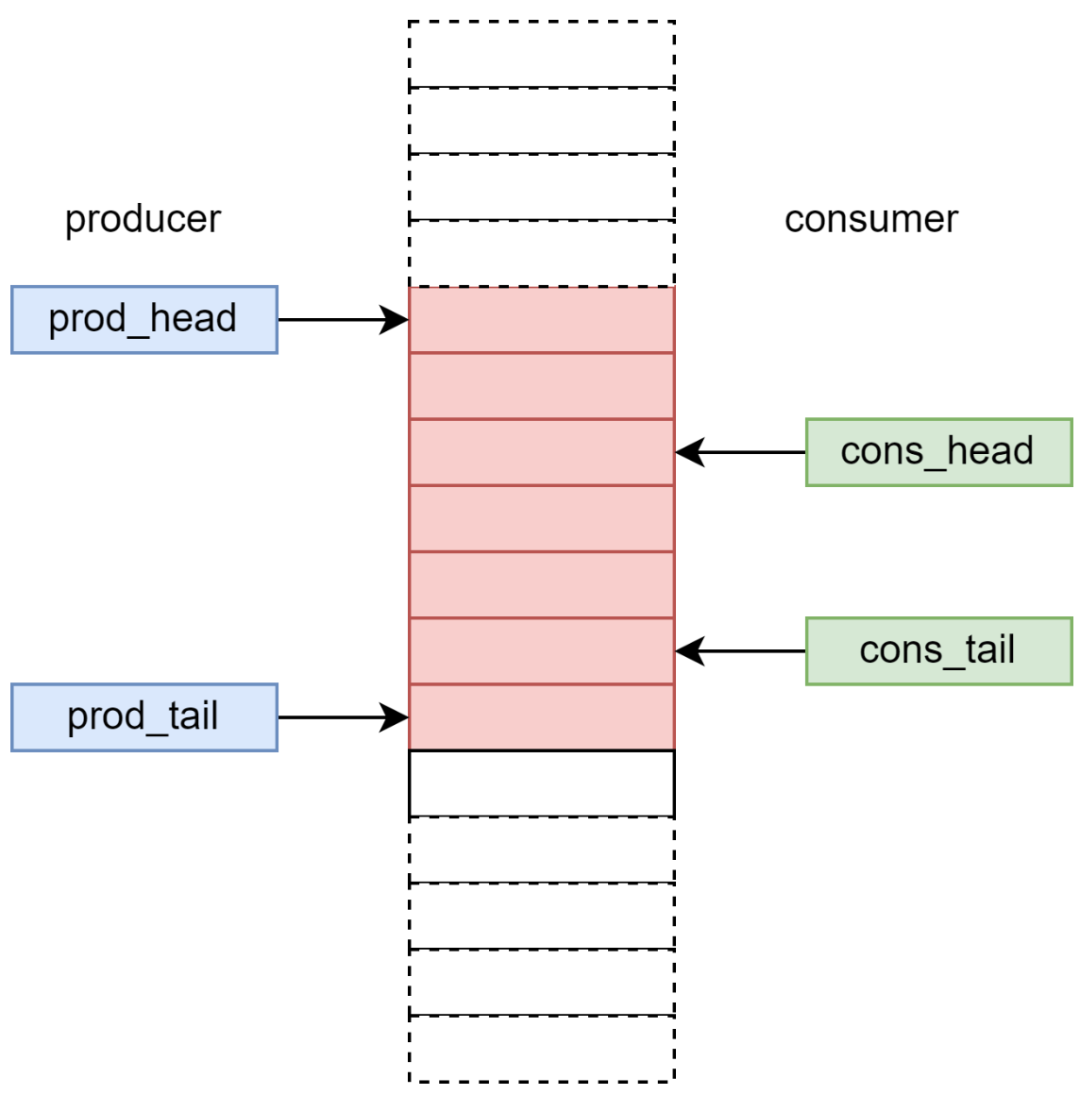
图 16 生产者和消费者指针示意图
对于生产者来说,其 prod_tail 指针一定是准确的,但是 prod_head 指针并不是最新的。这会导致生产者认为 Ringbuffer 中被占用的单元数多于实际被占用的单元数量,从而导致生产者错误地认为队列是满的,而放弃 Enqueue 操作。类似地,对于消费者来说,其 cons_head 指针一定是准确的,但是 cons_tail 指针并不是最新的。那么消费者可能认为空闲单元少于实际的空闲单元,从而导致消费者错误地认为队列是满的,而放弃 Dequeue 操作。这样的误导判断虽然会导致生产者和消费者对于 Ringbuffer 的竞争比较保守,结果是 Ringbuffer 效率降低,但是不会引起功能错误。
考虑到这一点,非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的流程应当如下图:
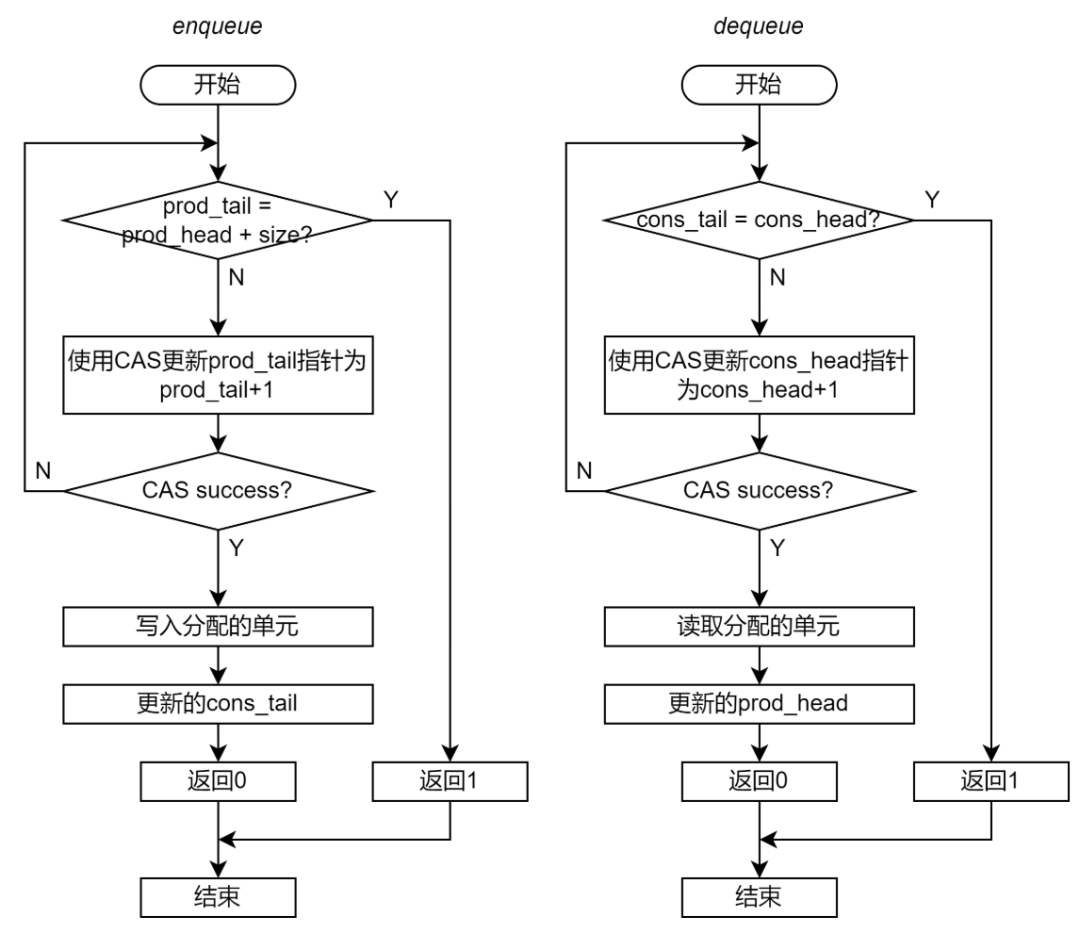
图 17 非阻塞无锁 Ringbuffer 实现的流程图(第三步)
生产者和消费者的指针同步
当 Enqueue 操作完成时,需要将生产者视角的 prod_tail 指针同步到消费者视角的 cons_tail 指针,告知消费者这些单元已经完成了 Enqueue 操作;当 Dequeue 操作完成时,需要将消费者的 cons_head 指针同步到消费者的 prod_head 指针,告知生产者这些单元已经完成了 Dequeue 操作。
但是这并不能够天然保证的。因为除了针对 prod_tail 和 cons_head 指针的 CAS 操作,Enqueue 和 Dequeue 函数的其他部分都是并行,如图 18 所示。因此,某个线程的分配单元完成 Enqueue 或 Dequeue 操作时,完全不能推测这个单元之前的其他单元是否完成了 Enqueue 或 Dequeue 的操作。
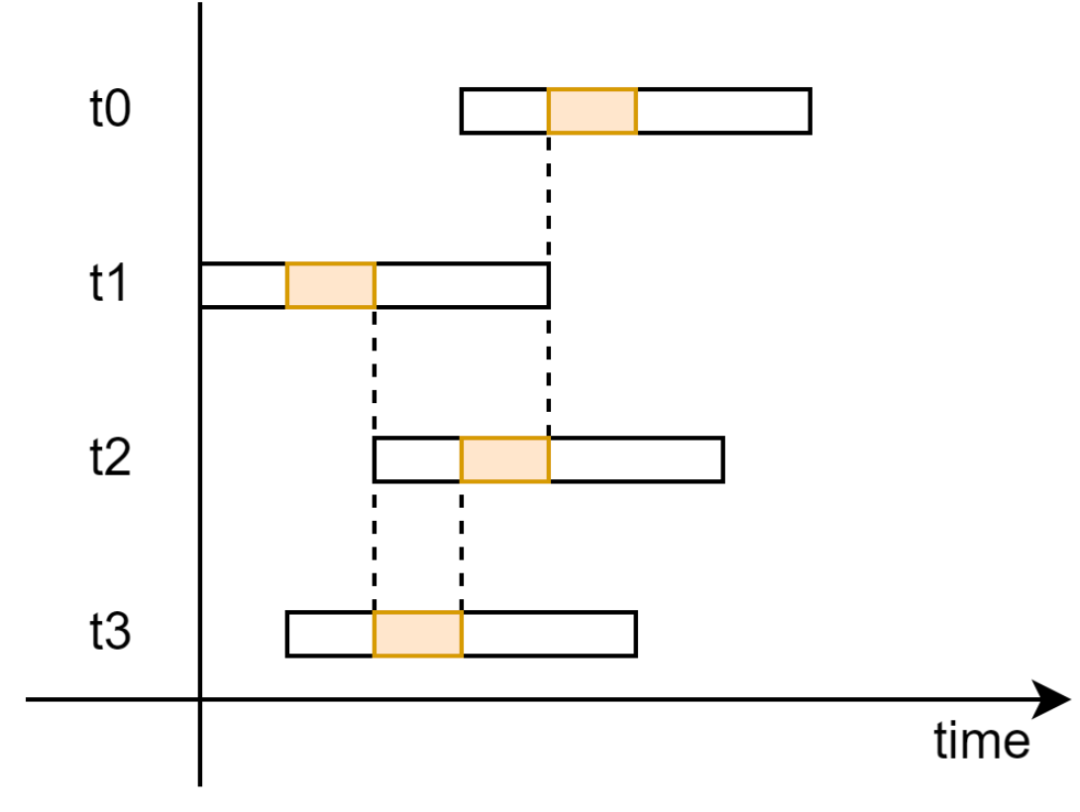
图 18 非阻塞无锁 Ringbuffer 的执行时序示意图
指针同步方式有很多种实现方法,主要分为顺序释放和乱序释放两种实现方法。
顺序释放。要求同步到另一个视角的单元必须完成了 Enqueue 或 Dequeue 操作。这就需要在更新指针前对于单元进行检查,只能将操作完成的单元可以同步给另一个视角。
比如,某个线程的 Enqueue 函数分配的单元为 16,此时 cons_tail 的值是 10,则 Enqueue 函数不能更新 cons_tail。只有 cons_tail 的值是 15 时才能更新 cons_tail。这样才能保证之前的物理单元都已经完成了 Enqueue 操作。
为了保证指针操作的原子性,需要使用__atomic_compare_exchange_n原语更新另一个视角的指针。
乱序释放。在同步不同视角的指针时,不检查单元是否已经完全写入完成,而是直接将指针加 1。这就会导致在后续 Enqueue 或 Dequeue 种分配的单元不能满足操作的要求。
比如,某个线程的 Enqueue 函数分配的单元为 16,此时 cons_tail 的值是 10。当这个 Enqueue 函数完成时将 cons_tail 更新为 11,但是此时对于物理单元 11 的操作状态未知。物理单元 11 有可能已经完成了 Enqueue 操作,也有可能物理单元 11 还是空的。
为了避免功能错误,则需要在操作分配的单元时进行检查。对于 Enqueue,如果分配的单元不为空,则一直等待;类似地,对于 Dequeue,如果分配的单元为空,则也要一直等待。
为了保证指针操作的原子性,需要使用__atomic_fetch_add原语更新另一个视角的指针。
至此,我们推导出了,非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的完整流程,如图 19 所示。
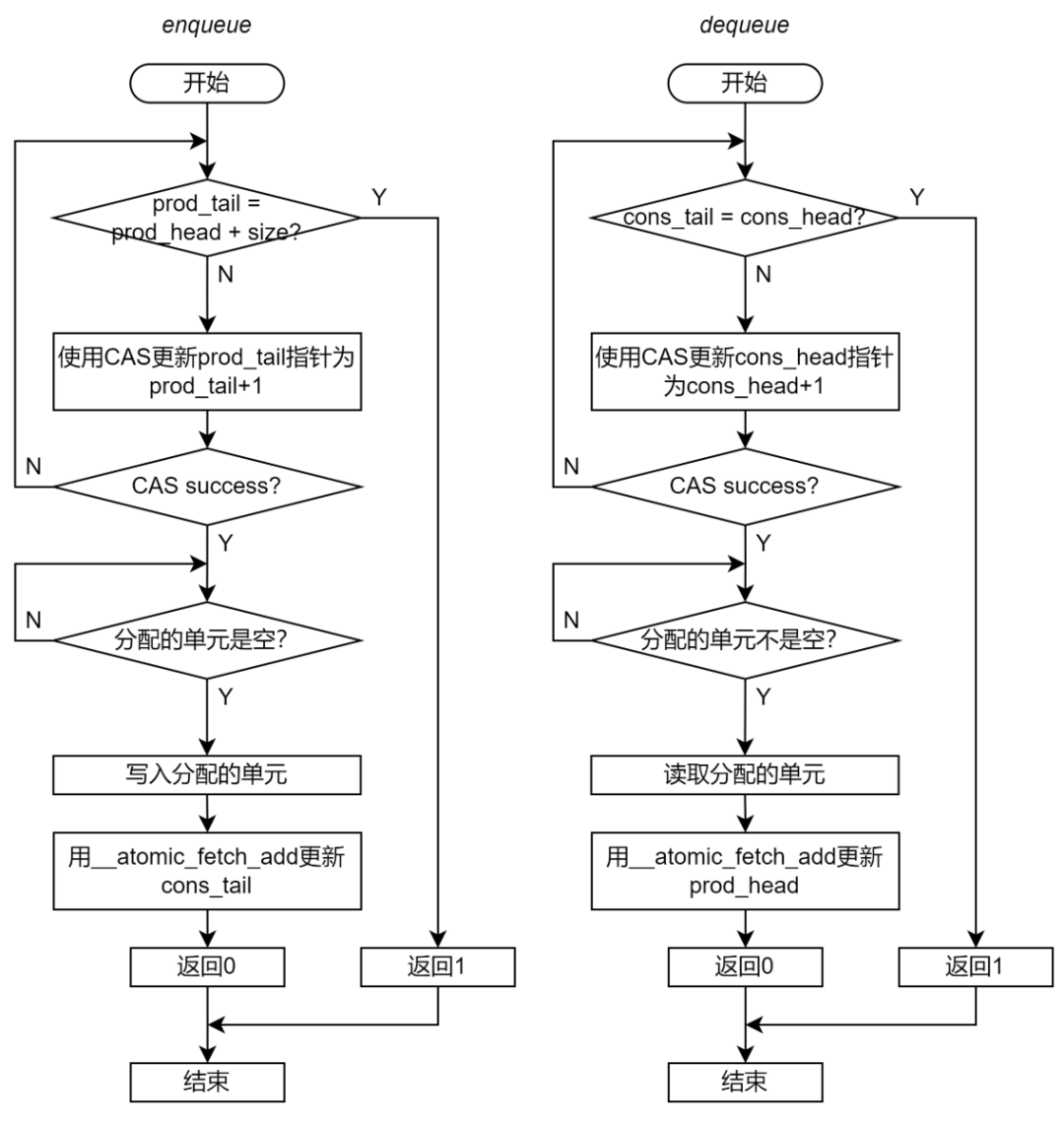
图 19 非阻塞无锁 Ringbuffer 实现的流程图
Ringbuffer 声明
非阻塞的无锁 Ringbuffer 不需要序列号。每个数据单元中只有一个指向实际数据结构的指针。
// Entry in ring buffer
class BufferEntry
{
public:
void *mp_ptr; // Pointer to data entry.
};
class RingBuffer
{
public:
alignas(64) unsigned int m_size;
// Pointers in the view of producer.
alignas(64) unsigned int m_prod_head; // read pointer
alignas(64) unsigned int m_prod_tail; // write pointer
// Pointers in the view of consumer.
alignas(64) unsigned int m_cons_head; // write pointer
alignas(64) unsigned int m_cons_tail; // read pointer
alignas(64) BufferEntry *mp_entries;
};
代码 7 非阻塞无锁 Ringbuffer 的声明
Enqueue 和 Dequeue
本文测试的非阻塞 Ringbuffer 实现采用了乱序释放的方法。
int enqueue_ringbuf(RingBuffer *ring_buffer, void *entry)
{
// Step 1: acquire slots
unsigned int tail = __atomic_load_n(&ring_buffer->m_prod_tail, __ATOMIC_RELAXED);
do
{
unsigned int head = __atomic_load_n(
&ring_buffer->m_prod_head, __ATOMIC_ACQUIRE);
if (ring_buffer->m_size + head == tail)
{
return 1;
}
} while (!__atomic_compare_exchange_n(&ring_buffer->m_prod_tail,
&tail, // Updated on failure
tail + 1,
/*weak=*/true,
__ATOMIC_RELAXED,
__ATOMIC_RELAXED));
// Step 2: Write slots
int enq_ptr = (tail % ring_buffer->m_size) * 8;
void *entry_ptr;
do
{
entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, __ATOMIC_RELAXED);
} while (entry_ptr != NULL);
__atomic_store_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, entry, __ATOMIC_RELEASE);
// Finally make all released slots available for new acquisitions
__atomic_fetch_add(&ring_buffer->m_cons_tail, 1, __ATOMIC_RELEASE);
return 0;
}
int dequeue_ringbuf(RingBuffer *ring_buffer, void **entry)
{
// Step 1: acquire slots
unsigned int tail = __atomic_load_n(&ring_buffer->m_cons_head, __ATOMIC_RELAXED);
do
{
unsigned int head = __atomic_load_n(
&ring_buffer->m_cons_tail, __ATOMIC_ACQUIRE);
if (head == tail)
{
return 1;
}
} while (!__atomic_compare_exchange_n(&ring_buffer->m_cons_head,
&tail, // Updated on failure
tail + 1,
/*weak=*/true,
__ATOMIC_RELAXED,
__ATOMIC_RELAXED));
// Step 2: Write slots (write NIL for dequeue)
int deq_ptr = (tail % ring_buffer->m_size) * 8;
unsigned int entry_sn;
void *entry_ptr;
do
{
entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, __ATOMIC_ACQUIRE);
} while (entry_ptr == NULL);
*entry = entry_ptr;
__atomic_store_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, 0, __ATOMIC_RELAXED);
// Finally make all released slots available for new acquisitions
__atomic_fetch_add(&ring_buffer->m_prod_head, 1, __ATOMIC_RELEASE);
return 0;
}
代码 8 非阻塞无锁 Ringbuffer 的实现
非阻塞的无锁 ringbuffer 实现的完整源码请参见(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/buck_blkring.h)。
非阻塞 Ringbuffer 性能测试结果
非阻塞的无锁 Ringbuffer 的性能如图 13 所示。曲线 mutex 表示基于 mutex 的 Ringbuffer 实现;lockfree 和 atomic 表示无锁 Ringbuffer 实现(lockfree 使用普通 load/store 操作数据单元;atomic 使用原子 load/store 操作数据单元);align 表示缓存行对齐后的无锁 Ringbuffer 实现;buck 表示的非阻塞无锁 Ringbuffer 实现。
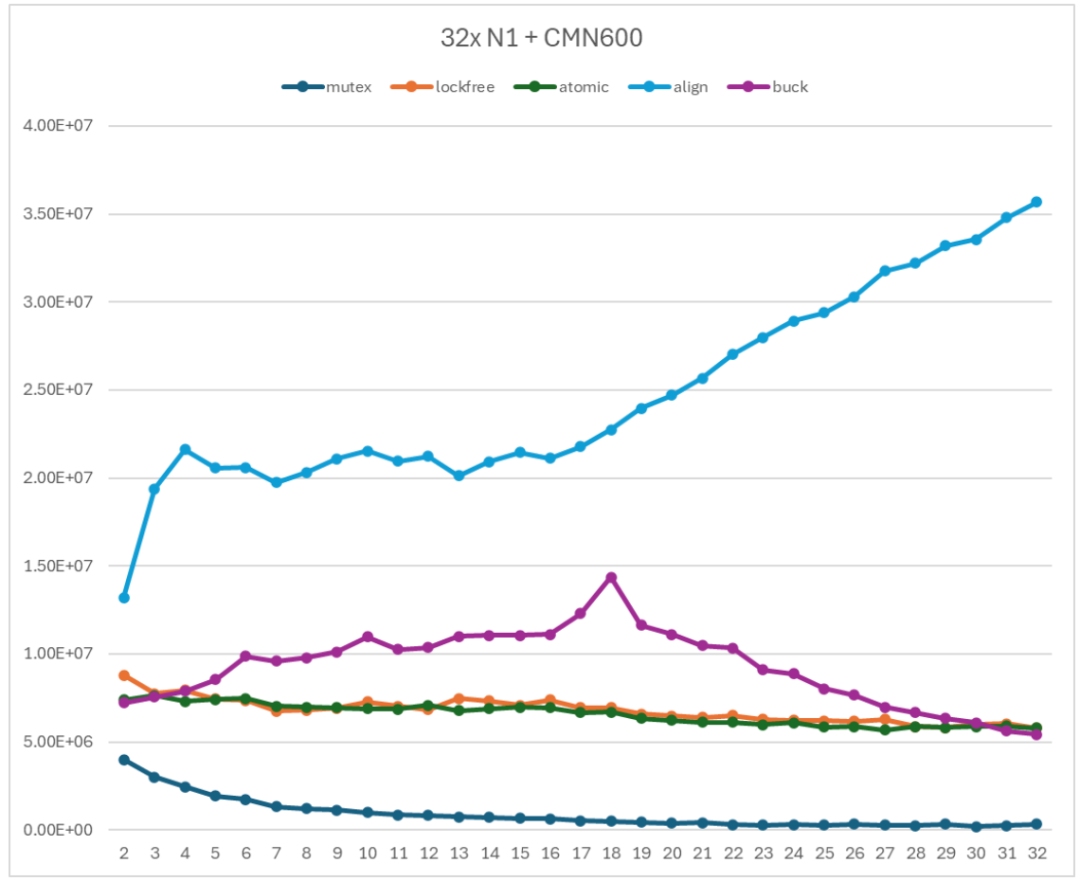
图 20 非阻塞无锁 Ringbuffer 性能测试
非阻塞的无锁 Ringbuffer 的性能曲线呈现两段趋势:
从 2 个线程到 16 个线程左右,吞吐率随着线程数增加而缓慢增加。
从 16 个线程左右到 32 个线程,吞吐率随着线程数增加而缓慢降低。
与基于 mutex 的 Ringbuffer 相比,非阻塞 Ringbuffer 的性能要远好于基于 mutex 的 Ringbuffer 的性能,并且在使用 16-20 个线程时达到最高。
另一方面,与缓存行对齐的无锁 Ringbuffer 实现相比,非阻塞 Ringbuffer 的性能差强人意。这是因为非阻塞的 Ringbuffer 引入了更多的指针竞争。阻塞的无锁 Ringbuffer 实现的 Enqueue 和 Dequeue 中只关注一个共享指针。但是非阻塞 Ringbuffer 实现的 Enqueue 和 Dequeue 则需要关注三个共享指针。这就导致出现了更多的共享变量的竞争,从而引起了性能下降。
取 2 个线程、16 个线程和 32 个线程三个位置进行定量比较,得到下表。表中第一行是吞吐率数据(单元 ops/s),第二行是相对于基准(基于 mutex 的 Ringbuffer 实现)的加速比。
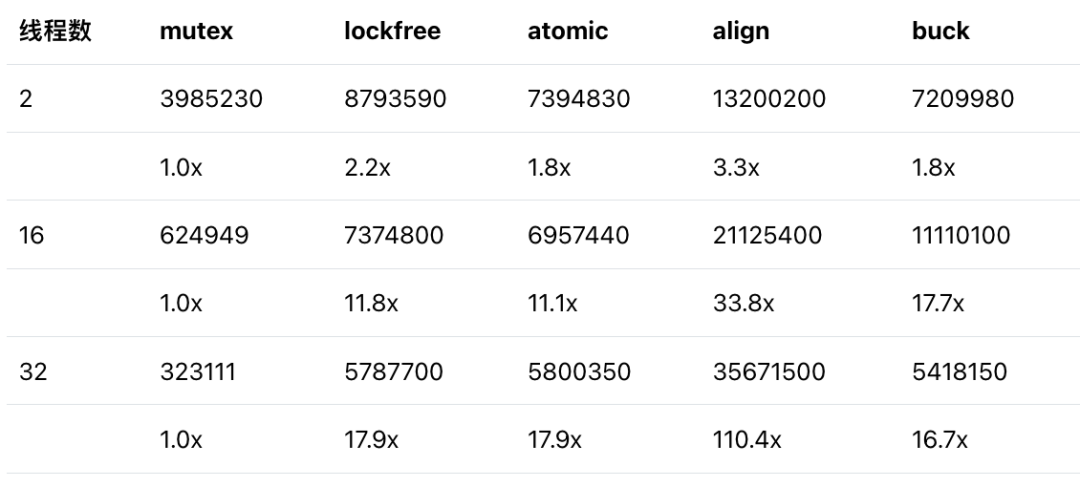
相对于基于 mutex 的 Ringbuffer,非阻塞的无锁 Ringbuffer 可以取得超过 10 倍的吞吐率提升。这表示非阻塞的无锁 Ringbuffer 实现仍然是非常有效的,值得在实际应用中尝试。
与 program64 的性能比较
在文系列完整的开篇处已经声明,本系列文章介绍的所有优化来自于 Ola 的研究。Ola 开发的 program64 库也是示例的 Ringbuffer 实现的基础。
无锁 Ringbuffer 实现对应于 program64 库中的 p64_blkring 实现。
非阻塞 Ringbuffer 实现对应于 program64 库中的 p64_buckring 实现。
这里将 program64 库的实现集成到我们的测试程序中,使用相同的测试环境和配置进行了测试。align 和 p64_blkring 是一个对照组;buck 和 p64_buckring 是一个对照组。
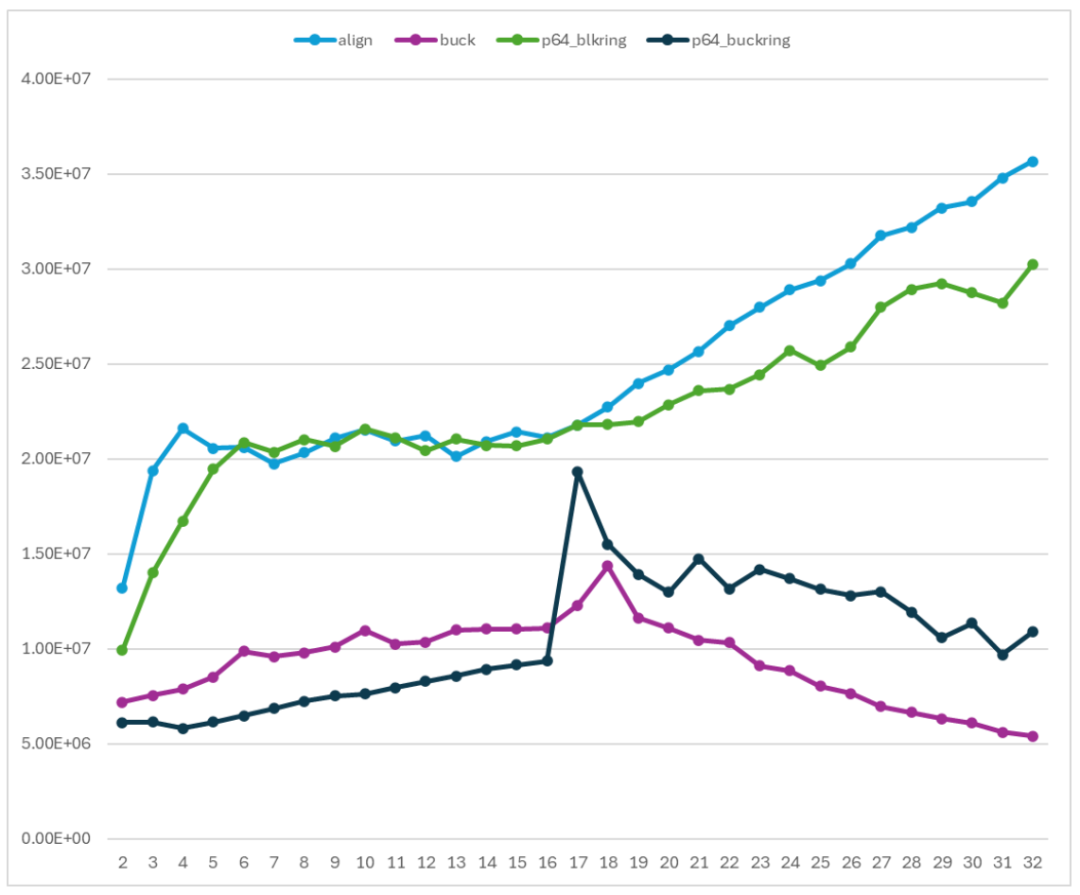
图 21 在 Arm 平台上与 Program64 库对比性能
我们的示例代码的性能与 program64 的性能在趋势上是一致,并且在数值范围上基本重合。两者之间的差距则是由于实现的细节引入的。比如 program64 的 Enqueue 和 Dequeue 可以操作多个单元,而示例代码只能操作一个单元。这些差距并不影响关于 Ringbuffer 优化的结论。
结论
本文介绍了多种 Ringbuffer 实现,并且比较和分析了不同 Ringbuffer 实现的性能表现:
基于 mutex 的 Ringbuffer 性能主要受到多线程相互竞争 mutex 的影响。参与竞争的线程越多,Ringbuffer 的吞吐率越低,非常不利于系统规模的扩展。
阻塞式的无锁 Ringbuffer 能够从原子操作和缓存行对齐两个优化中获得非常明显的收益,使得实现能够充分利用系统中互联系统提供的通信容量,是一种非常有利于系统规模扩展的 Ringbuffer 实现。
非阻塞 Ringbuffer 实现丰富并完善了 Ringbuffer 的功能,并且同样可以取得很好的性能优化。但是由于引入了更多的共享变量,非阻塞 Ringbuffer 实现的性能要弱于缓存行对齐的无锁 Ringbuffer 实现。
-
ARM
+关注
关注
134文章
9236浏览量
371779 -
服务器
+关注
关注
12文章
9491浏览量
86646 -
软件
+关注
关注
69文章
5071浏览量
88542 -
数组
+关注
关注
1文章
419浏览量
26160
原文标题:在 Arm 平台上实现性能可扩展的 Ringbuffer
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
C/C++性能优化背后的方法论:TMAM
【独风科创】RingBuffer开源C语言组件发布啦
HBase性能优化方法总结
Linux和Android系统故障和优化性能的方法和流程探讨
差动放大器的性能优化方法
AN0004—AT32 性能优化
求助大神,rt_ringbuffer_peak疑问求解
《现代CPU性能分析与优化》---精简的优化书

ringbuffer数据结构介绍





 工商网监
工商网监
评论