 3D网格重建学习:单一角度预测物体3D结构的框架
3D网格重建学习:单一角度预测物体3D结构的框架
看到一张图片,我们很容易就能猜测出图中物体的立体模样,但是机器能做到吗?美国加州大学伯克利分校的研究人员就开发了一个框架,让机器通过一张图片就能还原出立体原型,并添加自然的纹理图案。以下是论智对原论文的编译,后附论文地址和实验结果展示视频。
我们开发了一种学习框架,能够通过一张图片还原图中物体的3D形状、摄像角度及纹理。形状用可变形的3D网格模型表示。
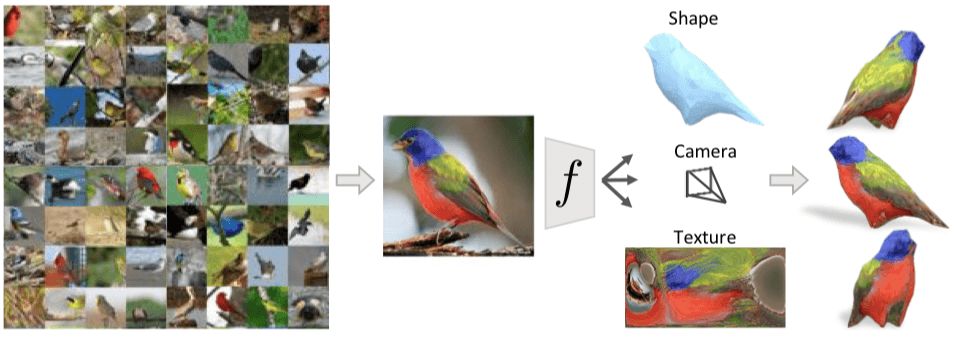
上图中有许多小鸟,即使我们是第一次看到这种图片上二维的鸟类,我们依然能推断出它大概的3D形状、了解拍摄的角度、甚至能猜出从另一个角度看它会是什么样。我们能做到这些是因为之前我们见过的鸟类能让我们对陌生小鸟有个大致轮廓,这些知识帮助我们还原这些案例的3D结构。
在这篇文章中,我们展示了一个能根据单张图片推断3D表示的计算模型,如上图所示,学习过程只需要一张标注过的2D图像,其中包括目标对象的类别、前景掩码和语义重点标签。
我们的目标是生成一个预测器fθ(参数化设置为一个CNN),它可以从单张照片I中推断出目标物体的3D结构。在这个项目中我们希望将物体的形状用3D网格表示,这种表示比其他方法(比如probabilistic volumetric grids)有更多优点,例如可对纹理进行模拟、进行相应的推理、表面水平推理和可解释性。
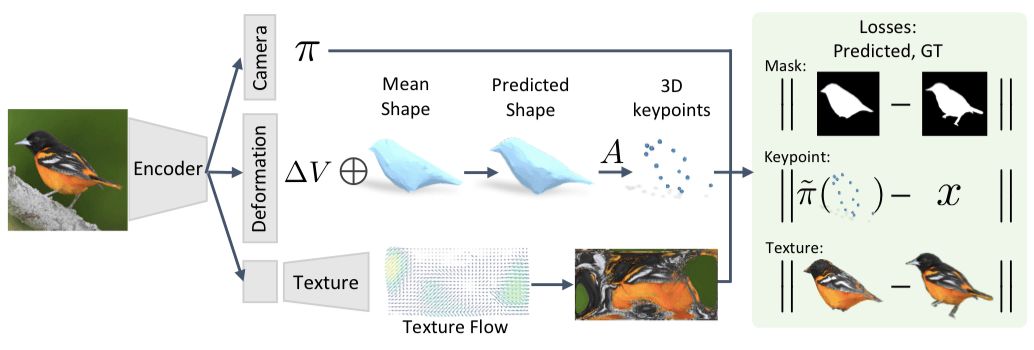
我们提出的框架如下图所示。输入的图像通过一个编码器后到达由三个模块组成的表征,它可以预测相机位置、物体形状和花纹的参数。
用模型推断目标物的3D表示
首先,给定一张图像I,我们预测fθ(I)≡(M, π),网格M和相机位置π用来捕捉对象的3D结构。具体的推导过程可查看原论文。除了这些直接预测的方面,我们还学习了网格和类别水平语义重点之间的关系。当我们在规范框架中使用特定类别的网格来表示形状时,跨实例的规律能帮助我们找到语义一致的定点位置,从而隐含地赋予这些顶点语义。
经过这一步,我们就利用一张图片I推断出了相应的相机位置π和形状∆V。同时,我们还通过学习实例独立的参数。推断出了网格定点的位置V和语义重点A·V。
从图像集合中学习
为了训练fθ,我们提出了一种不依赖于实际3D形状和多角度图像实例的监督的方法,而是从带有稀疏关键点和分割掩码的图像集中进行学习。这种设置更加自然,并且容易获得,特别是对会动和可变形的物体,例如鸟类或其他动物。想要获取对象的扫描件甚至同一物体多个角度的照片是非常困难的,但对于大多数物体来说,获取单张图像相对更容易。
有了带注释的图像集,我们通过制定一个目标函数来训练fθ,该函数包含和实例相关的损失和先验。具体的实例能量术语(energy terms)可以保证预测的3D结构与现有的掩码和关键点一致,并且先验知识能帮助生成一些特征,例如光滑性。由于我们从许多实例中得到了通用的预测模型fθ,那么各个种类之间的通用结构也能让我们从中得到有意义的3D预测,即使只有一个实例。
插入图案预测
在我们的公式中,所有复原的形状都有着共同的3D网格结构——每种形状都是平均形状的变形。我们可以利用这一属性来减少特定实例中的图案以预测平均图案的形状。我们的平均形状是个球体,它的表面图案可以表示成一张名为Iuv的图像,其值通过固定的UV映射映射到表面上(类似于将地球展开成平面图)。
于是,我们将预测图案的这个任务看作是推断Iuv的像素值。该图像可以被认为是属于目标物体类别的典型外观空间。例如,预测形状中的特殊三角形总是会映射到Iuv中的特定区域,不管它如何变形。
将图案参数化之后,UV图像中每个像素的语义含义都一致,从而使预测模型更容易利用通用模式,例如鸟背和身体之间的相关性。
我们通过设置一个解码器,将图案预测模块添加到框架中,该解码器可以将潜在表示转换成Iuv的空间向量。虽然直接用回归计算Iuv的像素值是一种可行的方法,但这通常会导致模糊图像的产生。相反,我们将此任务看成预测外观流,我们不回归Iuv像素的值,而是让模块输出从原始输入图像复制来的像素颜色。如图所示:
实验过程
模型设置好后,我们选择CUB-200-2011数据集做实验,该数据集有6000张训练和测试图像,包括了200种鸟类。每张图片都有边界框进行标注,另外还有14个语义关键点标注出了位置,同时还显示出了前景的掩码。我们从中挑选了近300张图像,其中每张图的关键点少于或等于6个。另外预测网络的各个模块示意图如图2所示,编码器由一个在ImageNet上预训练的ResNet-18组成,紧接着是一个卷积层。
最终在CUB测试集上得到的重建结果如图所示:
论文附录和文后视频中会有360度全景展示。
另外,我们还对目标物体的图案进行了替换,将一张图上的纹理替换到预测形状上去。我们发现,即使两个视角可能不同,由于基础的纹理图像在空间上是一致的,所转换的纹理在语义上也是一致的。
除此之外,我们还在PASCAL 3D+数据集上对车和飞机做了同样的实验,预测的形状通常都很正常,不过图案会出现较多错误,因为汽车上有反光的地方或是训练数据较少:
结语
我们展示了可以从单一角度预测物体3D结构的框架。虽然这项结果非常令人兴奋,但是我们并没有提出一个通用的解决方案。最后,虽然我们只能使用实例的单一视图进行学习,但对于有多个视图的场景来说,我们的方法可能同样适用,并产生更好的结果。
-
编码器
+关注
关注
45文章
3648浏览量
134731 -
3D
+关注
关注
9文章
2892浏览量
107640
原文标题:让平面变立体——特定类别3D网格重建学习
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
3D扫描的结构光
3D打印的优势
PYNQ框架下如何快速完成3D数据重建
浩辰3D的「3D打印」你会用吗?3D打印教程
使用结构光的3D扫描介绍
从荣耀角度解读3D识别的结构光、TOF及双目立体成像方案
浅析3D结构光技术

3D视觉主要技术路径 3D结构光技术原理
大规模3D重建的Power Bundle Adjustment
基于未知物体进行6D追踪和3D重建的方法

生成高质量 3D 网格,从重建到生成式 AI






 工商网监
工商网监
评论