 基于深度学习的图像块型超分辨重建的经典论文进行关键技术点分析
基于深度学习的图像块型超分辨重建的经典论文进行关键技术点分析
分辨率极限,无论对于图像重建或是图像后处理算法的研究者,都是一项无法回避的技术指标。在实际的应用场景中,受限于图像采集设备成本、视频图像传输带宽,抑或是成像模态本身的技术瓶颈,我们并不是每一次都有条件获得边缘锐化,无块状模糊的大尺寸高清图像。在这种需求背景下,超分辨重建技术应运而生。
图1:图片压缩与传输
应用场景I:图片压缩与传输,即以较低的码率进行图像编码,在传输过程中可极大节省转发服务器的流量带宽,在客户端解码得到相对低清晰度的图片,最后通过超分辨重建技术处理获得高清晰度图片
图2:生物组织成像
应用场景II:生物组织成像 左图:光声显微成像图像 右图:光声超分辨显微图像,细微的蜜蜂翅膀纹理清晰可见
传统超分辨重建技术大体上可分为4类,分别是预测型(prediction-based), 边缘型(edge-based), 统计型(statistical)和图像块型(patch-based/example-based)的超分辨重建方法。
我们选择了4篇基于深度学习的图像块型超分辨重建的经典论文进行关键技术点分析,从中我们可以看出研究者们对于超分辨任务的不同的理解与解决问题思路。在2012年AlexNet以15.4%的历史性超低的分类错误率获得ImageNet大规模视觉识别挑战赛年度冠军,吹响了深度学习在计算机视觉领域爆炸发展的号角之后。超分辨重建技术也开始采用深度学习的思想,以期获得更优的算法表现。
SRCNN
SRCNN是基于深度学习的超分辨重建领域的开山之作,继承了传统机器学习领域稀疏编码的思想,利用三层卷积层分别实现:
图像的图像块抽取与稀疏字典建立
图像高、低分辨率特征之间的非线性映射
高分辨率图像块的重建
具体地,假设需要处理的低分辨率图片的尺寸为H × W × C, 其中H、W、C分别表示图片的长、宽和通道数;SRCNN第一层卷积核尺寸为C × f1 × f1 × n1,可以理解为在低分辨率图片上滑窗式地提取f1 × f1的图像块区域进行n1种类型的卷积操作。在全图范围内,每一种类型卷积操作都可以输出一个特征向量,最终n1个特征向量构成了低分辨率图片的稀疏表示的字典,字典的维度为H1 × W1 × n1;SRCNN第二层卷积核尺寸为n1 × 1 × 1 × n2,以建立由低分辨率到高分辨率稀疏表示字典之间的非线性映射,输出的高分辨率稀疏字典的维度为H1 × W1 × n2,值得注意的是在这一步中SRCNN并未采用全连接层(fully connected layer)来进行特征图或是稀疏字典之间的映射,而是采用1x1卷积核,从而使得空间上每一个像素点位置的映射都共享参数,即每一个空间位置以相同的方式进行非线性映射; SRCNN第三层卷积核尺寸为n2 × f3 × f3 × C,由高分辨率稀疏字典中每一个像素点位置的n2 × 1向量重建f3 × f3图像块,图像块之间相互重合覆盖,最终实现图片的超分辨率重建。
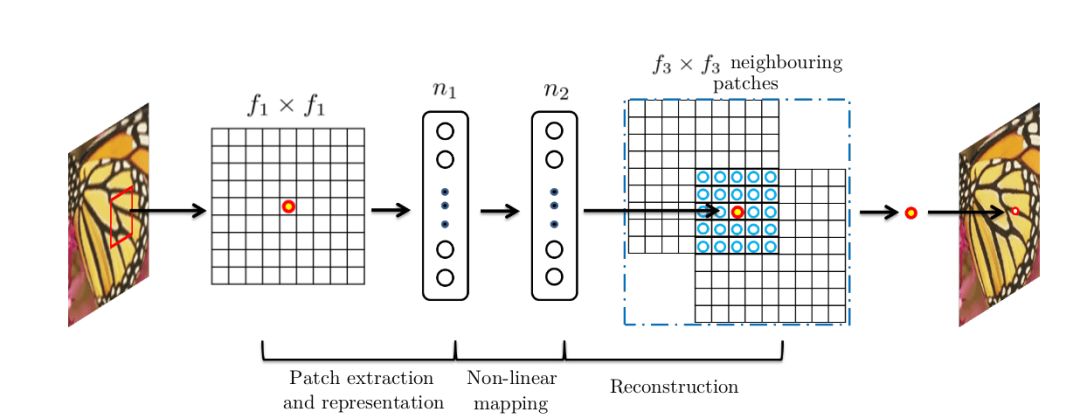
图3:SRCNN的三层卷积结构
ESPCN
在SRCNN将CNN引入超分辨率重建领域之后,研究者们开始考虑如何利用“卷积”来解决更深入的问题。
如果对一幅高分辨率图片做高斯平滑或是降采样可以等效为卷积操作,那么由降采样后低分辨率图片恢复高分辨率的过程则相应的等效为反卷积操作(deconvolution)。此时我们的计算任务是学习合适的解卷积核,从低分辨率图片中恢复高分辨率图像。
CNN中反卷积层的标准做法如图4所示,对一幅低分辨率图片填充零值(zero padding),即以每一个像素点位置为中心,周围2×2或3×3邻域填充0,再以一定尺寸的卷积核进行卷积操作。
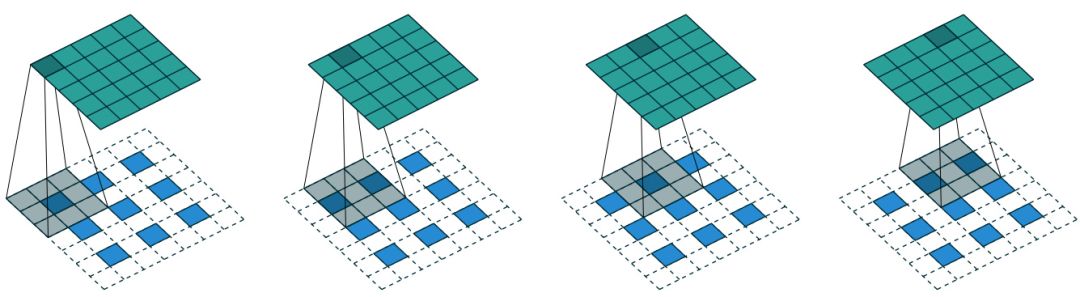
图4:标准反卷积层实现示意图
但是标准反卷积操作的弊端是显而易见的,首先,填充的零值并不包含任何图像相关的有效信息,其次填充后的图片卷积操作的计算复杂度有所增加。
在这种情况下,Twitter图片与视频压缩研究组将sub-pixel convolution的概念引入SRCNN中。
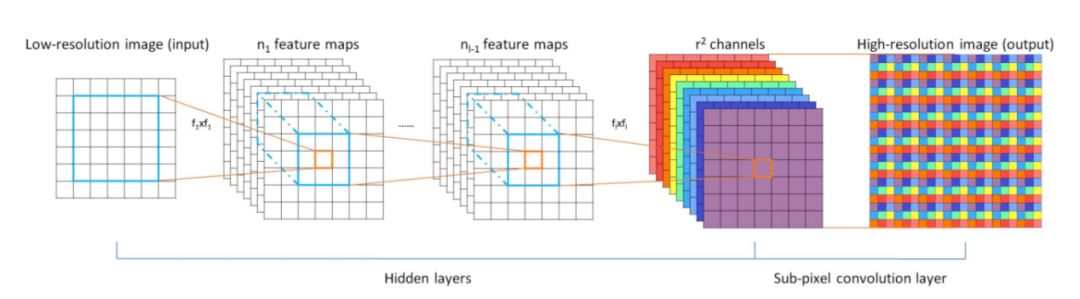
图5:Efficient Sub-Pixel Convolutional Neural Network (ESPCN)网络结构
Sub-Pixel核心思想在于对于任意维度为H × W × C的图像,标准反卷积操作输出的特征图维度为rH × rW × C,其中r为超分辨系数即图片尺寸放大的倍数,而sub-pixel的输出特征图维度为H × W × C × r2,即令特征图与输入图片的尺寸保持一致,但增加卷积核的通道数,既使得输入图片中邻域像素点的信息得到有效利用,还避免了填充0引入的计算复杂度增加。
Perceptual Loss
相较于其他机器学习任务,如物体检测(object detection)或者实例分割(instance segmentation),超分辨重建技术中学习任务的损失函数的定义通常都相对简单粗暴,由于我们重建的目的是为了使得重建的高分辨率图片与真实高清图片之间的峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)尽可能的大,因此绝大多数的基于深度学习的超分辨重建研究都直接的将损失函数设计为平均均方差(Mean Square Error, MSE),即计算两幅图片所有对应像素位置点之间的均方差,由于MSE Loss要求像素点之间位置一一对应,因此又被称作Per-Pixel Loss。
但随着技术的发展,研究者慢慢发现Per-Pixel Loss的局限性。考虑一个极端的情况,将高清原图向任意方向偏移一个像素,事实上图片本身的分辨率与风格并未发生太大的改变,但Per-Pixel Loss却会因为这一个像素的偏移而出现显著的上升,因此Per-Pixel Loss的约束并不能反应图像高级的特征信息(high-level features)。
因此研究图像风格迁移的研究者们相对于Per-Pixel Loss在2016年的CVPR会议上提出了Perceptual Loss的概念。
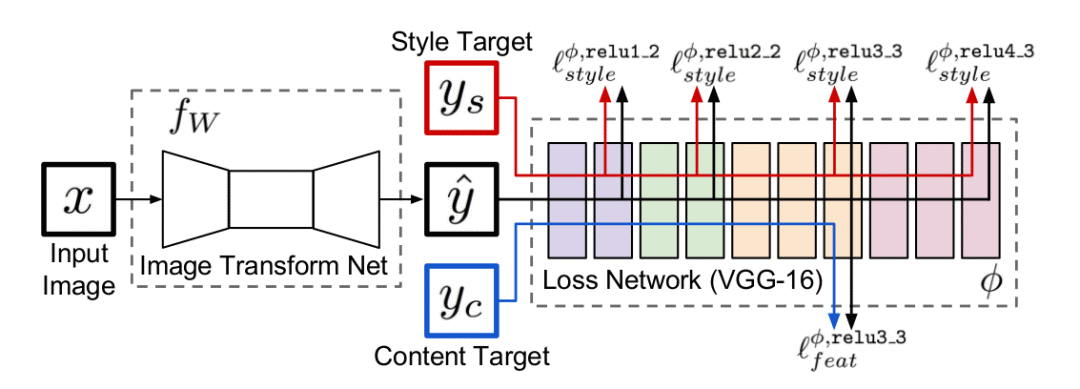
图6:基于Perceptual Loss的全卷积网络结构
基于Per-Pixel Loss的超分辨重建网络目标在于直接最小化高清原图与超分辨重建图像之间的差异,使得超分辨重建图像逐步逼近原图的清晰效果。但Perceptual Loss最小化的是原图与重建图像的特征图之间的差异,为了提高计算效率,Perceptual Loss中的特征图由固定权重值的卷积神经网络提取,例如在ImageNet数据集上预训练得到的VGG16网络,如图7所示,不同深度的卷积层提取的特征信息不同,反映的图像的纹理也不同。

图7:不同深度的卷积层提取的图片特征示意图
因此研究者们在训练超分辨神经网络时,利用跨间隔的卷积层(strided convolution layer)代替池化层(pooling layer)构建全卷积神经网络(Fully Convolutional Network, FCN)进行超分辨重建,并在卷积层之间添加残差结构(residual block)以在保证网络拟合性能的前提下加深网络深度获得更佳表现。最终利用VGG16网络对原图与重建图像进行特征提取,最小化两者特征图之间的差异使得超分辨重建图像不断逼近原图的分辨率。
RAISR
前面提到的几种典型的图像块型(也被称作样例型)超分辨技术,都是在高低分辨率图像块一一对应的数据基础上,学习由低分辨率到高分辨率图像块的映射。具体的来说,通常这种映射是一系列的滤波器,针对输入图片不同像素位置点的不同的纹理特征来选择适当的滤波器进行超分辨重建。基于这种思想,Google于2016年在SRCNN,A+以及ESPCN等超分辨研究的基础上发布了RAISR算法。
该算法主打高速的实时性能与极低的计算复杂度,核心思想在于利用配对的高低分辨率图像块训练得到一系列的滤波器,在测试时根据输入图片的局部梯度统计学特性索引选择合适的滤波器完成超分辨重建。因此RAISR算法由两部分组成,第一部分是训练高低分辨率映射(LR/HR mapping)的滤波器,第二部分是建立滤波器索引机制(hashing mechanism)。
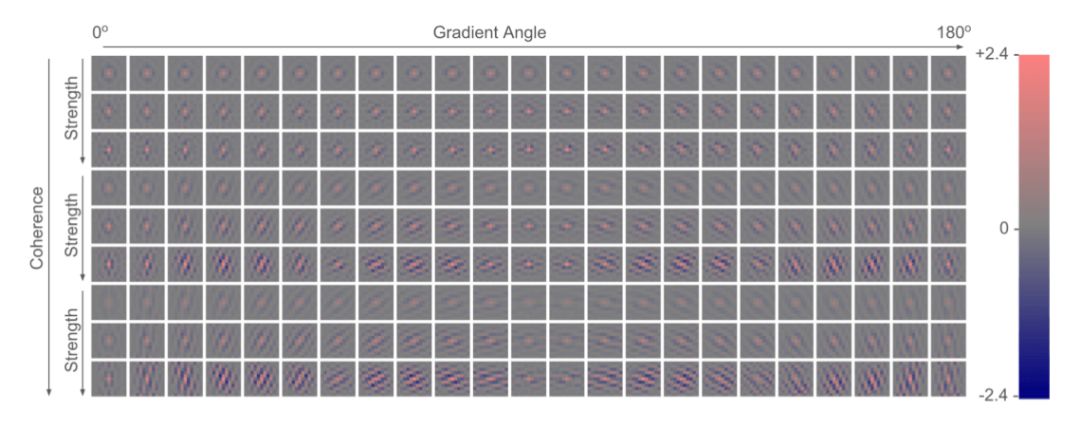
图8:RAISR 2倍上采样滤波器
下图为RAISR在2x上采样率时与SRCNN,A+等超分辨算法的技术指标对比。左为PSNR-runtime指标,右图为SSIM-runtime指标。
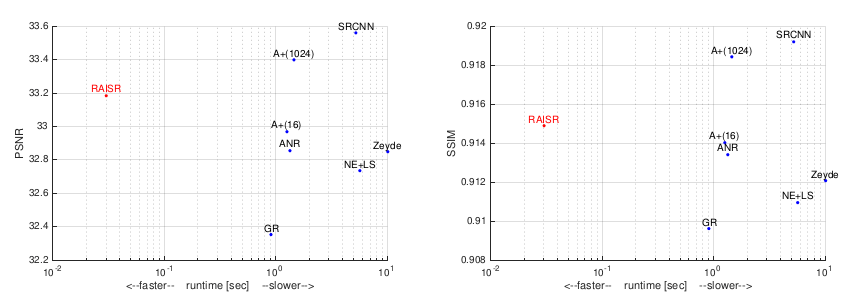
图9:RAISR在2x上采样率时与SRCNN,A+等超分辨算法的技术指标对比
结语
超分辨率重建在医学影像处理、压缩图像增强等方面具有广阔的应用前景,近年来一直是深度学习社区研究的热点领域。卷积和残差构件的改进、不同种类Perceptual Loss的进一步分析、对抗生成网络用于超分辨率重建的探索等都是值得关注的方向。相信我们很快就能看到深度学习在超分辨率重建领域的更多重大进展。
-
神经网络
+关注
关注
42文章
4785浏览量
101284 -
机器学习
+关注
关注
66文章
8455浏览量
133184
原文标题:一文概览基于深度学习的超分辨率重建架构
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

结合压缩感知与非局部信息的图像超分辨率重建
序列图像超分辨率重建
基于结构自相似性和形变块特征的单幅图像超分辨率算法
基于复合的深度神经网络的图像超分辨率重建





 工商网监
工商网监
评论