 Linux内核的连续内存分配器(CMA)——避免预留大块内存
Linux内核的连续内存分配器(CMA)——避免预留大块内存
这是我2012年上半年写的文章,现在微信公众号再次发表。
在我们使用ARM等嵌入式Linux系统的时候,一个头疼的问题是GPU,Camera,HDMI等都需要预留大量连续内存,这部分内存平时不用, 但是一般的做法又必须先预留着。目前,Marek Szyprowski和Michal Nazarewicz实现了一套全新的Contiguous Memory Allocator。通过这套机制,我们可以做到不预留内存,这些内存平时是可用的,只有当需要的时候才被分配给Camera,HDMI等设备。下面分析 它的基本代码流程。
声明连续内存
内核启动过程中arch/arm/mm/init.c中的arm_memblock_init()会调用dma_contiguous_reserve(min(arm_dma_limit, arm_lowmem_limit));
该函数位于:drivers/base/dma-contiguous.c
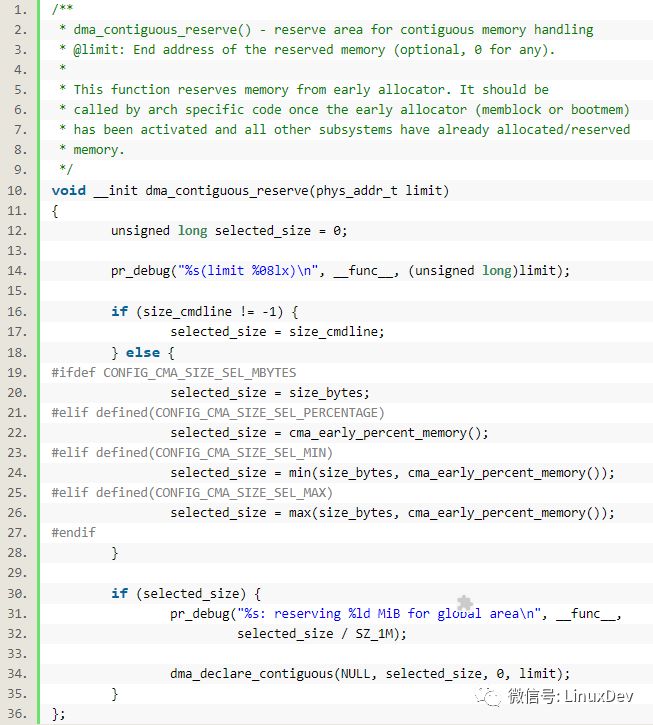
其中的size_bytes定义为:
static const unsigned long size_bytes = CMA_SIZE_MBYTES * SZ_1M; 默认情况下,CMA_SIZE_MBYTES会被定义为16MB,来源于CONFIG_CMA_SIZE_MBYTES=16->
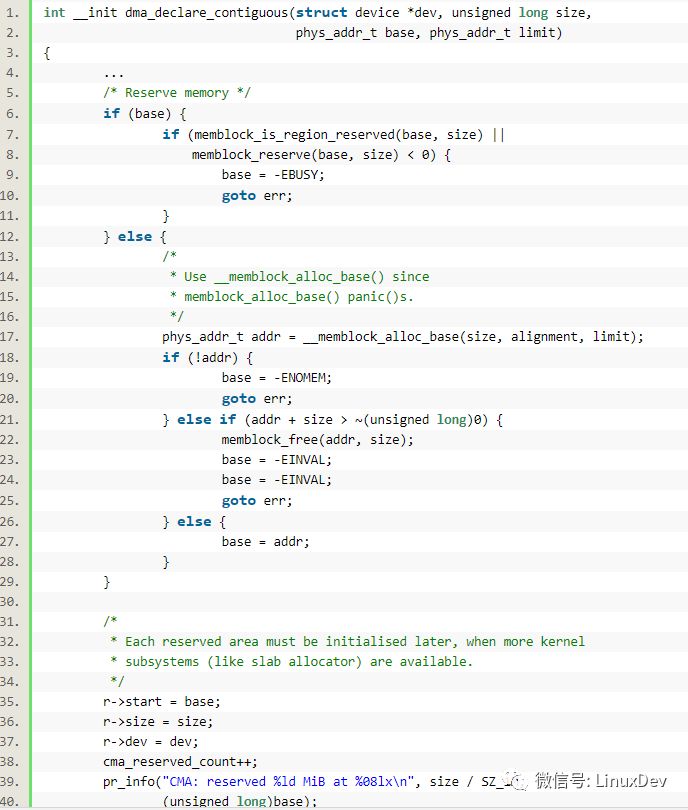
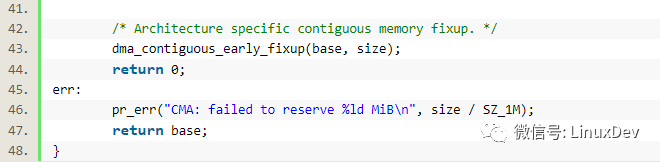
由此可见,连续内存区域也是在内核启动的早期,通过__memblock_alloc_base()拿到的。
另外:
drivers/base/dma-contiguous.c里面的core_initcall()会导致cma_init_reserved_areas()被调用:
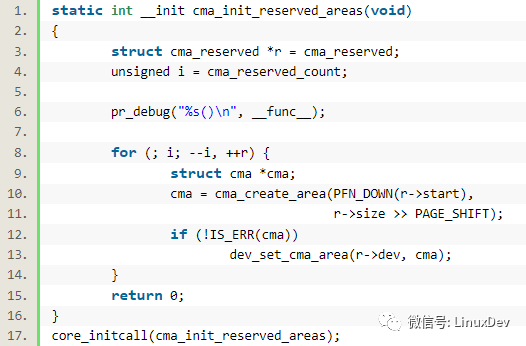
cma_create_area()会调用cma_activate_area(),cma_activate_area()函数则会针对每个page调用:
init_cma_reserved_pageblock(pfn_to_page(base_pfn));
这个函数则会通过set_pageblock_migratetype(page, MIGRATE_CMA)将页设置为MIGRATE_CMA类型的:
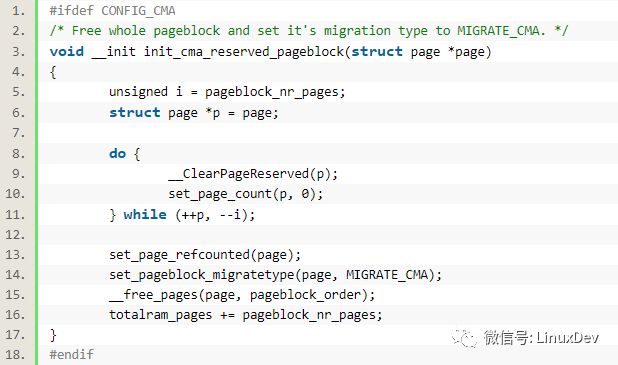
同时其中调用的__free_pages(page, pageblock_order);最终会调用到__free_one_page(page, zone, order, migratetype);相关的page会被加到MIGRATE_CMA的free_list上面去:
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
申请连续内存
申请连续内存仍然使用标准的arch/arm/mm/dma-mapping.c中定义的dma_alloc_coherent()和dma_alloc_writecombine(),这二者会间接调用drivers/base/dma-contiguous.c中的

->
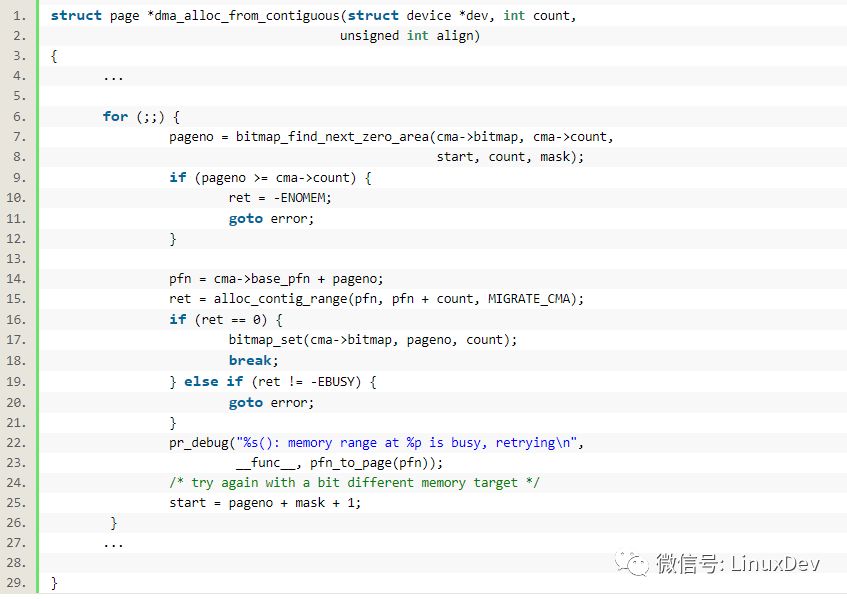
->
int alloc_contig_range(unsigned long start, unsigned long end,
unsigned migratetype)
需要隔离page,隔离page的作用通过代码的注释可以体现:
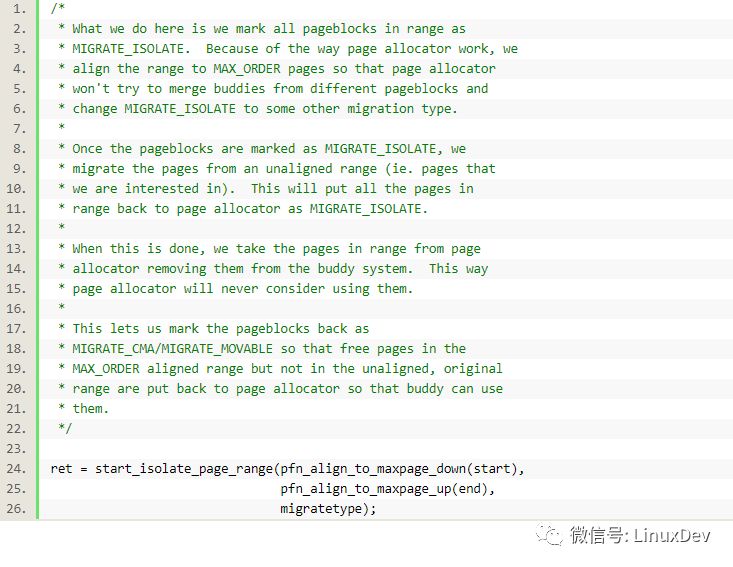
简单地说,就是把相关的page标记为MIGRATE_ISOLATE,这样buddy系统就不会再使用他们。

接下来调用__alloc_contig_migrate_range()进行页面隔离和迁移:

其中的函数migrate_pages()会完成页面的迁移,迁移过程中通过传入的__alloc_contig_migrate_alloc()申请新的page,并将老的page付给新的page:
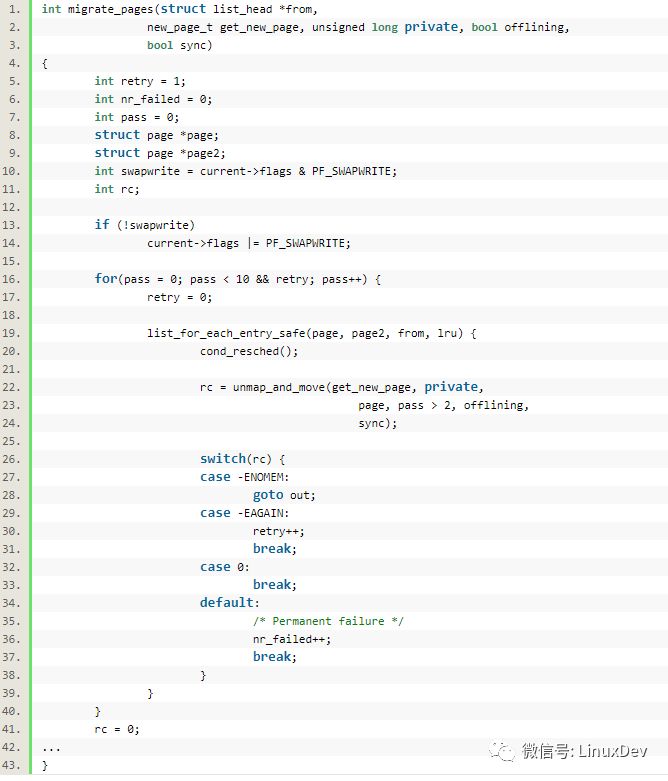
其中的unmap_and_move()函数较为关键,它定义在mm/migrate.c中
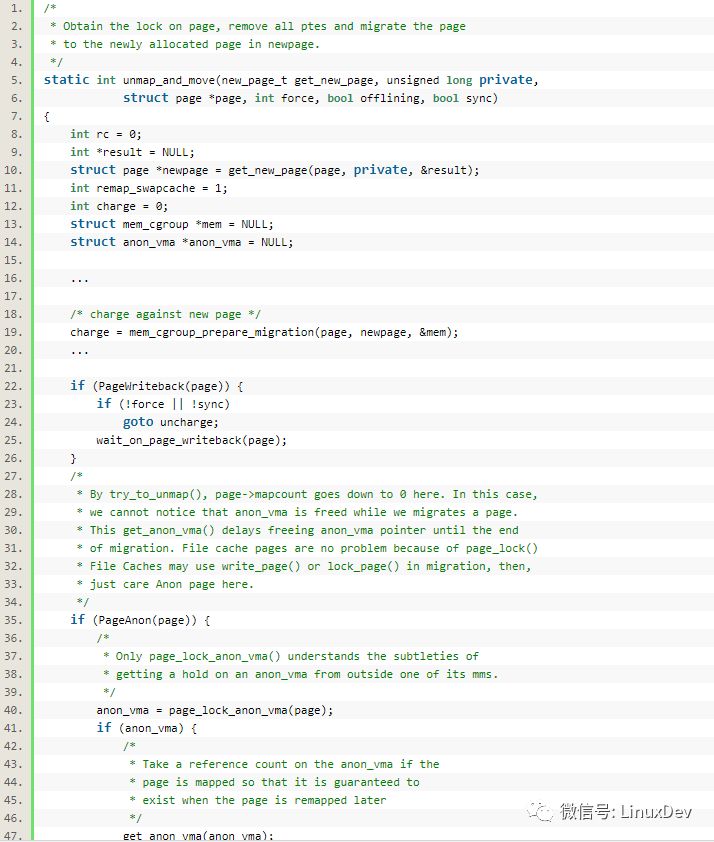
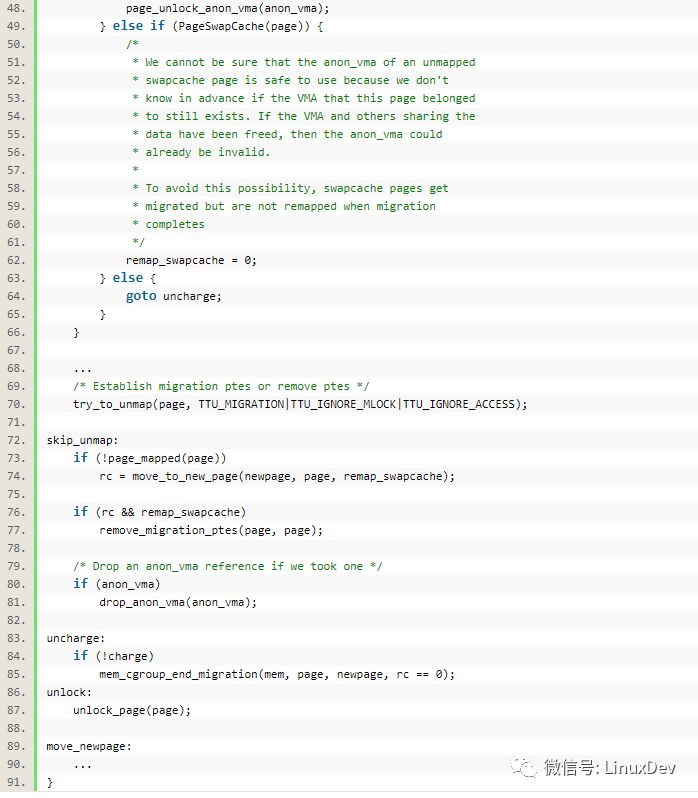
通过unmap_and_move(),老的page就被迁移过去新的page。
接下来要回收page,回收page的作用是,不至于因为拿了连续的内存后,系统变得内存饥饿:
->

->
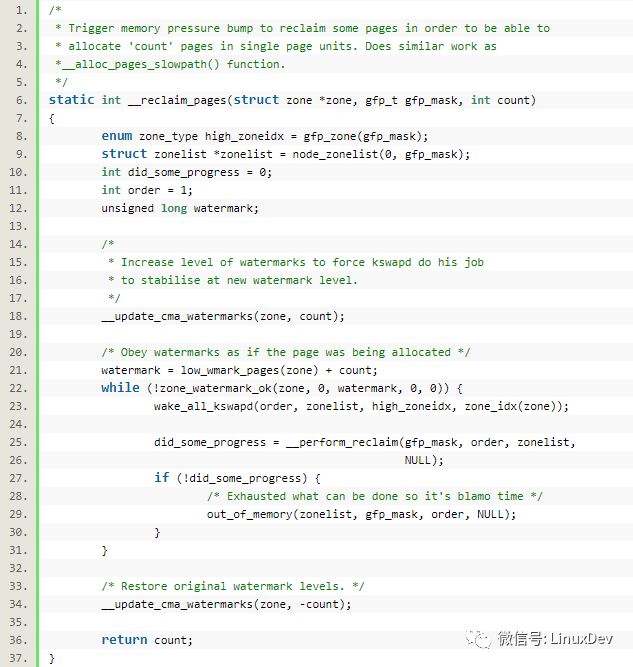
释放连续内存
内存释放的时候也比较简单,直接就是:
arch/arm/mm/dma-mapping.c:
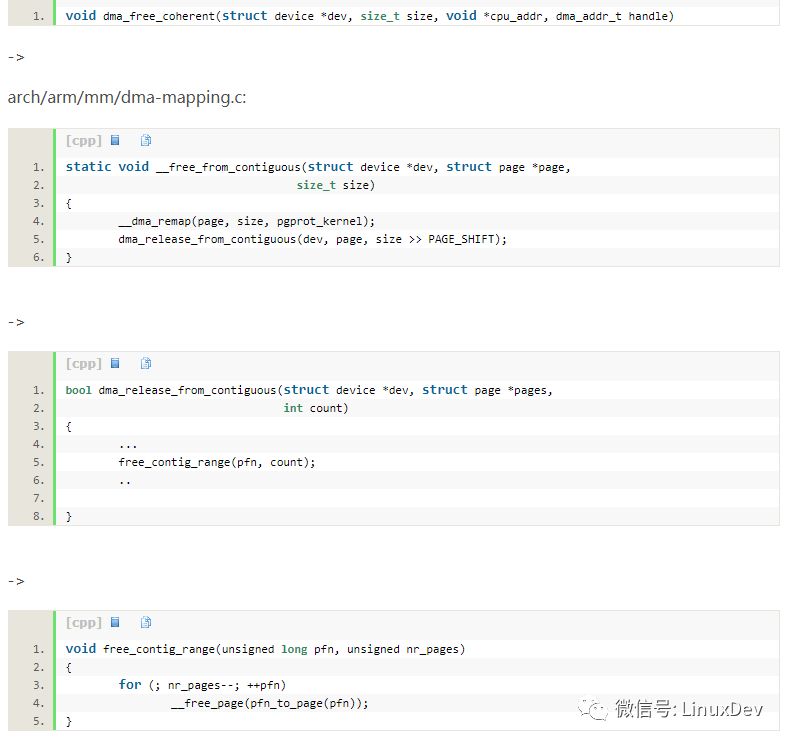
将page交还给buddy。
内核内存分配的migratetype
内核内存分配的时候,带的标志是GFP_,但是GFP_可以转化为migratetype:
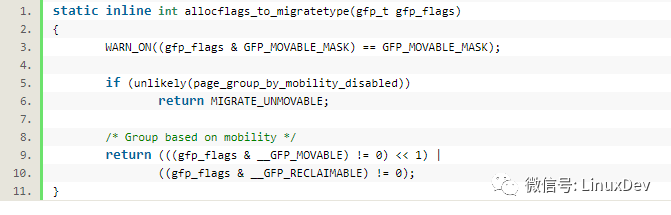
之后申请内存的时候,会对比迁移类型匹配的free_list:

另外,笔者也编写了一个测试程序,透过它随时测试CMA的功能:
/*
* kernel module helper for testing CMA
*
* Licensed under GPLv2 or later.
*/
#include
#include
#include
#include
#include
#define CMA_NUM 10
static struct device *cma_dev;
static dma_addr_t dma_phys[CMA_NUM];
static void *dma_virt[CMA_NUM];
/* any read request will free coherent memory, eg.
* cat /dev/cma_test
*/
static ssize_t
cma_test_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int i;
for (i = 0; i < CMA_NUM; i++) {
if (dma_virt[i]) {
dma_free_coherent(cma_dev, (i + 1) * SZ_1M, dma_virt[i], dma_phys[i]);
_dev_info(cma_dev, "free virt: %p phys: %p\n", dma_virt[i], (void *)dma_phys[i]);
dma_virt[i] = NULL;
break;
}
}
return 0;
}
/*
* any write request will alloc coherent memory, eg.
* echo 0 > /dev/cma_test
*/
static ssize_t
cma_test_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
int i;
int ret;
for (i = 0; i < CMA_NUM; i++) {
if (!dma_virt[i]) {
dma_virt[i] = dma_alloc_coherent(cma_dev, (i + 1) * SZ_1M, &dma_phys[i], GFP_KERNEL);
if (dma_virt[i]) {
void *p;
/* touch every page in the allocated memory */
for (p = dma_virt[i]; p < dma_virt[i] + (i + 1) * SZ_1M; p += PAGE_SIZE)
*(u32 *)p = 0;
_dev_info(cma_dev, "alloc virt: %p phys: %p\n", dma_virt[i], (void *)dma_phys[i]);
} else {
dev_err(cma_dev, "no mem in CMA area\n");
ret = -ENOMEM;
}
break;
}
}
return count;
}
static const struct file_operations cma_test_fops = {
.owner = THIS_MODULE,
.read = cma_test_read,
.write = cma_test_write,
};
static struct miscdevice cma_test_misc = {
.name = "cma_test",
.fops = &cma_test_fops,
};
static int __init cma_test_init(void)
{
int ret = 0;
ret = misc_register(&cma_test_misc);
if (unlikely(ret)) {
pr_err("failed to register cma test misc device!\n");
return ret;
}
cma_dev = cma_test_misc.this_device;
cma_dev->coherent_dma_mask = ~0;
_dev_info(cma_dev, "registered.\n");
return ret;
}
module_init(cma_test_init);
static void __exit cma_test_exit(void)
{
misc_deregister(&cma_test_misc);
}
module_exit(cma_test_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Barry Song <21cnbao@gmail.com>");
MODULE_DESCRIPTION("kernel module to help the test of CMA");
MODULE_ALIAS("CMA test");
申请内存:
#echo0>/dev/cma_test
释放内存:
#cat/dev/cma_test
-
Linux
+关注
关注
87文章
11357浏览量
210827 -
分配器
+关注
关注
0文章
195浏览量
25865
原文标题:宋宝华:Linux内核的连续内存分配器(CMA)——避免预留大块内存
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Linux内核内存规整总结

Linux内核内存管理之内核非连续物理内存分配
Linux内存系统: Linux 内存分配算法
深入剖析SLUB分配器和SLAB分配器的区别






 工商网监
工商网监
评论