 从FPN到Mask R-CNN,Facebook的计算机视觉有多强
从FPN到Mask R-CNN,Facebook的计算机视觉有多强
▌Feature Pyramid Networks( 特征金字塔网络)
首先,我们要介绍的是著名的特征金字塔网络(这是发表在 CVPR 2017 上的一篇论文,以下简称FPN)。
如果你在过去两年有一直跟进计算机视觉领域的最新进展的话,那你一定听说过这个网络的大名,并和其他人一样等待着作者开源这个项目。FPN 这篇论文提出的一种非常棒的思路。我们都知道,构建一个多任务、多子主题、多应用领域的基线模型是很困难的。
FPN 可以视为是一种扩展的通用特征提取网络(如 ResNet、DenseNet),你可以从深度学习模型库中选择你想要的预训练的 FPN 模型并直接使用它!
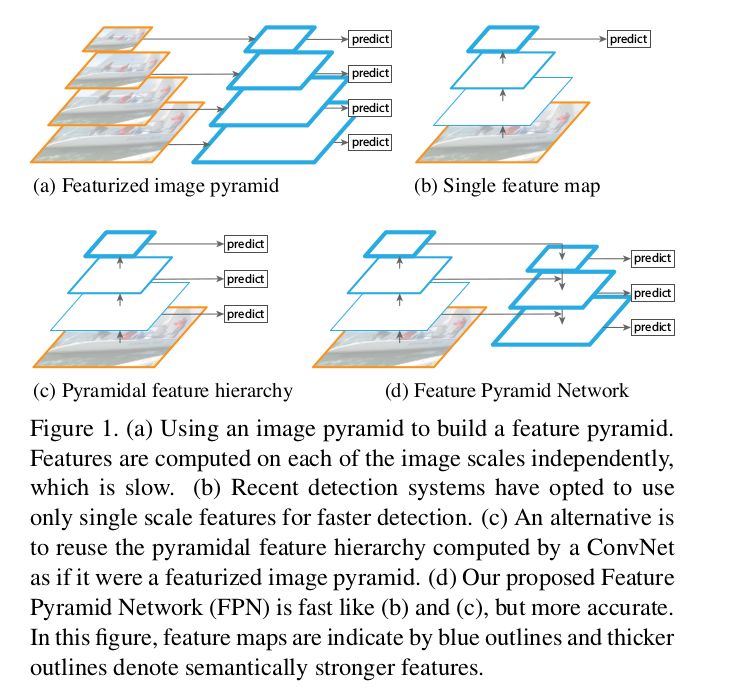
通常,图像目标有多个不同尺度和尺寸大小。一般的数据集无法捕捉所有的图像属性,因此人们使用图像金字塔的方式,对图像按多种分辨率进行降级,提取图像特征,以方便 CNN 处理。但是,这种方法最大弊端是网络处理的速度很慢,因此我们更喜欢使用单个图像尺度进行预测,也就导致大量图像特征的流失,如一部分研究者可能从特征空间的中间层获取预测结果。
换句话说,以 ResNet 为例,对于分类任务而言,在几个 ResNet 模块后放置一个反卷积层,在有辅助信息和辅助损失的情况下获取分割输出(可能是 1x1 卷积和 GlobalPool),这就是大部分现有模型架构的工作流程。
回到我们的主题,FPN 作者提出一种新颖的思想,能够有效改善现有的处理方式。他们不单单使用侧向连接,还使用自上而下的路径,并通过一个简单的 MergeLayer(mode=『addition』)将二者结合起来,这种方式对于特征的处理是非常有效!由于初始卷积层提取到的底层特征图(初始卷积层)的语义信息不够强,无法直接用于分类任务,而深层特征图的语义信息更强,FPN 正是利用了这一关键点从深层特征图中捕获到更强的语义信息。
此外,FPN 通过自上而下的连接路径获得图像的 Fmaps(特征图),从而能够到达网络的最深层。可以说,FPN 巧妙地将二者结合了起来,这种网络结构能够提取图像更深层的特征语义信息,从而避免了现有处理过程信息的流失。
其他一些实现细节
-
图像金字塔:认为同样大小的所有特征图属于同一个阶段。最后一层的输出是金字塔的 reference FMaps。如 ResNet 中的第 2、3、4、5 个模块的输出。你可以根据内存和特定使用情况来改变金字塔。
-
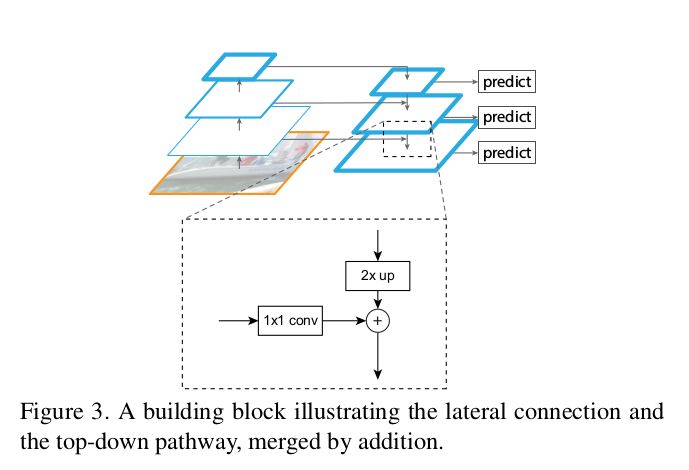
侧向连接:1x1 卷积和自上而下的路径都经过 2× 的上采样过程。上层的特征以自上而下的方式生成粗粒度的图像特征,而侧向连接则通过自下而上的路径来添加更多细粒度的特征信息。在此我引用了论文中的一些图片来帮助你进一步理解这一过程。
-
在 FPN 的论文中,作者还介绍了一个简单的 demo 来可视化这个想法的设计思路。
如前所述,FPN 是一个能够在多任务情景中使用的基线模型,适用于如目标检测、分割、姿态估计、人脸检测及其他计算机视觉应用领域。这篇论文的题目是 FPNs for Object Detection,自 2017 年发表以来引用量已超过 100 次!
此外,论文作者在随后的 RPN(区域建议网络)和 Faster-RCNN 网络研究中,仍使用 FPN 作为网络的基线模型,可见 FPN的强大之处。以下我将列出一些关键的实验细节,这些在论文中也都可以找到。
实验要点
-
RPN:这篇论文中,作者用 FPN 来代替单个尺度 Fmap,并在每一级使用单尺度 anchor (由于使用了 FPN,因此没必要使用多尺度的 anchor)。此外,作者还展示了所有层级的特征金字塔共享类似的语义信息。
-
Faster RCNN:这篇论文中,作者使用类似图像金字塔的输出方式处理这个特征金字塔,并使用以下公式将感兴趣域(RoI)分配到特定的层级中。
-
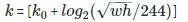 ,其中 w、h 分别表示宽度和高度,k 表示 RoI 所分配到的层级,k0 代表的是 w=224,h=224 时所映射到的层级。
,其中 w、h 分别表示宽度和高度,k 表示 RoI 所分配到的层级,k0 代表的是 w=224,h=224 时所映射到的层级。 -
Faster RCNN 在 COCO 数据集上取得当前最先进的实验结果,没有任何冗余的结构。
-
论文的作者对每个模块的功能进行了消融(ablation)研究,并论证了本文提出的想法。
-
此外,还基于 DeepMask 和 SharpMask 论文,作者进一步展示了如何使用 FPN 生成分割的建议区域(segmentation proposal generation)。
对于其他的实现细节、实验设置等内容,感兴趣的同学可以认真阅读下这篇论文。
实现代码
-
官方的Caffe2版本:
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
Caffe版本:https://github.com/unsky/FPN
-
PyTorch版本:https://github.com/kuangliu/pytorch-fpn (just the network)
-
MXNet版本:https://github.com/unsky/FPN-mxnet
-
Tensorflow版本:https://github.com/yangxue0827/FPN_Tensorflow
▌RetinaNet:Focal Loss 损失函数用于密集目标检测任务
这个架构是由同一个团队所开发,这篇论文[2]发表在 ICCV 2017 上,论文的一作也是 FPN 论文的一作。该论文中提出有两个关键想法:通用损失函数Focal Loss(FL)和单阶段的目标检测器RetinaNet。两者组合成的RetinaNet在COCO的目标检测任务中表现得非常好,并超过了先前FPN所保持的结果。
Focal Loss
Focal Loss损失函数的提出来源于一个聪明又简单的想法。如果你熟悉加权函数的话,那么你应该对Focal Loss并不陌生。该损失函数其实就是巧妙地使用了加权的损失函数,让模型训练过程更聚焦于分类难度高的样本。其数学公式如下所示:

其中,γ 是一个可改变的超参数,pt 表示分类器输出的样本概率。将 γ 设置为大于 0,将会减小分类结果较好的样本权重。α_t 表示标准加权损失函数中的类别权重,在论文中将其称为 α-balanced 损失。值得注意的是,这个是分类损失,RetinaNet 将其与 smooth L1 损失结合,用于目标检测任务。
RetinaNet
YOLO2 和 SSD 是当前处理目标场景最优的单阶段(one-stage)算法。相继的,FAIR 也开发了自己的单阶段检测器。作者指出,YOLO2 和 SSD 模型都无法接近当前最佳的结果,而RetinaNet 可以轻松地实现单阶段的最佳的检测结果,而且速度较快,他们将这归功于新型损失函数(Focal Loss)的应用,而不是简单的网络结构(其结构仍以 FPN 为基础网络)。
作者认为,单阶段检测器将面临很多背景和正负类别样本数量不平衡的问题(而不仅仅的简单的正类别样本的不均衡问题),一般的加权损失函数仅仅是为了解决样本数量不均衡问题,而Focal Loss 函数主要是针对分类难度大/小的样本,而这正好能与 RetinaNet 很好地契合。
注意点:
-
两阶段(two-stage)目标检测器无需担心正、负样本的不均衡问题,因为在第一阶段就将绝大部分不均衡的样本都移除了。
-
RetinaNet 由两部分组成:主干网络(即卷积特征提取器,如 FPN)和两个特定任务的子网络(分类器和边界框回归器)。
-
采用不同的设计参数时,网络的性能不会发生太大的变化。
-
Anchor 或 AnchorBoxes 是与 RPN 中相同的 Anchor[5]。Anchor 的坐标是滑动窗口的中心位置,其大小、横纵比(aspect ratio)与滑动窗口的长宽比有关,大小从 322 到 512 ,横纵比取值为{1:2, 1:1, 2:1}。
-
用 FPN 来提取图像特征,在每一阶段都有 cls+bbox 子网络,用于给出 Anchor 中所有位置的对应输出。
实现代码
-
官方的Caffe2版本:
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
PyTorch版本:https://github.com/kuangliu/pytorch-retinanet
-
Keras版本:https://github.com/fizyr/keras-retinanet
-
MXNet版本:https://github.com/unsky/RetinaNet
▌Mask R-CNN
正如上面所述,Mask R-CNN [3]也几乎是同一个团队开发的,并发表在 ICCV 2017 上,用于图像的实例分割任务。简单来说,图像的实例分割不过就是不使用边界框的目标检测任务,目的是给出检测目标准确的分割掩码。这项任务想法简单,实现起来也并不困难,但是要使模型正常运行并达到当前最佳的水准,或者使用预训练好的模型来加快分割任务的实现等,想要做到这些可并不容易。
TL;DR:如果你了解 Faster R-CNN 的工作原理,那么 Mask R-CNN 模型对你来说是很简单的,只需要在 Faster R-CNN 的基础上添加一个用于分割的网络分支,其网络主体有 3 个分支,分别对应于 3 个不同的任务:分类、边界框回归和实例分割。
值得注意的是,Mask R-CNN 的最大贡献在于,仅仅使用简单、基础的网络设计,不需要多么复杂的训练优化过程及参数设置,就能够实现当前最佳的实例分割效果,并有很高的运行效率。
我很喜欢这篇论文,因为它的思想很简单。但是,那些看似简单的东西却伴有大量的解释。例如,多项式掩码与独立掩码的使用(softmax vs sigmoid)。
此外,Mask R-CNN 并未假设大量先验知识,因此在论文中也没有需要论证的内容。如果你有兴趣,可以仔细查看这篇论文,你可能会发现一些有趣的细节。基于你对 Faster RCNN已有了基础了解,我总结了以下一些细节帮助你进一步理解 Mask R-CNN:
-
首先,Mask R-CNN 与 Faster RCNN 类似,都是两阶段网络。第一阶段都是 RPN 网络。
-
Mask R-CNN 添加一个并行分割分支,用于预测分割的掩码,称之为 FCN。
-
Mask R-CNN 的损失函数由 L_cls、L_box、L_maskLcls、L_box、L_mask 四部分构成。
-
Mask R-CNN 中用 ROIAlign 层代替 ROIPool。这不像 ROIPool 中那样能将你的计算结果的分数部分(x/spatial_scale)四舍五入成整数,而是通过双线性内插值法来找出特定浮点值对应的像素。
-
例如:假定 ROI 高度和宽度分别是 54、167。空间尺度,也称为 stride 是图像大小 size/Fmap 的值(H/h),其值通常为 224/14=16 (H=224,h=14)。此外,还要注意的是:
-
ROIPool: 54/16, 167/16 = 3,10
-
ROIAlign: 54/16, 167/16 = 3.375, 10.4375
-
现在,我们使用双线性内插值法对其进行上采样。
-
根据 ROIAlign 输出的形状(如7x7),我们可以用类似的操作将对应的区域分割成合适大小的子区域。
-
使用 Chainer folks 检查 ROIPooling 的 Python 实现,并尝试自己实现 ROIAlign。
-
ROIAlign 的实现代码可在不同的库中获得,具体可查看下面给出的代码链接。
-
-
Mask R-CNN 的主干网络是 ResNet-FPN。
此外,我还曾专门写过一篇文章介绍过Mask-RCNN的原理,博客地址是:https://coming.soon/。
实现代码
-
官方的Caffe2版本:
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
Keras版本:https://github.com/matterport/Mask_RCNN/
-
PyTorch版本:https://github.com/soeaver/Pytorch_Mask_RCNN/
-
MXNet版本:https://github.com/TuSimple/mx-maskrcnn
▌Learning to Segment Everything
正如题目 Learning to Segment Everything 那样,这篇论文是关于目标分割任务,具体来说是解决实例分割问题。计算机视觉领域中标准的分割数据集对于现实的应用而言,数据集的数量都太有限了,即使是当前最流行、最丰富的 COCO 数据集[7],也仅有 80 种目标类别,这还远远无法达到实用的需求。
相比之下,目标识别及检测的数据集,如 OpenImages[8]就有将近 6000 个分类类别和 545 个检测类别。此外,斯坦福大学的另一个数据集 Visual Genome 也拥有近 3000 个目标类别。但由于这个数据集中每个类别所包含的目标数量太少了,即使它的类别在实际应用中更加丰富、有用,深度神经网络也无法在这样的数据集上取得足够好的性能,因此研究者通常不喜欢选用这些数据集进行目标分类、检测问题的研究。值得注意的是,这个数据集仅有 3000 个目标检测(边界框)的标签类别,而没有包含任何目标分割的标注,即无法直接用于目标分割的研究。
下面来介绍我们要讲的这篇论文[4]。
就数据集而言,实际上边界框与分割标注之间并不存在太大的区别,区别仅在于后者比前者的标注信息更加精确。因此,本文的作者正是利用 Visual Genome[9]数据集中有 3000 个类别的目标边界框标签来解决目标分割任务。我们称这种方法为弱监督学习,即不需要相关任务的完整监督信息。如果他们使用的是 COCO + Visual Genome 的数据集,即同时使用分割标签和边界框标签,那么这同样可称为是半监督学习。
让我们回到主题,这篇论文提出了一种非常棒的思想,其网络架构主要如下:
-
网络结构建立在 Mask-RCNN 基础上。
-
同时使用有掩码和无掩码的输入对模型进行训练。
-
在分割掩码和边界框掩码之间添加了一个权重迁移函数。
-
当使用一个无掩码的输入时,将
-
如下图所示:A 表示 COCO 数据集,B 表示 Visual Genome 数据集,对网络的不同输入使用不同的训练路径。
-
将两个损失同时进行反向传播将导致
-
Fix:当反向传播掩码损失时,要计算预测掩码的权重 τ 关于权重迁移函数参数 θ 的梯度值,而对边界框的权重
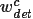
-
 ,其中 τ 表示预测掩码的权重值。
,其中 τ 表示预测掩码的权重值。
-
由于 Visual Genome 数据集没有分割标注,模型无法给出在该数据集上目标分割的准确率,因此作者在其他的数据集上展示模型的验证结果。PASCAL-VOC 数据集有 20 个目标类别,这些类别全部包含在 COCO 数据集中。因此,对于这 20 种类别,他们使用 PASCAL-VOC 数据集的分割标注及 COCO 数据集中相应类别的边界框标签对模型进行训练。
论文展示了在 COCO 数据集中这 20 个类别上,模型实例分割的结果。此外由于两个数据集包含两种不同的真实标签,他们还对相反的情况进行了训练,实验结果如下图所示。

-
Facebook
+关注
关注
3文章
1429浏览量
54795 -
计算机视觉
+关注
关注
8文章
1698浏览量
46022
原文标题:从FPN到Mask R-CNN,一文告诉你Facebook的计算机视觉有多强
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器视觉与计算机视觉的关系简述
计算机视觉领域的关键技术/典型算法模型/通信工程领域的应用方案
什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别
手把手教你操作Faster R-CNN和Mask R-CNN
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割

基于Mask R-CNN的遥感图像处理技术综述
用于实例分割的Mask R-CNN框架
PyTorch教程14.8之基于区域的CNN(R-CNN)

PyTorch教程-14.8。基于区域的 CNN (R-CNN)






 工商网监
工商网监
评论