 物体检测经典模型YOLO新升级,YOLOv3是一个很好的检测器
物体检测经典模型YOLO新升级,YOLOv3是一个很好的检测器
你肯定很少见到这样的论文,全文像闲聊一样,不愧是YOLO的发明者。物体检测领域的经典论文YOLO(You Only Look Once)的两位作者,华盛顿大学的Joseph Redmon和Ali Farhadi最新提出了YOLO的第三版改进YOLO v3,一系列设计改进,使得新模型性能更好,速度更快。达到相似的性能时,相比SSD,速度提高3倍;相比RetinaNet,速度提高3.8倍。
我今年没怎么做研究。我花了很多时间玩Twitter。玩了一下GAN。我去年留下了一些工作[10] [1]; 我设法对YOLO进行了一些改进。但是,说实话,不是什么超级有趣的工作,只是做了一系列更新,使它变得更好。我也有帮其他人做了一些研究。
没有错,你看的确实是一篇论文的开头。
今天,为你带来一篇不走寻常路的工作,计算机视觉经典模型YOLO作者的更新。
不只是开头,整片文章到处都嵌入诙谐,在结尾处还不忘告诉读者,不要@他。
放心,大多数研究计算机视觉的人都只是做点令人愉快的、好的事情,比如计算国家公园里斑马的数量[11],或者追踪溜进他们院子时的猫[17]。但是计算机视觉已经被用于被质疑的使用,作为研究人员,我们有责任至少思考一下我们的工作可能造成的损害,并思考如何减轻这种损害。我们非常珍惜这个世界。
那么,在作者沉浸Twitter的一年里,他们对YOLO做了哪些更新呢?

我们对YOLO进行了一些更新!我们做了一些小设计,使它的表现更好。我们还对这个新网络进行了训练。更新版的YOLO网络比上一版本稍大,但更准确。它的速度也还是很快,这点不用担心。在320 × 320下,YOLOv3以22.2 mAP在22 ms运行完成,达到与SSD一样的精确度,但速度提高了3倍。与上个版本的 0.5 IOU mAP检测指标相比,YOLOv3的性能是相当不错的。在Titan X上,它在51 ms内达到57.9 AP50,而RetinaNet达到57.5 AP50需要198 ms,性能相似,但速度提升3.8倍。
我今年没怎么做研究。我花了很多时间玩Twitter。玩了一下GAN。我去年留下了一些工作[10] [1]; 我设法对YOLO进行了一些改进。但是,说实话,不是什么超级有趣的工作,只是做了一系列更新,使它变得更好。我也有帮其他人做了一些研究。
这篇文章接下来将介绍YOLOv3,然后我会告诉你我们是怎么做的。我还会写一下我们尝试过但失败了的操作。最后,我们将思考这一切意味着什么。
YOLOv3
关于YOLOv3:我们主要是从其他人那里获得好点子。我们还训练了一个更好的新的分类网络。本文将从头开始介绍整个系统,以便大家理解。
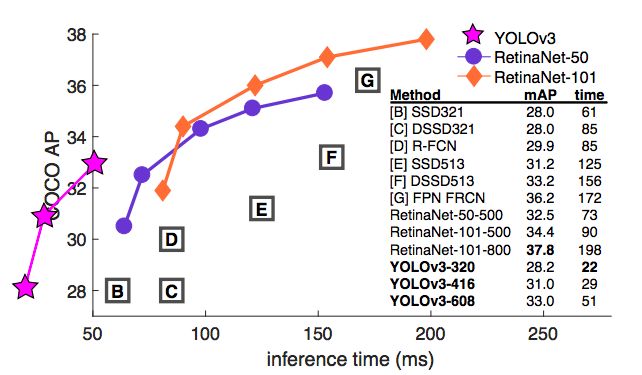
图1:这张图是从Focal Loss论文[7]拿来并修改的。 YOLOv3的运行速度明显快于其他性能相似的检测方法。运行时间来自M40或Titan X,基本上用的是相同的GPU。
边界框预测
在YOLO9000之后,我们的系统使用维度聚类(dimension cluster)作为anchor box来预测边界框[13]。网络为每个边界框预测4个坐标,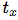
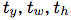 如果单元格从图像的左上角偏移了
如果单元格从图像的左上角偏移了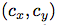 ,并且之前的边界框具有宽度
,并且之前的边界框具有宽度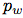 和高度
和高度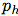 ,则预测对应以下等式:
,则预测对应以下等式:
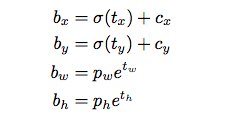
在训练期间,我们使用平方误差损失的和。如果一些坐标预测的ground truth是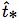 ,梯度就是ground truth值(从ground truth box计算出来)减去预测,即:
,梯度就是ground truth值(从ground truth box计算出来)减去预测,即: 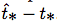 。 通过翻转上面的方程可以很容易地计算出这个ground truth值。
。 通过翻转上面的方程可以很容易地计算出这个ground truth值。
YOLOv3使用逻辑回归来预测每个边界框的 objectness score。如果边界框比之前的任何其他边界框都要与ground truth的对象重叠,则该值应该为1。如果先前的边界框不是最好的,但确实与ground truth对象重叠超过某个阈值,我们会忽略该预测,如Faster R-CNN一样[15]。我们使用.5作为阈值。 但与[15]不同的是,我们的系统只为每个ground truth对象分配一个边界框。如果先前的边界框未分配给一个ground truth对象,则不会对坐标或类别预测造成损失,只会导致objectness。
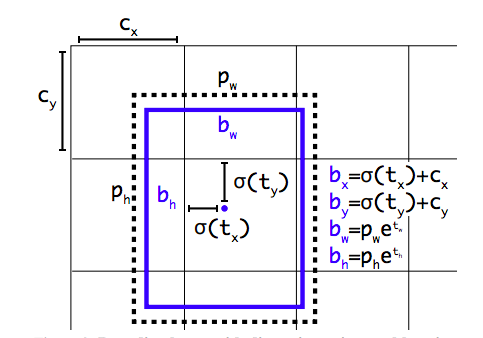
图2: 具有dimension priors和location prediction的边界框。我们预测了框的宽度和高度,作为cluster centroids的偏移量。我们使用sigmoid函数预测相对于滤波器应用位置的边界框的中心坐标。这个图是从YOLO9000论文[13]拿来的。
类别预测
每个框使用多标签分类来预测边界框可能包含的类。我们不使用softmax,因为我们发现它对于性能没有影响,而是只是使用独立的逻辑分类器。在训练过程中,我们使用二元交叉熵损失来进行类别预测。
这个公式有助于我们转向更复杂的领域,如Open Images数据集[5]。在这个数据集中有许多重叠的标签(例如,Woman和Person)。可以使用softmax强加一个假设,即每个box只包含一个类别,但通常情况并非如此。多标签方法可以更好地模拟数据。
不同尺度的预测
YOLOv3可以预测3种不同尺度的box。我们的系统使用一个特征金字塔网络[6]来提取这些尺度的特征。在基本特征提取器中,我们添加了几个卷积层。其中最后一层预测三维tensor编码的边界框,objectness 和类别预测。我们在COCO[8]数据集的实验中,每个尺度预测3个box,因此tensor为N×N×[3 *(4 + 1 + 80)],4个边界框offset,1 objectness预测,以及80个类别预测。
接下来,我们从之前的2个层中取得特征图,并对其进行2倍上采样。我们还从网络获取特征图,并使用 element-wise 添加将其与我们的上采样特征进行合并。这种方法使我们能够从上采样的特征和早期特征映射的细粒度信息中获得更有意义的语义信息。然后,我们再添加几个卷积层来处理这个组合的特征图,并最终预测出一个相似的Tensor,虽然现在它的大小已经增大两倍。
我们再次执行相同的设计来对最终的scale预测box。因此,我们对第3个scale的预测将从所有之前的计算中获益,并从早期的网络中获得精细的特征。
我们仍然使用k-means聚类来确定bounding box priors。我们只是选择了9个clusters和3个scales,然后在整个scales上均匀分割clusters。在COCO数据集上,9个cluster分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90) ,(156×198),(373×326)。
特征提取器
我们使用一个新的网络来执行特征提取。该新网络是用于YOLOv2,Darknet-19的网络和更新的残差网络的混合方法。我们的网络使用连续的3×3和1×1卷积层,但现在也有一些shortcut连接,并且网络的大小显著更大。它有53个卷积层,所以我们称之为......Darknet-53!

这个新网络比Darknet19强大得多,而且比ResNet-101或ResNet-152更高效。以下是在ImageNet上的结果:
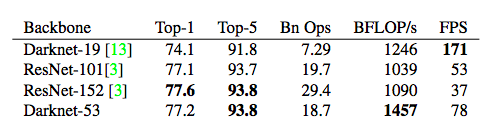
表2:网络的比较。各网络的准确性、Bn Ops、每秒浮点运算次数,以及FPS。
每个网络都使用相同的设置进行训练,并在256×256的单精度进行测试。Runtime是在Titan X上以256×256进行测量的。可以看到,Darknet-53可与最先进的分类器相媲美,但浮点运算更少,速度更快。Darknet-53比ResNet-101性能更好,而且速度快1.5倍。Darknet-53与ResNet-152具有相似的性能,速度提高2倍。
Darknet-53也可以实现每秒最高的测量浮点运算。这意味着网络结构可以更好地利用GPU,从而使其评估效率更高,速度更快。这主要是因为ResNets的层数太多,效率不高。
训练
我们仍然用完整的图像进行训练。我们使用不同scale进行训练,使用大量的数据增强,批规范化,等等。我们使用Darknet神经网络框架进行训练和测试[12]。
具体做法和结果
YOLOv3的表现非常好!请参见表3。就COCO奇怪的平均mean AP指标而言,它与SSD的变体性能相当,但速度提高了3倍。不过,它仍比RetinaNet模型差一些。
当时,以mAP的“旧”检测指标比较时,当IOU = 0.5(或表中的AP50)时,YOLOv3非常强大。它的性能几乎与RetinaNet相当,并且远高于SSD的变体。这表明YOLOv3是一个非常强大的对象检测网络。不过,随着IOU阈值增大,YOLOv3的性能下降,使边界框与物体完美对齐的效果不那么好。
过去,YOLO不擅长检测较小的物体。但是,现在我们看到了这种情况已经改变。由于新的多尺度预测方法,我们看到YOLOv3具有相对较高的APS性能。但是,它在中等尺寸和更大尺寸的物体上的表现相对较差。
当用AP50指标表示精确度和速度时(见图3),可以看到YOLOv3与其他检测系统相比具有显着的优势。也就是说,YOLOv3更快、而且更好。
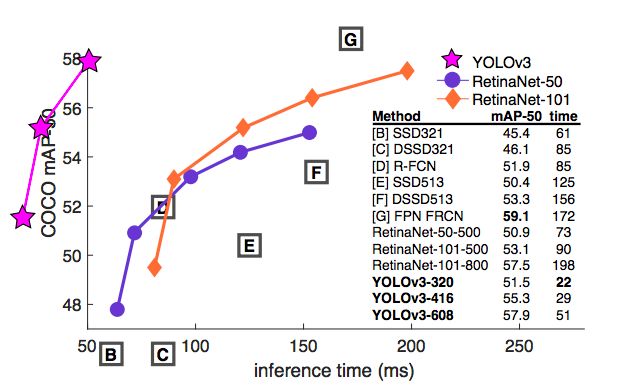
图3
一些试了没用的方法
我们在研究YOLOv3时尝试了很多方法。很多都不起作用。这些可以了解一下。
Anchor box x,y 偏移量预测。我们尝试使用常规的anchor box预测机制,可以使用线性激活将x,y的偏移预测为box的宽度或高度的倍数。我们发现这种方法降低了模型的稳定性,并且效果不佳。
线性x,y预测,而不是逻辑预测。我们尝试使用线性激活来直接预测x,y的偏移,而不是用逻辑激活。这导致了MAP的下降。
Focal loss。我们尝试使用Focal loss。这一方法使mAP降低了2点左右。YOLOv3对Focal loss解决的问题可能已经很强健,因为它具有单独的对象预测和条件类别预测。因此,对于大多数例子来说,类别预测没有损失?或者其他原因?这点还不完全确定。
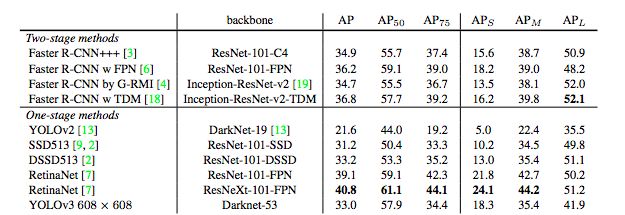
表3:再次,这张图来自论文[7],稍作了调整。这里显示的速度/准确度在mAP上以0.5 IOU度量进行折衷。你可以看到,YOLOv3很厉害,因为它非常高,而且离左轴远。
双IOU阈值和truth分配。 Faster RCNN在训练期间使用两个IOU阈值。如果一个预测与.7的 ground truth 重叠,它就是一个正面的例子,[.3-.7]它被忽略。如果对于所有ground truth对象,它都小于.3,这就是一个负面的例子。我们尝试了类似的策略,但无法取得好的结果。
这一切意味着什么
YOLOv3是一个很好的检测器。速度很快,而且很准确。在COCO上,平均AP介于0.5和0.95 IOU时,准确度不是很好。但是,对于0.5 IOU这个指标来说,YOLOv3非常好。
为什么我们要改变指标?原始的COCO论文上只有这样一句含糊不清的句子:“一旦评估服务器完成,我们会添加不同评估指标的完整讨论”。Russakovsky等人在论文中说,人类很难区分0.3与0.5的IOU。“人们目测检查一个IOU值为0.3的边界框,并将它与IOU 0.5的区分开来,这是非常困难的事情。”[16]如果人类都很难区分这种差异,那么它就没有那么重要。
也许更值得思考的问题是:“现在我们有了这些检测器,我们拿它们来做什么?”很多做这类研究的人都在Google或Facebook工作。我想至少我们已经知道这项技术已经被掌握得很好了,绝对不会用来收集你的个人信息并将其出售给....等等,你说这正是它的目的用途?Oh.
放心,大多数研究计算机视觉的人都只是做点令人愉快的、好的事情,比如计算国家公园里斑马的数量[11],或者追踪溜进他们院子时的猫[17]。但是计算机视觉已经被用于被质疑的使用,作为研究人员,我们有责任至少思考一下我们的工作可能造成的损害,并思考如何减轻这种损害。我们非常珍惜这个世界。
-
计算机视觉
+关注
关注
8文章
1698浏览量
45965 -
K-means
+关注
关注
0文章
28浏览量
11292
原文标题:【史上最有趣论文】物体检测经典模型YOLO新升级,就看一眼,速度提升 3 倍!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于YOLOv3的红绿灯检测识别(Python源码可直接运行)
《DNK210使用指南 -CanMV版 V1.0》第四十一章 YOLO2物体检测实验
微功率有毒气体检测器是一种低功率电池供电的便携式气体检测器
基于RK3399pro开发板的YOLOV3开发与实现
全志V853 在 NPU 转换 YOLO V3 模型
NDIR气体检测器解决方案和PID气体检测器解决方案
基于YOLOV3算法的视频监控目标检测方法
基于神经网络的、改进的YOLOv3目标检测算法

一阶段的物体检测器,从直觉到细节的方方面面(一)

深度学习YOLOv3 模型设计的基本思想






 工商网监
工商网监
评论