 简单随机搜索:无模型强化学习的高效途径
简单随机搜索:无模型强化学习的高效途径
现在人们对无模型强化学习的一个普遍看法是,这种基于随机搜索策略的方法在参数空间中比那些探索行为空间的方法表现出更差的样本复杂性。UC Berkeley的研究人员通过引入随机搜索方法,推翻了这种说法。以下是论智对作者Benjamin Recht博文的编译。
我们已经看到,随机搜索在简单的线性问题上表现得很好,而且似乎比一些强化学习方法(例如策略梯度)更好。然而随着问题难度增加,随机搜索是否会崩溃?答案是否定的。但是,请继续读下去!
让我们在强化学习社区感兴趣的问题上应用随机搜索。深度强化学习领域一直把大量时间和精力用于由OpenAI维护的、基于MuJoCo模拟器的一套基准测试中。这里,最优控制问题指的是让一个有腿机器人在一个方向上尽可能快地行走,越远越好。其中一些任务非常简单,但是有些任务很难,比如这种有22个自由度的复杂人形模型。有腿机器人的运动由Hamilton方程控制,但是从这些模型中计划动作是非常具有挑战性的,因为没有设计目标函数的最佳方法,并且模型是分段线性的。只要机器人的任何部位碰到坚硬物体,模型就会变化,因此会出现此前没有的作用于机器人的法向力。于是,让机器人无需处理复杂的非凸非线性模型而正常工作,对强化学习来说是个有趣的挑战。
最近,Salimans及其在OpenAI的合作者表示,随机搜索在这些标准测试中表现的很好,尤其是加上几个算法增强后很适合神经网络控制器。在另一项实验中,Rajeswaran等人表示,自然策略梯度可以学习用于完成标准的先行策略。也就是说,他们证明静态线性状态的反馈——就像我们在LQR(Linear Quadratic Regulator)中使用的那样——也足以控制这些复杂的机器人模拟器。但这仍然有一个问题:简单随机搜索能找到适合MuJoCo任务的线性控制器吗?
我的学生Aurelia Guy和Horia Mania对此进行了测试,他们编写了一个非常简单的随机搜索版本(是我之前发布的Iqrpols.py中的一个)。令人惊讶的是,这个简单的算法学习了Swimmer-v1,Hopper-v1,Walker2d-v1和Ant-v1任务中的线性策略,这些策略实现了之前文章中提出的奖励阈值。不错!
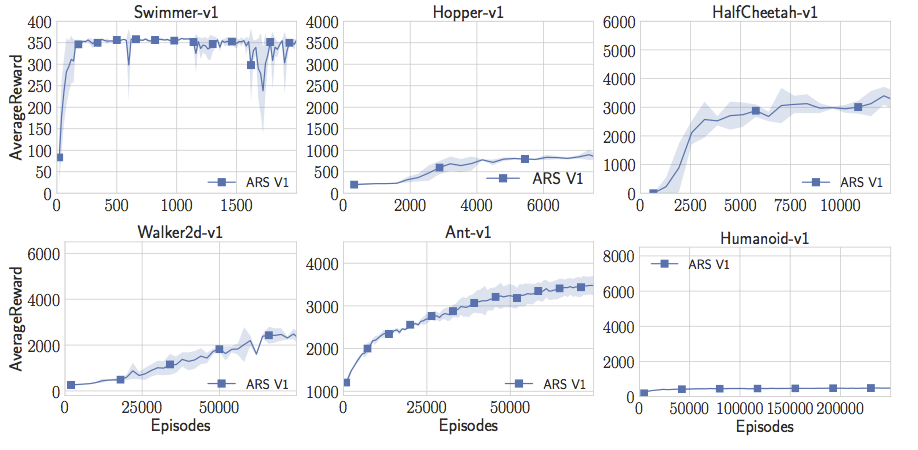
但是只有随机搜索还不够完美。Aurelia和Horia完全不能用人形模型做出有趣的事。试了很多次参数调整后,他们决定改进随机搜索,让它训练地更快。Horia注意到许多强化学习的论文利用状态的统计数据,并且在将状态传递给神经网络之前能够将状态白化。所以他开始保持在线估计状态,在将他们传递给线性控制器之前将它们白化。有了这个简单的窍门,Aurelia和Horia现在可以让人形机器人做出最佳表现。这实际上是Salimans等人在标准值上达到的“成功阈值”的两倍。只需要线性控制器、随机搜索和一个简单的技巧。
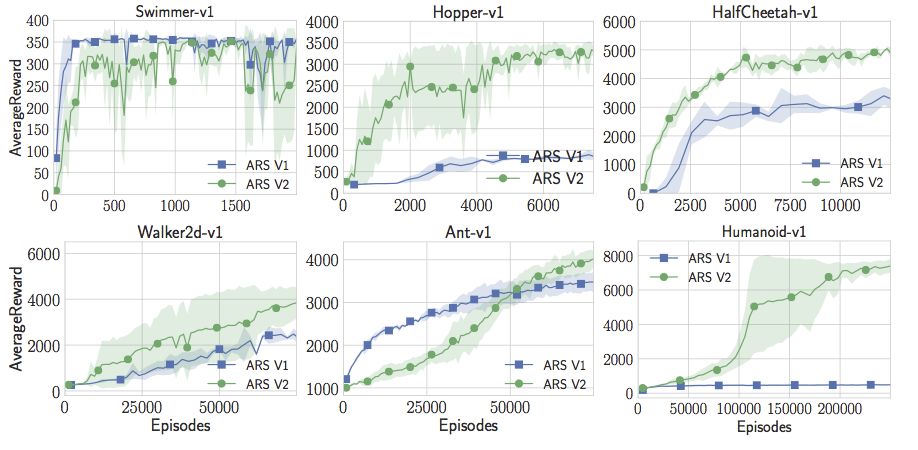
另外还有一件简单的事情就是,代码比OpenAI的进化策略论文中的要快15倍。我们可以用更少的计算获得更高的奖励。用户可以在一小时内在标准18核EC2实例上训练一个高性能人形模型。
现在,随着在线状态的更新,随机搜索不仅超过了人形模型的最佳水平,而且还超越了Swimmer-v1、Hopper-v1、HalfCheetah-v1。但在Walker2d-v1和Ant-v1上的表现还不是很好。但是我们可以再添加一个小技巧。我们可以放弃不会产生良好回报的采样方向。这增加了一个超参数,但有了这一额外的调整,随机搜索实际上可能会达到或超过OpenAI的gym中所有MuJoCo标准的最佳性能。注意,这里并不限制与策略梯度的比较。就我所知,这些策略比任何无模型强化学习的应用结果要好,无论是Actor Critic Method还是Value Function Estimation Method等等更深奥的东西。对于这类MuJoCo问题,似乎纯粹的随机搜索优于深度强化学习和神经网络。
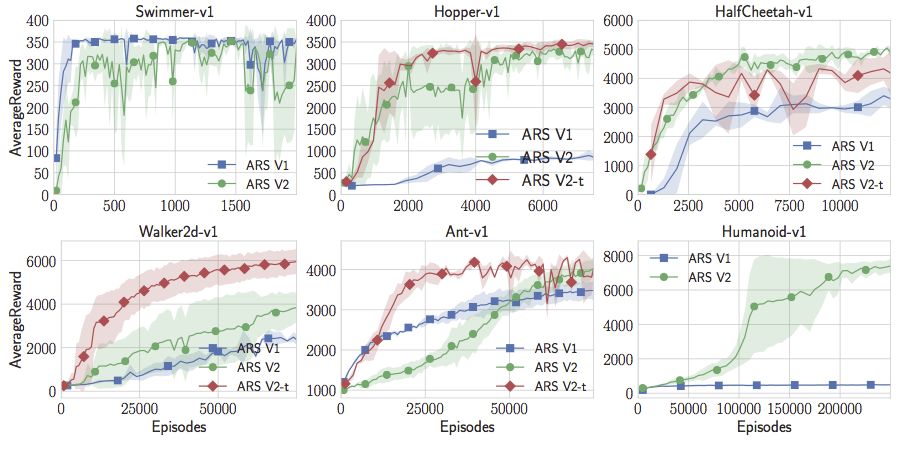
通过一些小调整得到的随机搜索结果胜过了MuJoCo任务中的所有其他方法,并且速度更快。论文和代码都已公布。
从随机搜索中,我们有了以下几点收获:
基准很难
我认为所有这一切唯一合理的结论就是这些MuJoCo Demo很容易,毫无疑问。但是,用这些标准测试NIPS、ICML或ICLR中的论文可能不再合适。这就出现了一个重要的问题:什么是强化学习的良好标准?显然,我们需要的不仅仅是Mountain Car。我认为具有未知动作的LQR是一个合理的任务,因为确定新实例并了解性能的限制是很容易的。但是该领域应该花更多时间了解如何建立有难度的标准。
不要在模拟器上抱太大希望
这些标准比较容易的一部分原因是MuJoCo不是一个完美的模拟器。MuJoCo非常快,并且对于概念验证非常有用。但为了快速起见,它必须在接触点周围进行平滑处理(接触的不连续是使腿部运动困难的原因)。因此,你只能让其中一个模拟器走路,并不意味着你可以让真正的机器人走路。的确,这里有四种让奖励可以达到6000的步态,但看起来都不太现实:
即使是表现最好的模型(奖励达到11600),如下图所示,这种看起来很蠢的步态也不可能应用在现实中:
努力将算法简化
在简单算法中添加超参数和算法小部件,可以在足够小的一组基准测试中提高其性能。我不确定是否放弃最好的方向或状态归一化会对新的随机搜索问题起作用,但这对MuJoCo的标准和有用。通过添加更多可调参数,甚至可以获得更多回报。
使用之前先探索
注意,由于随机搜索方法很快,我们可以评估它在许多随机种子上的表现。这些无模型的方法在这些基准上都表现出惊人的巨大差异。例如,在人形任务中,即使我们提供了我们认为是好的参数,模型的训练时间也慢了四分之一。对于那些随机种子,它会找到相当奇特的步态。如果将注意力限定在三个随机种子上用于随机搜索,通常具有误导性,因为你可能会将性能调整为随机数生成器的特性。
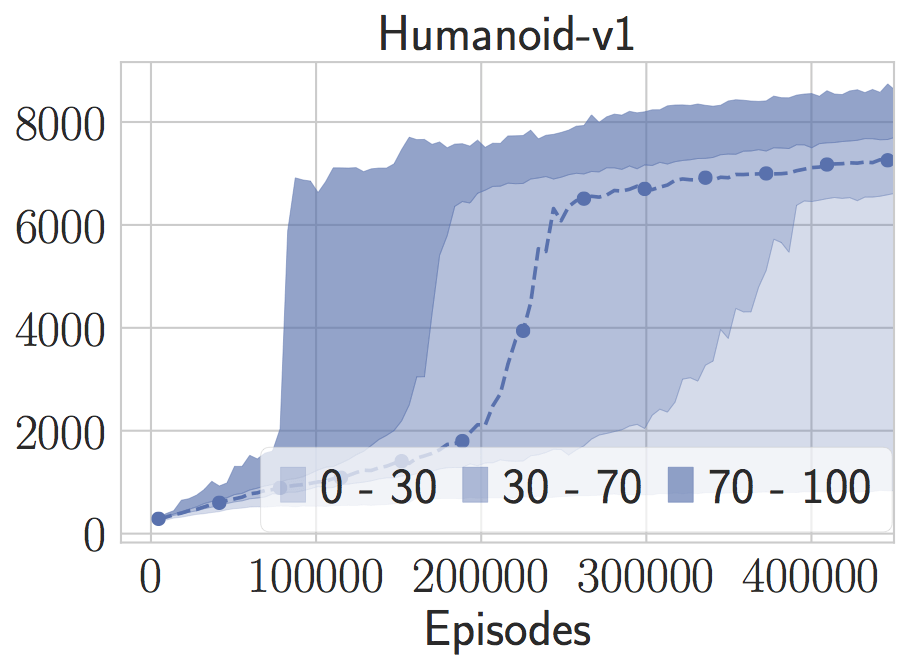
这种现象在LQR上也出现了。我们可以将算法向一些随机种子进行微调,然后在新的随机种子上看到完全不同的行为。Henderson等人用深度强化学习方法观察了这些现象,但我认为如此高的变量将成为所有无模型方法的通用症状。仅通过模拟就能解释很多边界情况。正如我在上一篇文章中所说的:“通过抛弃模型和知识,我们永远不知道是否可以从少数实例和随机种子中学到足够的东西进行概括。”
-
强化学习
+关注
关注
4文章
269浏览量
11366
原文标题:简单随机搜索:强化学习的高效途径
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
详解RAD端到端强化学习后训练范式

百度搜索与文心智能体平台接入DeepSeek及文心大模型深度搜索
浅谈适用规模充电站的深度学习有序充电策略
蚂蚁集团收购边塞科技,吴翼出任强化学习实验室首席科学家
如何使用 PyTorch 进行强化学习
AI大模型与深度学习的关系
谷歌AlphaChip强化学习工具发布,联发科天玑芯片率先采用
月访问量超2亿,增速113%!360AI搜索成为全球增速最快的AI搜索引擎
【《大语言模型应用指南》阅读体验】+ 基础知识学习
深度学习中的无监督学习方法综述
tensorflow简单的模型训练
通过强化学习策略进行特征选择






 工商网监
工商网监
评论