 Read系统调用在用户空间中的处理过程
Read系统调用在用户空间中的处理过程
Read 系统调用在用户空间中的处理过程
Linux 系统调用(SCI,system call interface)的实现机制实际上是一个多路汇聚以及分解的过程,该汇聚点就是 0x80 中断这个入口点(X86 系统结构)。也就是说,所有系统调用都从用户空间中汇聚到 0x80 中断点,同时保存具体的系统调用号。当 0x80 中断处理程序运行时,将根据系统调用号对不同的系统调用分别处理(调用不同的内核函数处理)。系统调用的更多内容,请参见参考资料。
Read 系统调用也不例外,当调用发生时,库函数在保存 read 系统调用号以及参数后,陷入 0x80 中断。这时库函数工作结束。Read 系统调用在用户空间中的处理也就完成了。
Read 系统调用在核心空间中的处理过程
0x80 中断处理程序接管执行后,先检察其系统调用号,然后根据系统调用号查找系统调用表,并从系统调用表中得到处理 read 系统调用的内核函数 sys_read ,最后传递参数并运行 sys_read 函数。至此,内核真正开始处理 read 系统调用(sys_read 是 read 系统调用的内核入口)。
在讲解 read 系统调用在核心空间中的处理部分中,首先介绍了内核处理磁盘请求的层次模型,然后再按该层次模型从上到下的顺序依次介绍磁盘读请求在各层的处理过程。
Read 系统调用在核心空间中处理的层次模型
图1显示了 read 系统调用在核心空间中所要经历的层次模型。从图中看出:对于磁盘的一次读请求,首先经过虚拟文件系统层(vfs layer),其次是具体的文件系统层(例如 ext2),接下来是 cache 层(page cache 层)、通用块层(generic block layer)、IO 调度层(I/O scheduler layer)、块设备驱动层(block device driver layer),最后是物理块设备层(block device layer)
图1 read 系统调用在核心空间中的处理层次
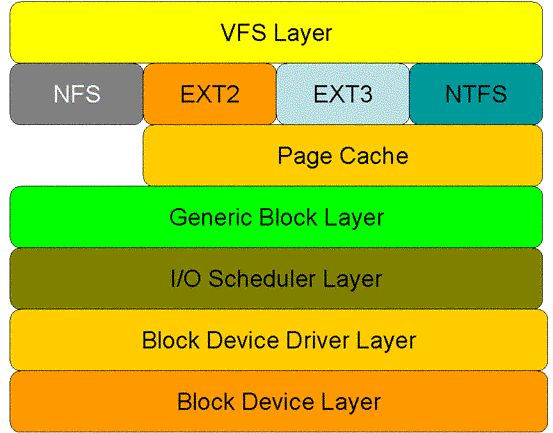
虚拟文件系统层的作用:屏蔽下层具体文件系统操作的差异,为上层的操作提供一个统一的接口。正是因为有了这个层次,所以可以把设备抽象成文件,使得操作设备就像操作文件一样简单。
在具体的文件系统层中,不同的文件系统(例如 ext2 和 NTFS)具体的操作过程也是不同的。每种文件系统定义了自己的操作集合。关于文件系统的更多内容,请参见参考资料。
引入 cache 层的目的是为了提高 linux 操作系统对磁盘访问的性能。 Cache 层在内存中缓存了磁盘上的部分数据。当数据的请求到达时,如果在 cache 中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。
通用块层的主要工作是:接收上层发出的磁盘请求,并最终发出 IO 请求。该层隐藏了底层硬件块设备的特性,为块设备提供了一个通用的抽象视图。
IO 调度层的功能:接收通用块层发出的 IO 请求,缓存请求并试图合并相邻的请求(如果这两个请求的数据在磁盘上是相邻的)。并根据设置好的调度算法,回调驱动层提供的请求处理函数,以处理具体的 IO 请求。
驱动层中的驱动程序对应具体的物理块设备。它从上层中取出 IO 请求,并根据该 IO 请求中指定的信息,通过向具体块设备的设备控制器发送命令的方式,来操纵设备传输数据。
设备层中都是具体的物理设备。定义了操作具体设备的规范。
相关的内核数据结构:
Dentry : 联系了文件名和文件的 i 节点
inode : 文件 i 节点,保存文件标识、权限和内容等信息
file : 保存文件的相关信息和各种操作文件的函数指针集合
file_operations :操作文件的函数接口集合
address_space :描述文件的 page cache 结构以及相关信息,并包含有操作 page cache 的函数指针集合
address_space_operations :操作 page cache 的函数接口集合
bio : IO 请求的描述
数据结构之间的关系:
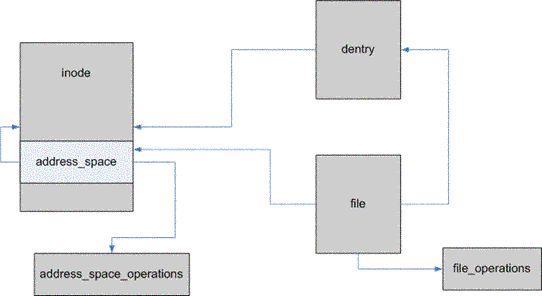
图2示意性地展示了上述各个数据结构(除了 bio)之间的关系。可以看出:由 dentry 对象可以找到 inode 对象,从 inode 对象中可以取出 address_space 对象,再由 address_space 对象找到 address_space_operations 对象。
File 对象可以根据当前进程描述符中提供的信息取得,进而可以找到 dentry 对象、 address_space 对象和 file_operations 对象。
图2 数据结构关系图:
前提条件:
对于具体的一次 read 调用,内核中可能遇到的处理情况很多。这里举例其中的一种情况:
要读取的文件已经存在
文件经过 page cache
要读的是普通文件
磁盘上文件系统为 ext2 文件系统,有关 ext2 文件系统的相关内容,参见参考资料
准备:
注:所有清单中代码均来自 linux2.6.11 内核原代码
读数据之前,必须先打开文件。处理 open 系统调用的内核函数为 sys_open 。所以我们先来看一下该函数都作了哪些事。清单1显示了 sys_open 的代码(省略了部分内容,以后的程序清单同样方式处理)
清单1 sys_open 函数代码

代码解释:
get_unuesed_fd() :取回一个未被使用的文件描述符(每次都会选取最小的未被使用的文件描述符)。
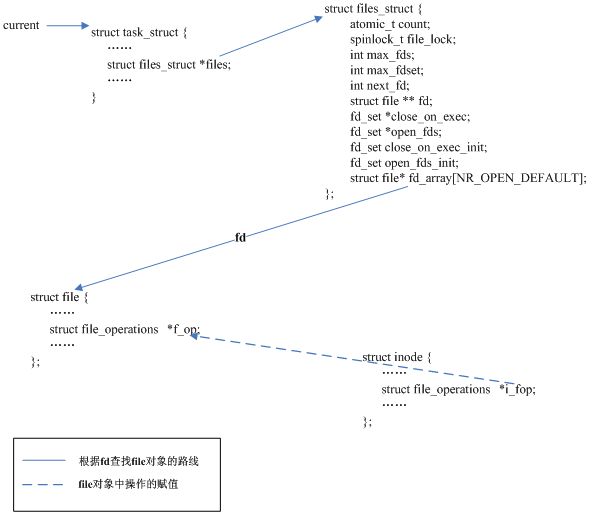
filp_open() :调用 open_namei() 函数取出和该文件相关的 dentry 和 inode (因为前提指明了文件已经存在,所以 dentry 和 inode 能够查找到,不用创建),然后调用 dentry_open() 函数创建新的 file 对象,并用 dentry 和 inode 中的信息初始化 file 对象(文件当前的读写位置在 file 对象中保存)。注意到 dentry_open() 中有一条语句:
f->f_op = fops_get(inode->i_fop);
这个赋值语句把和具体文件系统相关的,操作文件的函数指针集合赋给了 file 对象的 f _op 变量(这个指针集合是保存在 inode 对象中的),在接下来的 sys_read 函数中将会调用 file->f_op 中的成员 read 。
fd_install() :以文件描述符为索引,关联当前进程描述符和上述的 file 对象,为之后的 read 和 write 等操作作准备。
函数最后返回该文件描述符。
图3显示了 sys_open 函数返回后, file 对象和当前进程描述符之间的关联关系,以及 file 对象中操作文件的函数指针集合的来源(inode 对象中的成员 i_fop)。
图3 file 对象和当前进程描述符之间的关系
到此为止,所有的准备工作已经全部结束了,下面开始介绍 read 系统调用在图1所示的各个层次中的处理过程。
虚拟文件系统层的处理:
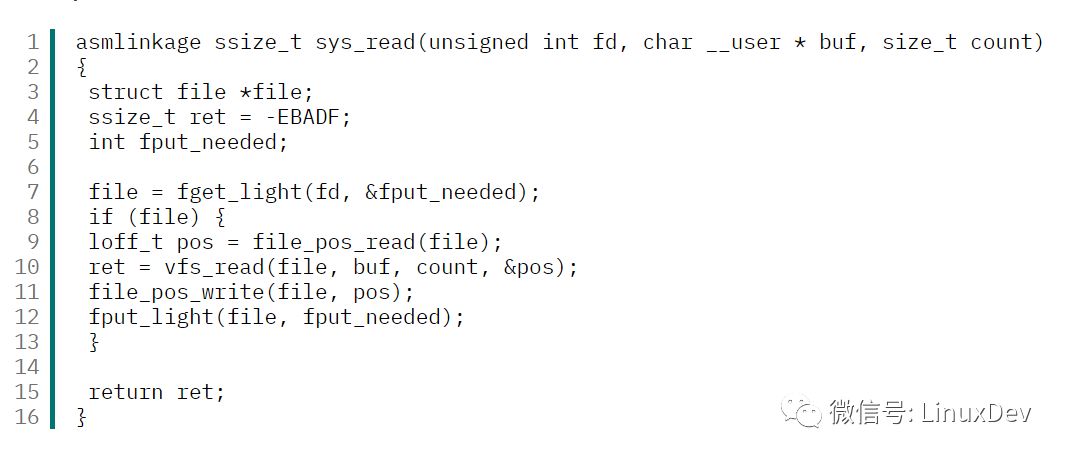
内核函数 sys_read() 是 read 系统调用在该层的入口点,清单2显示了该函数的代码。
清单2 sys_read 函数的代码
代码解析:
fget_light() :根据 fd 指定的索引,从当前进程描述符中取出相应的 file 对象(见图3)。
如果没找到指定的 file 对象,则返回错误
如果找到了指定的 file 对象:
调用 file_pos_read() 函数取出此次读写文件的当前位置。
调用 vfs_read() 执行文件读取操作,而这个函数最终调用 file->f_op.read() 指向的函数,代码如下:
if (file->f_op->read)ret = file->f_op->read(file, buf, count, pos);
调用 file_pos_write() 更新文件的当前读写位置。
调用 fput_light() 更新文件的引用计数。
最后返回读取数据的字节数。
到此,虚拟文件系统层所做的处理就完成了,控制权交给了 ext2 文件系统层。
在解析 ext2 文件系统层的操作之前,先让我们看一下 file 对象中 read 指针来源。
File 对象中 read 函数指针的来源:
从前面对 sys_open 内核函数的分析来看, file->f_op 来自于 inode->i_fop 。那么 inode->i_fop 来自于哪里呢?在初始化 inode 对象时赋予的。见清单3。
清单3 ext2_read_inode() 函数部分代码
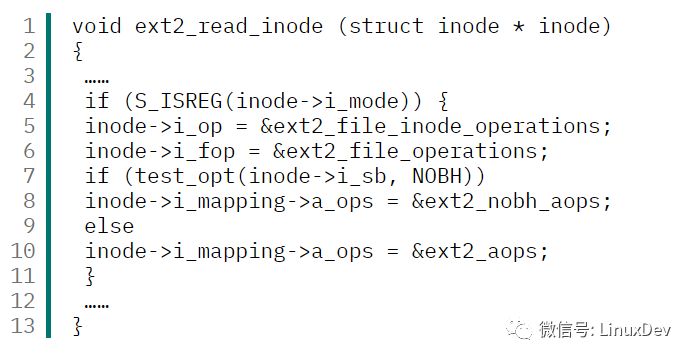
从代码中可以看出,如果该 inode 所关联的文件是普通文件,则将变量 ext2_file_operations 的地址赋予 inode 对象的 i_fop 成员。所以可以知道: inode->i_fop.read 函数指针所指向的函数为 ext2_file_operations 变量的成员 read 所指向的函数。下面来看一下 ext2_file_operations 变量的初始化过程,如清单4。
清单4 ext2_file_operations 的初始化

该成员 read 指向函数 generic_file_read 。所以, inode->i_fop.read 指向 generic_file_read 函数,进而 file->f_op.read 指向 generic_file_read 函数。最终得出结论: generic_file_read 函数才是 ext2 层的真实入口。
Ext2 文件系统层的处理
图4 read 系统调用在 ext2 层中处理时函数调用关系
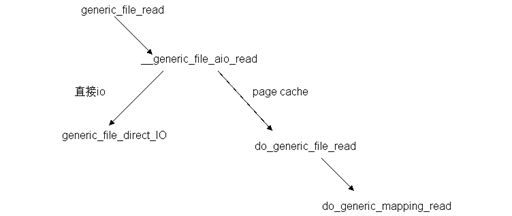
由图 4 可知,该层入口函数 generic_file_read 调用函数 __generic_file_aio_read ,后者判断本次读请求的访问方式,如果是直接 io (filp->f_flags 被设置了 O_DIRECT 标志,即不经过 cache)的方式,则调用 generic_file_direct_IO 函数;如果是 page cache 的方式,则调用 do_generic_file_read 函数。函数 do_generic_file_read 仅仅是一个包装函数,它又调用 do_generic_mapping_read 函数。
在讲解 do_generic_mapping_read 函数都作了哪些工作之前,我们再来看一下文件在内存中的缓存区域是被怎么组织起来的。
文件的 page cache 结构
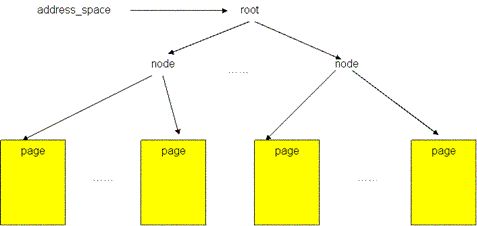
图5显示了一个文件的 page cache 结构。文件被分割为一个个以 page 大小为单元的数据块,这些数据块(页)被组织成一个多叉树(称为 radix 树)。树中所有叶子节点为一个个页帧结构(struct page),表示了用于缓存该文件的每一个页。在叶子层最左端的第一个页保存着该文件的前4096个字节(如果页的大小为4096字节),接下来的页保存着文件第二个4096个字节,依次类推。树中的所有中间节点为组织节点,指示某一地址上的数据所在的页。此树的层次可以从0层到6层,所支持的文件大小从0字节到16 T 个字节。树的根节点指针可以从和文件相关的 address_space 对象(该对象保存在和文件关联的 inode 对象中)中取得(更多关于 page cache 的结构内容请参见参考资料)。
图5 文件的 page cache 结构
现在,我们来看看函数 do_generic_mapping_read 都作了哪些工作, do_generic_mapping_read 函数代码较长,本文简要介绍下它的主要流程:
根据文件当前的读写位置,在 page cache 中找到缓存请求数据的 page
如果该页已经最新,将请求的数据拷贝到用户空间
否则, Lock 该页
调用 readpage 函数向磁盘发出添页请求(当下层完成该 IO 操作时会解锁该页),代码:
| 1 |
-
Linux
+关注
关注
87文章
11373浏览量
211287 -
Read
+关注
关注
0文章
10浏览量
11166 -
数据结构
+关注
关注
3文章
573浏览量
40321
原文标题:read 系统调用剖析
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论