 如何描述机器学习中的一些综合能力
如何描述机器学习中的一些综合能力
当我在阅读机器学习相关文献的时候, 我经常思考这项工作是否:
提高了模型的表达能力;
使模型更易于训练;
提高了模型的泛化性能。
在这篇博文中, 我们讨论当前的机器学习研究:监督学习, 无监督学习和强化学习在这些方面的表现。谈到模型的泛化性能的时候, 我把它分为两类:「弱泛化」和「强泛化」。我将会在后面分别讨论它们。 下表总结了我眼中的研究现状:
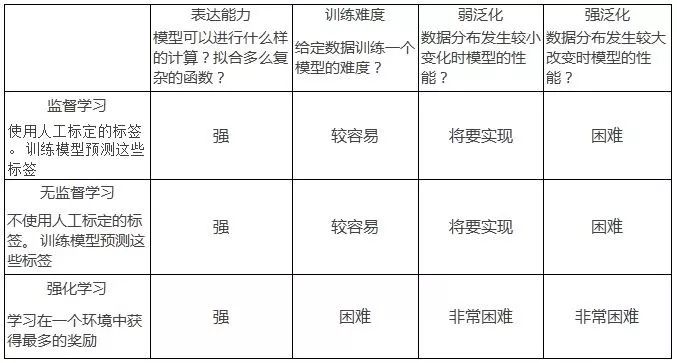
这篇博文涵盖了相当宽泛的研究领域,仅表达我个人对相关研究的看法,不反映我的同事和公司的观点。欢迎读者进行讨论以及给出修改的建议, 请在评论中提供反馈或发送电子邮件给我。
表达能力 expressivity
模型可以进行什么样的计算, 拟合多么复杂的函数?
模型的表达能力用来衡量参数化模型如神经网络的可以拟合的函数的复杂程度。深度神经网络的表达能力随着它的深度指数上升, 这意味着中等规模的神经网络就拥有表达监督、 半监督、强化学习任务的能力[2]。 深度神经网络可以记住非常大的数据集就是一个很好的佐证。
最近在产生式模型研究上的突破证明了神经网络强大的表达能力:神经网络可以找到几乎与真实数据难以分辨的极为复杂的数据流形(如音频, 图像数据的流形)。下面是NVIDIA研究人员提出的新的基于产生式对抗神经网络的模型的生成结果:
产生的图像仍然不是很完美(注意不自然的背景),但是已经非常好了。同样的, 在音频合成中,最新的 WaveNet 模型产生的音频也已经非常像人类了。
在强化学习中神经网络看起来也有足够的表达能力。 很小的网络(2个卷积层2个全连接层)就足够解决Atari 和 MuJoCo 控制问题了(虽然它们的训练还是一个问题,我们将在下一个部分讨论)。
模型的表达能力问题是最容易的(增加一些层即可), 但同时也是最神秘的:我们无法找到一个很好的方法来度量对于一个给定的任务我们需要多强的(或什么类型的)表达能力。
什么样的问题会需要比我们现在用的神经网络大得多的网络?为什么这些任务需要这么大量的计算?我们现有的神经网络是否有足够的表达能力来表现像人类一样的智能?要解决更加困难的问题的泛化问题会需要表达能力超级强的模型吗?
人的大脑有比我们现在的大网络(Inception-ResNet-V2 有大概 25e6 ReLU结点)多很多数量级的「神经节点」(1e11)。 这个结点数量上的差距已经很巨大了, 更别提 ReLU 单元根本无法比拟生物神经元。
训练难度 trainability
给定一个有足够表达能力的模型结构, 我能够训练出一个好的模型吗(找到好的参数)
任何一个从数据中学习到一定功能的计算机程序都可以被称为机器学习模型。在「学习」过程中, 我们在(可能很大的)模型空间内搜索一个比较好的, 利用数据中的知识学到的模型来做决策。 搜索的过程常常被构造成一个在模型空间上的优化问题。

优化的不同类型
一个具体的例子:最小化平均交叉熵是训练神经网络分类图像的标准方法。我们希望模型在训练集上的交叉熵损失达到最小时, 模型在测试数据上可以以一定精度或召回来正确分类图像。
搜索好的模型(训练)最终会变为一个优化问题——没有别的途径! 但是有时候我们很难去定义优化目标。 在监督学习中的一个经典的例子就是图像下采样:我们无法定义一个标量可以准确反映出我们人眼感受到的下采样造成的「视觉损失」。
同样地, 超分辨率图像和图像合成也非常困难,因为我们很难把效果的好坏写成一个标量的最大化目标:想象一下, 如何设计一个函数来判断一张图片有多像一张真实的照片?事实上关于如何去评价一个产生式模型的好坏一直争论到现在。
近年来最受欢迎的的方法是 「协同适应」(co-adaptation)方法:它把优化问题构造成求解两个相互作用演化的非平稳分布的平衡点求解问题[3]。这种方法比较「自然」, 我们可以将它类比为捕食者和被捕食者之间的生态进化过程。
捕食者会逐渐变得聪明, 这样它可以更有效地捕获猎物。然后被捕食者也逐渐变得更聪明以避免被捕食。两种物种相互促进进化, 最终它们都会变得更加聪明。
演化策略通常把优化看作是仿真。用户对模型群体指定一些动力系统, 在仿真过程中的每个时间步上, 根据动力系统的运行规则来更新模型群体。 这些模型可能会相互作用也可能不会。 随着时间的演变, 系统的动态特性可能会使模型群体最终收敛到好的模型上面。
David Ha所著的 《A Visual Guide to Evolution Strategies》 是一部非常好的演化策略在强化学习中应用的教材(其中的「参考文献和延伸阅读」部分非常棒!)
研究现状
监督学习中前馈神经网络和有显式目标函数的问题已经基本解决了(经验之谈, 没有理论保障)。2015年发表的一些重要的突破(批归一化 Batch Norm,残差网络 Resnets,良好初始化 Good Init)现在被广泛使用, 这使得前馈神经网络的训练变得非常容易。
事实上, 数百层的深度网络已经可以把大的分类数据集的训练损失减小到零。关于现代深度神经网络的硬件和算法基础结构,参考 https://arxiv.org/abs/1703.09039。
有证据表明很多 RNN 结构有相同的表达能力, 模型最终效果的差异仅仅是由于一些结构比另一些更加易于训练[4]。
无监督学习的模型输出常常大很多(并不是总是),比如,1024 x 1024 像素的图片, 很长的语音和文本序列。很不幸, 这导致模型更加难以训练。
最近 NVIDA 的工作改进了Wasserstein GAN 使之对很多超参, 比如 BN 的参数、网络结构等不再敏感。模型的稳定性在实践和工业应用中非常重要:稳定性让我们相信它会和我们未来的研究思路和应用相兼容。
总的来讲, 这些成果令人振奋, 因为这证明了我们的产生网络有足够的表达能力来产生正确的图像, 效果的瓶颈在于训练的问题——不幸的是对于神经网络来讲我们很难辩别一个模型表现较差仅仅是因为它的表达能力不够还是我们没有训练到位。
不幸的是, 即使在仅仅考虑可训练性,不考虑泛化的情况下, 强化学习也远远地落在了后面。在有多于一个时间步的环境中, 我们实际是在首先搜索一个模型, 这个模型在推理阶段会最大化获得的奖励。
强化学习比较困难,因为我们要用一个外部的(outer loop)、仅仅依赖角色(agent)见过的数据的优化过程来找到最优的模型, 同时用一个内部的(inner loop)、模型引导的最优控制(optimal control)过程来最大化获得的奖励。
不同环境下,实现同样的算法我们经常得到不同的结果, 因此强化学习文章中报告的结果我们也不能轻易完全相信。
如果我们把强化学习看作一个单纯的优化问题(先不考虑模型的泛化和复杂的任务), 这个问题同样非常棘手。假设现在有一个环境, 只有在一个场景结束时才会有非常稀疏的奖励(例如:保姆照看孩子, 只有在父母回家时她才会得到酬劳)。
因此, 要想估计模型优化过程中任意一处的策略梯度, 我们都要采样指数增长的动作空间(action space)中的样本来获得一些对学习有用的信号。这就像是我们想要使用蒙特卡洛方法关于一个分布计算期望(在所有动作序列上), 而这个分布集中于一个狄拉克函数(dirac delta distribution)(密度函数见下图)。
在建议分布(proposal distribution)和奖励分布(reward distribution)之间几乎没有重叠时, 基于有限样本的蒙特卡洛估计会失效,不管你采了多少样本。

此外, 如果数据布不是平稳的(比如我们采用带有重放缓存 replay buffer 的离策略 off-policy 算法), 数据中的「坏点」会给外部的优化过程(outer loop)提供不稳定的反馈。
不从蒙特卡洛估计的角度, 而从优化的角度来看的话:在没有关于状态空间的任何先验的情况下(比如对于世界环境的理解或者显式地给角色 agent 一些明确的指示), 优化目标函数的形状(optimization landscape)看起来就像「瑞士芝士」——一个个凸的极值(看作小孔)周围都是大面积的平地,这样平坦的「地形」上策略梯度信息几乎没用。这意味着整个模型空间几乎不包含信息(非零的区域几乎没有,学习的信号在整个模型空间里是均匀的)。
如果没有更好的表示方法,我们可能就仅仅是在随机种子附近游走,随机采样一些策略,直到我们幸运地找到一个恰好落在「芝士的洞里」的模型。事实上,这样训练出的模型效果其实很好。这说明强化学习的优化目标函数形状很有可能就是这样子的。
我相信像 Atari 和 MuJoCo 这样的强化学习基准模型并没有真正提高机器学习的能力极限, 虽然从一个单纯优化问题来看它们很有趣。这些模型还只是在一个相对简单的环境中去寻找单一的策略来使模型表现得更好, 没有任何的选择性机制让他们可以泛化。 也就是说, 它们还仅仅是单纯的优化问题, 而不是一个复杂的机器学习问题。
要想解决更高维,更复杂的强化学习问题, 在解决数值优化问题之前,我们必须先考虑模型的泛化和一般的感性认知能力。反之就会愚蠢地浪费计算力和数据(当然这可能会让我们明白仅仅通过暴力计算我们可以做得多好)。
我们要让每个数据点都给强化学习提供训练信息,也需要能够在不用指数增长的数据时就能通过重要性采样(importance sampling)获得非常复杂的问题的梯度。只有在这样的情况下, 我们才能确保通过暴力计算我们可以获得这个问题的解。
最后做一个总结:监督学习的训练比较容易。 无监督学习的训练相对困难但是已经取得了很大的进展。但是对于强化学习,训练还是一个很大的问题。
泛化性能
在这三个问题中, 泛化性能是最深刻的,也是机器学习的核心问题。简单来讲, 泛化性能用来衡量一个在训练集上训练好的模型在测试集上的表现。
泛化问题主要可以分为两大类:
1) 训练数据与测试数据来自于同一个分布(我们使用训练集来学习这个分布)。
2)训练数据与测试数据来自不同的分布(我们要让在训练集上学习的模型在测试集上也表现良好)。
通常我们把(1)称为「弱泛化」,把(2)称为「强泛化」。我们也可以把它们理解为「内插(interpolation)」和「外推(extrapolation)」,或「鲁棒性(robustness)」与「理解(understanding)」。
弱泛化:考虑训练集与测试集数据服从两个类似的分布
如果数据的分布发生了较小的扰动, 模型还能表现得多好?
在「弱泛化」中,我们通常假设训练集和数据集的数据分布是相同的。但是在实际问题中,即使是「大样本」(large sample limit)情况下,二者的分布也总会有些许差异。
这些差异有可能来源于传感器噪声、物体的磨损、周围光照条件的变化(可能摄影者收集测试集数据时恰好是阴天)。对抗样本的出现也可能导致一些不同,对抗的扰动很难被人眼分辨,因此我们可以认为对抗样本也是从相同的分布里采出来的。
因此,实践中把「弱泛化」看作是评估模型在「扰动」的训练集分布上的表现是有用的。

数据分布的扰动也会导致优化目标函数(optimization landscape)的扰动。
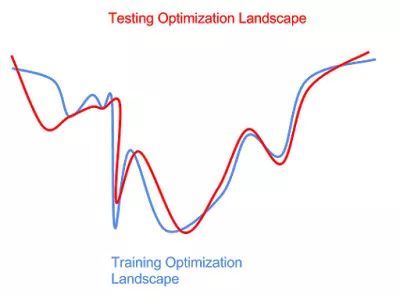
不能事先知道测试数据的分布为我们优化带来了一些困难。如果我们在训练集上优化得过于充分(上图蓝色曲线左边的最低的局部极小点), 我们会得到一个在测试集上并不是最好的模型(红色曲线左边的局部极小点)。 这时, 我们就在训练集上过拟合(overfitting)了, 模型在测试集上没有很好地泛化。
「正则化」包含一切我们用来防止过拟合的手段。我们一点都不知道测试集分布的扰动是什么,所以我们只能在训练集或训练过程中加入噪声,希望这些引入的噪声中会包含测试集上的扰动。随机梯度下降、随机剪结点(dropout)、权值噪声(weight noise)、 激活噪声(activation noise)、 数据增强等都是深度学习中常用的正则化技术。在强化学习中,随机仿真参数(randomizing simulation parameters)会让训练变得更加鲁棒。张驰原在 ICLR2017 的报告中认为正则化是所有的可能「增加训练难度」的方法(而不是传统上认为的「限制模型容量」)。总的来讲,让优化变得困难一些有助于模型的泛化。
对于弱泛化最大的挑战可能就是对抗攻击了。 对抗方法会产生对模型最糟糕的的干扰,在这些扰动下模型会表现得非常差。 我们现在还没有对对抗样本鲁棒的深度学习方法, 但是我感觉这个问题最终会得到解决[5]。
现在有一些利用信息论的工作表明在训练过程中神经网络会明显地经历一个由「记住」数据到」压缩」数据的转换。这种理论正在兴起,虽然仍然有关于这种理论是不是真的有效的讨论。请关注这个理论,这个关于「记忆」和」压缩」的直觉是令人信服的。
强泛化:自然流形
在强泛化范畴,模型是在完全不同的数据分布上进行评估的, 但是数据来自于同一个流形(或数据产生过程)
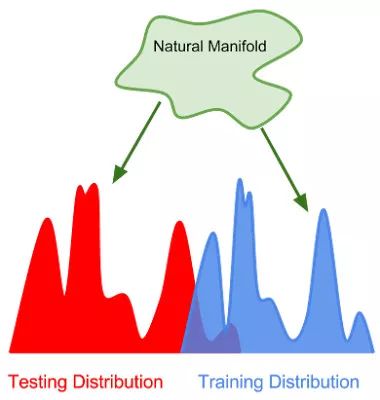
如果测试数据分布于训练数据分布「完全不同」,我们如何来训练一个好的模型呢?实际上这些数据都来自同一个「自然数据流形」(natural data manifold)。只要来源于同一个数据产生过程,训练数据和测试数据仍然含有很多的信息交叠。
强泛化可以看作是模型可以多好地学到这个「超级流形」,训练这个模型只使用了流形上的很小一部分样本。一个图像分类器不需要去发现麦克斯韦方程组——它只需要理解与流形上的数据点相一致的事实。
在 ImageNet 上训练的现代分类器已经基本上可以做到强泛化了。模型已经可以理解基础的元素比如边缘、轮廓以及实体。这也是为什么常常会把这些分类器的权值迁移到其它数据集上来进行少样本学习(few shot learning)和度量学习(metric learning)。
和弱泛化一样,我们可以对抗地采样测试集来让它的数据分布与训练集尽量不同。AlphaGo Zero 是我最喜欢的例子:在测试阶段,它看到的是与它在训练阶段完全不一样的, 来自人类选手的数据。
遗憾的是, 强化学习的研究忽略了强泛化问题。 大部分的基准都基于静态的环境, 没有多少认知的内容(比如人型机器人只知道一些关节的位置可能会带来奖励, 而不知道它的它的世界和它的身体是什么样子的)。
我相信解决强化学习可训练性问题的关键在于解决泛化性。我们的学习系统对世界的理解越多,它就更容易获得学习的信号可能需要更少的样本。这也是为什么说少样本学习(few shot learning)、模仿学习(imitation learning)、学习如何学习(learning to learn)重要的原因了:它们将使我们摆脱采用方差大而有用信息少的暴力求解方式。
我相信要达到更强的泛化,我们要做到两件事:
首先我们需要模型可以从观察和实验中积极推理世界基本规律。符号推理(symbolic reasoning)和因果推理(causal inference)看起来已经是成熟的研究了, 但是对任何一种无监督学习可能都有帮助。
我们的基于模型的机器学习方法(试图去「预测」环境的模型)现在正处于哥白尼革命之前的时期:它们仅仅是肤浅地基于一些统计原理进行内插,而不是提出深刻的,一般性的原理来解释和推断可能在数百万光年以外或很久远的未来的事情。
注意人类不需要对概率论有很好的掌握就能推导出确定性的天体力学,这就产生了一个问题:是否有可能在没有明确的统计框架下进行机器学习和因果推理?
让我们的学习系统更具适应性可以大大降低复杂性。我们需要训练可以在线实时地思考、记忆、学习的模型,而不仅仅是只能静态地预测和行动的模型。
其次, 我们需要把足够多样的数据送给模型来促使它学到更为抽象的表示。
没有这些限制的话,学习本身就是欠定义的,我们能够恰好找到一个好的解的可能性也非常小。 也许如果人类不能站起来看到天空,就不会想要知道为什么星星会以这样奇怪的椭圆形轨迹运行,也就不会获得智慧。
-
AI
+关注
关注
87文章
31209浏览量
269574 -
人工智能
+关注
关注
1792文章
47463浏览量
239122 -
机器学习
+关注
关注
66文章
8428浏览量
132827
原文标题:如何理解和评价机器学习中的表达能力、训练难度和泛化性能
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
zeta在机器学习中的应用 zeta的优缺点分析
傅立叶变换在机器学习中的应用 常见傅立叶变换的误区解析
人工智能工程师高频面试题汇总——机器学习篇

什么是机器学习?通过机器学习方法能解决哪些问题?

eda在机器学习中的应用
分享一些常见的电路

具身智能与机器学习的关系
【「时间序列与机器学习」阅读体验】+ 简单建议
【《大语言模型应用指南》阅读体验】+ 基础知识学习
机器学习中的数据分割方法
机器学习中的数据预处理与特征工程
机器学习在数据分析中的应用
细谈SolidWorks教育版的一些基础知识
晶振电路中电容电阻的一些基本原理和作用解析





 工商网监
工商网监
评论