 如何用深度学习做图像分类?教给你教程和代码
如何用深度学习做图像分类?教给你教程和代码
深度学习推动计算机视觉、自然语言处理等诸多领域的快速发展。在AI大热和人才奇缺的今天,掌握深度学习成为进入AI领域研究和应用的必备技能。来自亚马逊主任科学家李沐将以计算机视觉的经典问题——图像分类为例,手把手地教导大家从0到1搭建深度神经网络模型。对于初学者面临的诸多疑问,提供了从环境设置,数据处理,模型训练,效果调优的完整介绍和代码演示,包括使模型快速获得良好效果的常用方法——迁移学习。让大家有一个全景和基础的了解。
深度学习时代,网络的加深使得对训练数据集规模的依赖更胜以往。学术界较成功的大规模数据集通常围绕基础性的一般认知问题,离有日常有体感的应用场景较远。时尚与人们日常生活息息相关,但行业大量内容仍然依赖人工编辑。通过引入人工智能技术来提升效率,让机器来认知时尚将是一个有趣且有用的课题。
近期,阿里巴巴图像和美团队与香港理工大学纺织及制衣学系联合举办了2018FashionAI全球挑战赛,并在比赛中开放的FashionAI数据集,是首个围绕衣食住行中的“衣”的大规模高质量数据集。该数据集包含八种不同服饰的图片数据,选手们的任务之一就是设计一个算法对图片中服饰的属性做出准确判断。例如其中的裙子类图片,就分为不可见,短裙,中裙,七分裙,九分裙和长裙等总共六种属性。我们可以将其视为经典的图片分类问题,并通过卷积神经网络来解决。
FashionAI数据集中使用的图像数据,全部来源于电商真实场景,刻画了在模型在真实场景应用会遇到的挑战。在FashoinAI数据集上训练的模型,既有学术研究价值,又能在未来实际应用,帮助识别服饰上的专业设计元素。对于计算机视觉研究者来说,不失为一个好的选择。
本文将利用MXNet进行方法讲解。MXNet是一个易安装易上手的开源深度学习工具,它提供了一个python接口gluon,能够让大家很快地搭建起神经网络,并进行高效训练。接下来,我们将以比赛中的裙子任务为例,向大家展示如何用gluon从零开始,设计一个简单而又效果好的卷积神经网络算法。
亚马逊主任科学家 李沐
环境配置
系统配置
对于深度学习训练而言,用GPU加速训练是很重要的。这次竞赛的数据量虽然不算大,但是只用CPU计算可能还是会让一次模型训练花上好几天的时间!因此我们建议大家使用至少一块GPU来进行训练。还没有GPU的同学,可以参考如下两种选择:
根据自己的预算和需求入手(年轻人的第)一块GPU。我们写了一篇GPU购买指南[1],方便大家选购。
为了这次比赛租用亚马逊云的GPU服务器。我们写了一篇AWS的运行教程[2],帮助大家配置自己的云服务器。
配置好了硬件与系统之后,我们需要安装Nvidia提供的CUDA与CUDNN,从而把我们的代码与GPU硬件真正连接起来。这部分的安装比较容易,可以参考这一部分[3]的指导。
如果选择使用亚马逊云服务器,那么我们建议在选择系统镜像时选择Deep Learning AMI,这个镜像把与GPU训练相关的环境(CUDA,CUDNN)都已经配置好了,不需要做其他的配置了。
安装MXNet
配置好了环境之后,我们就可以安装MXNet了。有很多种方式可以安装MXNet,如果要在Linux系统上为python安装GPU版本,只需要执行:

就可以了。如果系统中安装的是CUDA8.0,可以将代码改成对应的mxnet-cu80。如果有同学想要使用其他的语言接口或者是操作系统,或者是自己从源码编译,都可以在官方的安装说明[4]中找到符合自己情况的安装步骤。在接下来的教程中,我们使用MXNet的python接口gluon带领大家上手此次竞赛。
数据处理
数据获取
首先我们在当前目录下新建data文件夹,然后从官网上将热身数据集,训练数据集和测试数据集下载到data中并解压。比赛的数据可以从比赛官网[5]获取,不过同学们要登录天池账号并注册参加比赛之后才能下载。主要的数据集有三个:
fashionAI_attributes_train_20180222.tar是主要训练数据,里面含有八个任务的带标记训练图片。这份教程中我们只选用其中的裙子任务做演示。
fashionAI_attributes_test_a_20180222.tar是预测数据,里面含有八个任务的不带标记训练图片,我们的目的就是训练出模型之后在这份数据上给出分类预测。
warm_up_train_20180201.tar是热身数据,里面含有与训练集不重复的裙子训练集图片,是对训练数据很重要的补充。在进一步运行前,请确认当前的目录结构是这样的:

注意事项:下载好的数据在解压前与解压后会各占用约8G的硬盘空间,在接下来的数据整理中我们会将数据复制为更方便的目录结构,因此请预留足够的硬盘空间。
因为图片数据集通常很大,因此gluon不会一次性将所有图片读入内存,而是在训练过程中不断读取硬盘上的图片文件。请有条件的同学将图片存在SSD硬盘上,这样可以避免数据读取成为瓶颈,从而大幅提高训练速度。
首先,我们在data下新建一个目录train_valid,作为所有整理后数据的目录。

我们选用裙子数据的原因之一,就是热身数据与训练数据中都提供了它的训练图片,从而能让我们能够有更丰富的训练资源。下面我们将分别从热身数据欲训练数据的标记文件中:
读取每张图片的路径和标签
将这张图片按照它的标签放入data/train_valid目录下对应的类别目录中
将前90%的数据用做训练,后10%的数据用作验证
第一步,读取训练图片的路径和标签。
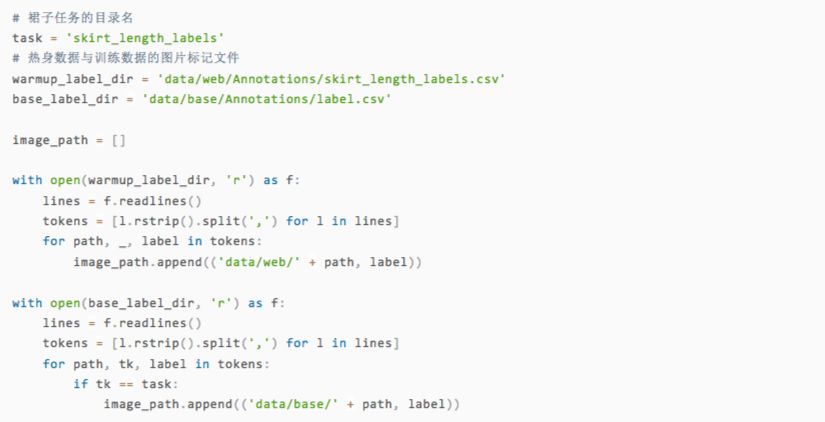
我们来检查一下读入的数据。image_path应该由路径和图片对应标签组成,其中标签是若干个n一个y组成的字符串,字母y出现的位置就是图片对应的类型。


可以看出这张图中的裙子是长裙,对应上官方的说明,可以发现与标记吻合。接下来,我们就准备好训练集和测试集的目录,以及6个裙子类别对应的子目录。
运行后的目录结构如下:
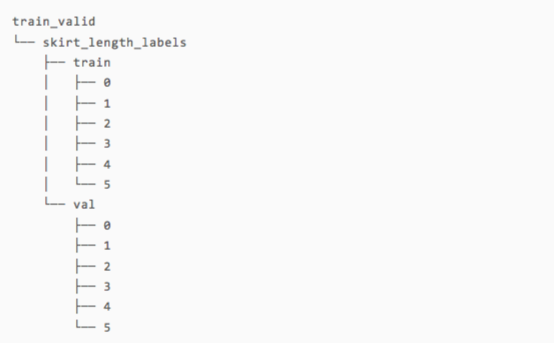
要想处理其他类型的服饰,只需要将task变量指定为对应的服饰类型名称就行了。最后,我们将图片复制到各自对应的目录中。需要注意的是,这里我们刻意随机打乱了图片的顺序,从而防止训练集与测试集切分不均匀的情况出现。

迁移学习
数据准备完毕,接下来我们可以开始着手设计算法了。
服装的识别可以被视作计算机视觉中的经典问题:图片分类。一个典型的例子是ImageNet数据集与ILSVRC竞赛,其中选手们要为分别从属于1000个类别的逾1400万张图片设计算法,将它们准确分类。在服饰属性判别竞赛中,我们可以认为不同属性的服饰从属于不同的类别,于是便能参考ImageNet中的优胜算法来参赛。
在初赛阶段,主办方给每类服饰各提供了约一万张图片用来训练,这样的数据量还不足以让我们从零开始训练一个很棒的深度学习模型。于是我们可以借用迁移学习的想法,从一个在ImageNet数据集上被训练好的模型出发,一点点把它改造成“更懂衣服”的模型。如下图所示,左边的是在ImageNet数据集上训练好的网络,右边的是我们即将用来参赛的网络,这两个网络主体结构一致,因此我们可以将主要的网络权重都复制过来。因为两个网络在输出层的分类个数与含义都不一样,我们需要将输出层重新定义并随机初始化。
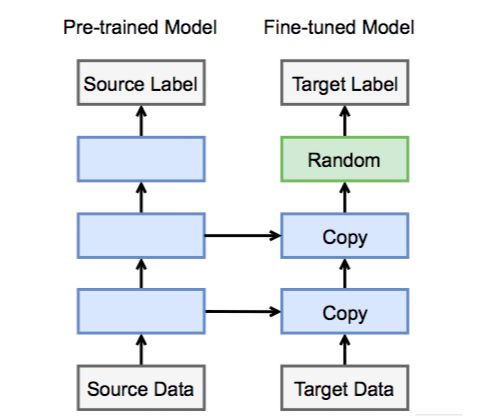
在ImageNet数据集上,大家主要用卷积神经网络,而在过去的几年中也出现了很多不同的网络架构。gluon官方提供了许多不同的预训练好的卷积神经网络模型,我们在这个比赛中选择效果比较好的resnet50_v2模型作为训练的出发点。关于迁移学习更详细的介绍可以参考gluon中文教程中的Fine-tuning:通过微调来迁移学习[6]一节。
首先,我们准备好需要用到的环境。

下面我们可以一句话导入预训练好的resnet50_v2模型。如果是首次导入模型,代码会需要一点时间下载预训练好的模型。

在ImageNet上训练的模型输出是1000维的,我们需要定义一个新的resnet50_v2网络,其中
输出层之前的权重是预训练好的
输出是6维的,且输出层的权重随机初始化
之后,我们可以根据具体的机器环境选择将网络保存在CPU或者是GPU上。
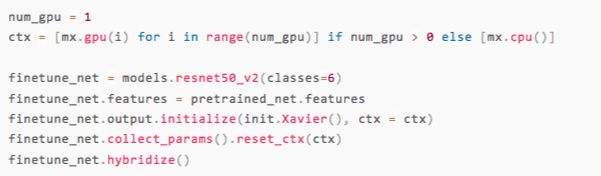
在上面代码中的最后一行我们调用了hybridize,这是gluon的主要特性之一,能将命令式编程构建的模型在执行时把大部分运算转成符号式来执行,这样一方面提高了开发效率,同时也保证了运行速度。关于hybridize更详细的介绍可以参考gluon中文教程中的Hybridize:更快和更好移植[7]一节。
接下来我们定义几个辅助函数,它们分别是
计算AveragePrecision,官方的结果评价标准。
训练集与验证集的图片增广函数。
每轮训练结束后在测试集上评估的函数
关于图片增广更详细的介绍可以参考中文教程中的图片增广[8]一节。


下面我们定义一些训练参数。注意,在迁移学习中,我们一般认为整个网络的参数不需要进行很大地改动,只需要在训练数据上微调,因此我们的学习速率都设为一个比较小的值,比如0.001。
为了方便演示,我们只循环两轮训练,展示过程。

接下来我们可以读入数据了。经过之前的整理,数据可以用接口gluon.data.DataLoader读入

下面我们定义网络的优化算法和损失函数。这次比赛中我们选用随机梯度下降就能得到比较好的效果。分类问题一般用交叉熵作为损失函数,另外,我们除了mAP指标之外也关心模型的准确率。

至此万事俱备,我们可以开始训练了!再次提醒,这里为了快速演示,我们只做两次循环,为了达到更好的训练效果请记得将epochs调大。
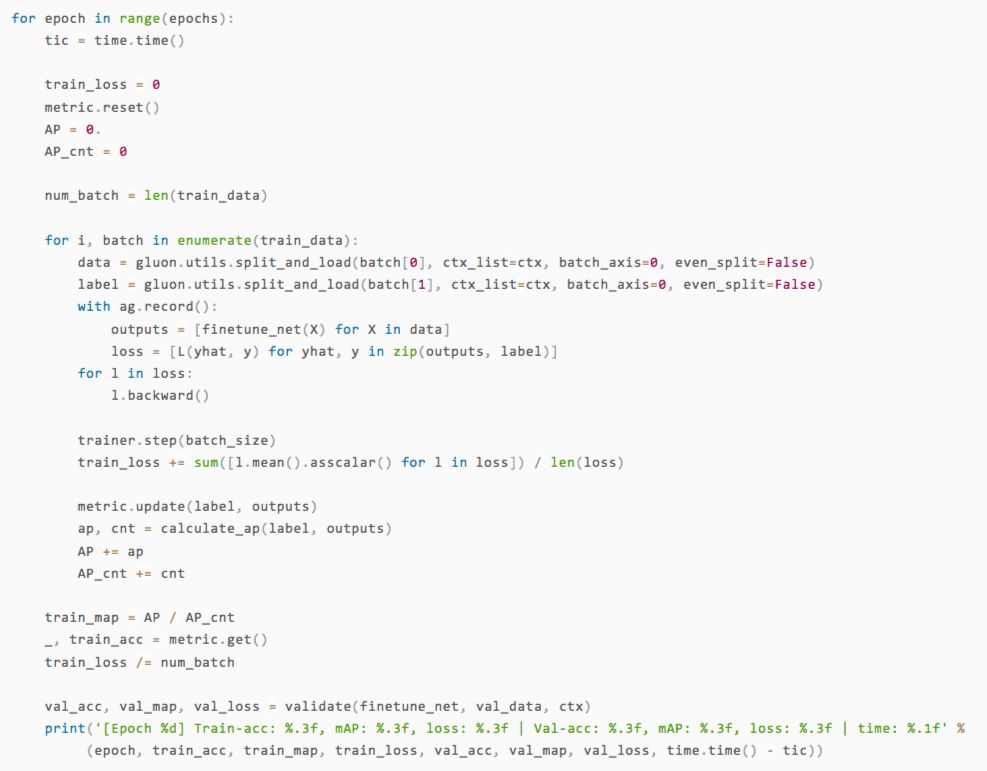

训练结束了,那效果怎么样呢?我们可以直接拿几张测试集的图片出来,用人眼对比一下看看预测的类型是否准确。
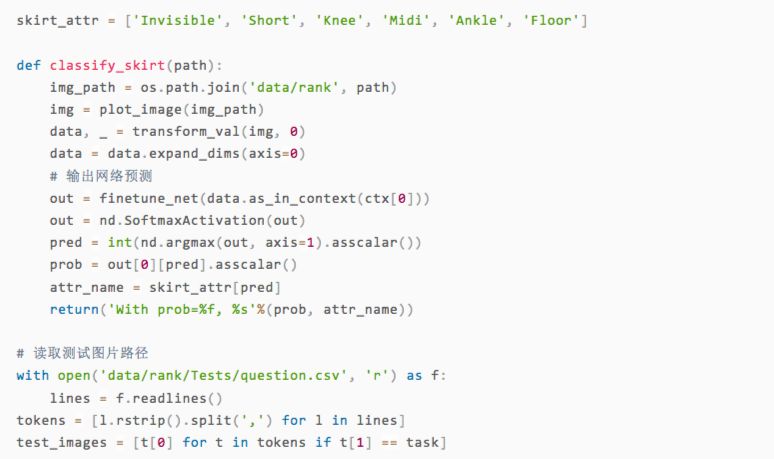


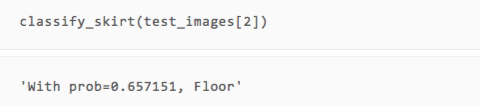
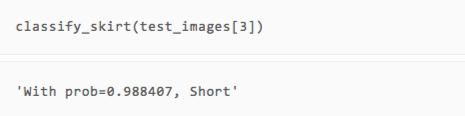
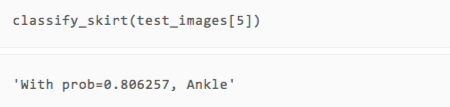
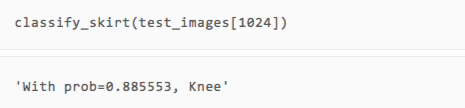
可以看到,虽然只有两轮训练,但我们的模型在展示的几张图片上都做出了正确的预测。
总结
至此,我们展示了从数据整理直到作出预测的样例代码。你可以从这里开始,不断地改进代码,向着更好的结果出发。也建议大家去下载FashoinAI数据集,直接用实践本文中所学习到的技巧。下面我们给出一些可以改进的方向,你可以从他们开始着手:
1.调整参数,比如学习速率,批量大小,训练循环次数等。
参数之间是有互相影响的,比如更小的学习速率可能意味着更多的循环次数。
建议以验证集上的结果来选择参数
不同数据的最佳参数可能是不一样的,建议对每个任务选取相应的最佳参数
2.选择模型。除了ResNet模型之外,gluon还提供很多其他流行的卷积神经网络模型,可以到官方文档根据它们在ImageNet上的表现进行选择。
在计算资源有限的情况下,可以考虑选用占内存更小、计算速度更快的模型。
3.更全面的图片增广可以考虑在训练时加上更多的图片操作。image.CreateAugmenter函数有很多其他的参数,不妨分别试试效果。
在预测时将预测图片做不同的裁剪/微调并分别预测,最后以平均预测值为最后答案,可以得到更稳健的结果。
特别感谢:作者/亚马逊主任科学家 李沐
-
神经网络
+关注
关注
42文章
4777浏览量
100974 -
AI
+关注
关注
87文章
31335浏览量
269695 -
深度学习
+关注
关注
73文章
5511浏览量
121355
原文标题:MXNet 作者李沐:用深度学习做图像分类,教程+代码
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析
什么是深度学习?使用FPGA进行深度学习的好处?
图像分类的方法之深度学习与传统机器学习
基于数据挖掘的医学图像分类方法
一种新的目标分类特征深度学习模型
Xilinx FPGA如何通过深度学习图像分类加速机器学习
深度学习中图像分割的方法和应用
详解深度学习之图像分割
基于深度学习的图像修复模型及实验对比

OpenCV使用深度学习做边缘检测的流程






 工商网监
工商网监
评论