 谷歌推出新的移动框架MobileNetV2提高多种计算机视觉任务
谷歌推出新的移动框架MobileNetV2提高多种计算机视觉任务
当地时间4月3日,谷歌推出了一款新的移动框架MobileNetV2,基于上一代MobileNet,这款模型能显著提高多种计算机视觉任务。
去年我们推出了MobileNetV1,这是一款为移动设备而设计的通用计算机视觉神经网络模型,它有分类、检测等功能。这种可以在个人移动设备上运行深度网络的能力极大地提升了用户体验,不仅能随时随地访问,还非常安全、私密、省电。随着新应用的出现,用户可以与现实世界进行实时交互,同样对更高效的深度网络也有更多的需求。
今天,我们很高兴宣布MobileNetV2已经可以支持下一代移动视觉应用。MobileNetV2在MobileNetV1上做出了重大改进,并推动了目前移动设备的视觉识别技术的发展,包括图像分类、检测和语义分割。MobileNetV2作为TensorFlow-Slim图像分类库的一部分发布,或者您可以在Colaboratory中探索MobileNetV2。另外,您还可以利用Jupyter下载笔记本并进行使用。MobileNetV2也可以作为TF-Hub上的模块使用,预训练的检查点可以在GitHub上找到。
MobileNetV2的创建基于MobileNetV1的思想,使用深度可分离卷积作为高效的构建模块。然而,V2在架构中引入了两种新特征:
图层间的线性瓶颈层
瓶颈层之间的快捷连接
基本结构如图所示:

可以看到,瓶颈对模型的中间输入和输出进行编码,而内层包括了模型能将低级概念(如像素)转换为高级描述符(如图像类别)的能力。最后,剩余的连接和传统一样,快速连接可实现更快的训练速度和更高的准确性。具体细节可以查看论文:MobileNetV2:Inverted Residuals and Linear Bottlenecks:https://arxiv.org/abs/1801.04381。
它与第一代MobileNets相比如何?
总体而言,在整个延迟频谱中,MobileNetV2模型在相同精度下的速度更快。特别的是,新模型所用的操作次数减少了2次,参数减少了30%,在谷歌pixel手机上的速度比V1快了30%~40%,同时达到了更高的准确性。
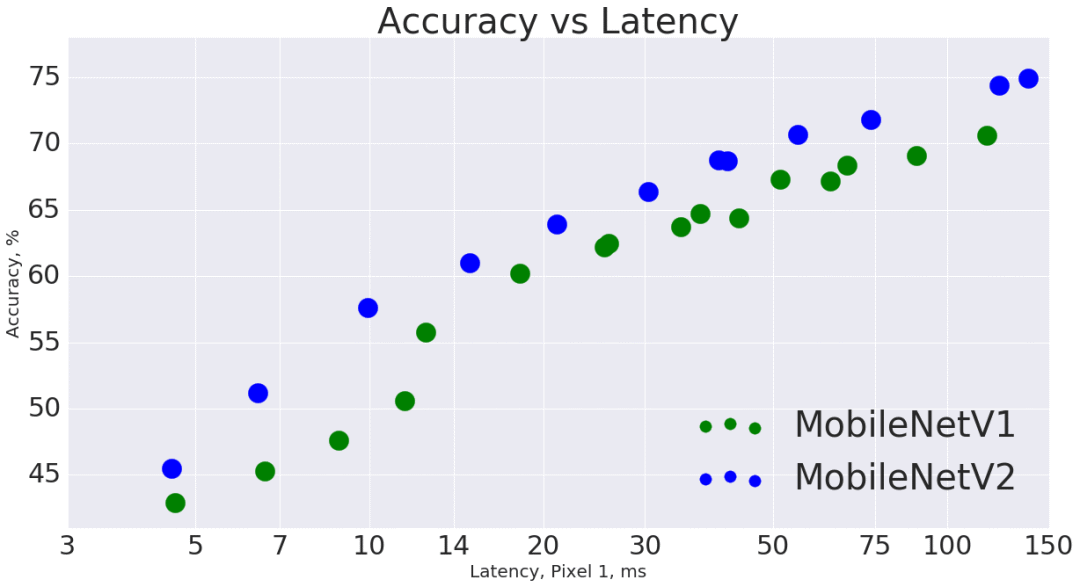
MobileNetV2在目标物体检测和分割时是一个非常高效的特征提取器。例如,当与新发布的SSDLite合作进行物体检测时,新模型在做到与V1同样准确的情况下,速度快了35%。我们已经在TensorFlow目标物体检测API中开源了此模型。

为支持移动设备的语义分割,我们将MobileNetV2当做特征提取器安装在简化版的DeepLabv3上。在语义分割的基准PASCAL VOC 2012中,我们的结果与将V1作为特征提取器实现了相似的性能,但是参数少了5.3倍,在乘加运算上操作次数减少了5.2倍。

由此可见,MobileNetV2作为许多视觉识别任务的基础,是移动设备上高效的模型。我们希望与学术界和开源社区共享,以此帮助更多人的研究和应用发展。
-
谷歌
+关注
关注
27文章
6161浏览量
105285 -
计算机视觉
+关注
关注
8文章
1698浏览量
45966
原文标题:谷歌推出MobileNetV2,为下一代移动设备CV网络而生
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉有哪些优缺点
计算机视觉技术的AI算法模型
计算机视觉的五大技术
计算机视觉的工作原理和应用
计算机视觉与人工智能的关系是什么
计算机视觉与智能感知是干嘛的
计算机视觉和机器视觉区别在哪
深度学习在计算机视觉领域的应用
机器视觉与计算机视觉的区别
计算机视觉的主要研究方向
计算机视觉的十大算法

工业视觉与计算机视觉的区别





 工商网监
工商网监
评论