 一个基于Tensorflow框架的开源Tacotron实现
一个基于Tensorflow框架的开源Tacotron实现
幸运的是近年来基于神经网络架构的深度学习方法崛起,使得原本在传统专业领域门槛极高的TTS应用上更接地气。现在,我们有了新方法Tacotron一种端到端的TTS生成模型。所谓“端到端”就是直接从字符文本合成语音,打破了各个传统组件之间的壁垒,使得我们可以从<文本,声谱>配对的数据集上,完全随机从头开始训练。从Tacotron的论文中我们可以看到,Tacotron模型的合成效果是优于要传统方法的。
本文下面主要内容是github上一个基于Tensorflow框架的开源Tacotron实现,介绍如何快速上手汉语普通话的语音合成。至于模型的技术原理,限于篇幅就不再详细介绍了,有兴趣可以直接阅读论文,本文的宗旨是,对于刚入门的同学能够在自己动手实践中获取及时的结果反馈。
在正文开始之前,笔者假设读者手头已经准备好项目运行的软硬件环境,包括NVIDIA GTX系列显卡及其驱动,能够在控制台上使用Python3引入Tensorflow模块。
关于Tacotron的源代码,我们选择了Keith Ito的个人项目,笔者的汉语语音合成正是基于此源码上修改而成,代码在:https://github.com/begeekmyfriend/tacotron
训练语料库可以在:
http://www.openslr.org/18上下载6.4G大小的THCHS-30,这是由清华大学开放的汉语普通话语料,许可证为Apache License v2.0。
我们可以开始安装运行了。先clone源代码到本地~/tacotron,然后解压THCHS-30数据集到根目录下,如下所示:
~/tacotron
|- data_thchs30
|- data
|- dev
|- lm_phone
|- lm_word
|- README.TXT
|- test
|- train
注意,~/tacotron是默认的路径,之后运行Python程序会直接把~/tacotron作为根目录,如果你的项目根目录不一样,那么你必须修改程序的默认路径参数,否则会出现运行错误。
我们可以深入到:~/tacotron/data_thchs30/data里面去观摩一下,后其中缀为“wav”是语音文件,采样率16KHz,样本宽度16-bit,单声道,内容是时长为10s左右的一段汉语。后缀为“trn”文件为文本标注(transcript),不同语言有着不同的标注方法,比如英语就可以直接用26个字母加上标点符号作为标注,也就是直接使用英文内容本身;韩语由它自己一套字母表,每个字母可以使用Unicode代码作为标注字符;而汉字本身有2~3万个,穷举的话太多,还有很多同音字,所以我们使用汉语拼音作为字符标注是一种可行方案(在此向汉语拼音之父周有光表示敬意)。比如有这么一句:
绿 是 阳春 烟 景 大块 文章 的 底色 四月 的 林 峦 更是 绿 得 鲜活 秀媚 诗意 盎然
用汉语拼音标注为:
lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de5 di3 se4 si4 yue4 de5 lin2 luan2 geng4 shi4 lv4 de5 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
注意到除了拉丁字母的拼音,还有1~5个阿拉伯数字,表示声调(四种声调加上轻声)。
也可以使用音素(声母+韵母)为单元标注:
l v4 sh ix4 ii iang2 ch un1 ii ian1 j ing3 d a4 k uai4 uu un2 zh ang1 d e5 d i3 s e4 s iy4 vv ve4 d e5 l in2 l uan2 g eng4 sh ix4 l v4 d e5 x ian1 h uo2 x iu4 m ei4 sh ix1 ii i4 aa ang4 r an2
根据经验笔者要指出,如果以字符为单位[a-z1-5],其实上述两种标注方法没有本质区别,故我们只要使用汉语拼音标注方案即可。
聪明的读者应该明白了,所谓的<文本,声谱>配对,就是要让机器学会将每一个包括空格和标点在内的字符[a-z1-5 ,.;:],对应到(mel或线性)声谱的某几帧。

接下来进入实际操作阶段。在根目录下运行如下命令:
> python3 preprocess.py --dataset thchs30
这条命令会在根目录下生成training目录,里面存放了每个音频文件的mel频谱和线性频谱(通过短时傅里叶变换STFT而得),后缀为"npy"的文件,用numpy库加载即可得到多个narray数组(可以视为多个特征向量组成的多维矩阵),用作语音的声学特征提取。除此之外还有个train.txt文件,里面基本上就是csv的格式将拼音标注同每个文件的声谱对应起来。
再提醒一遍,我们的tacotron根目录默认是~/tacotron,更改需要改变命令行参数。有了<文本,声谱>配对数据集形式后,我们可以训练了,输入以下命令行:
> nohup python3 train.py --name thchs30 > output.out &
我们使用了nohup命令来屏蔽一切中断信号,同时将Python进程置于后台,这是由于训练过程十分漫长(一般收敛需要10个小时,得到好的效果需要2天),免得网络中断或者终端断开导致Python进程被杀死。训练过程中的输出将会保存在logs-thchs30目录下,可能是这样的:
~/tacotron
|- logs-thchs30
|- model.ckpt-92000.data-00000-of-00001
|- model.ckpt-92000.index
|- model.ckpt-92000.meta
|- step-92000-align.png
|- step-92000-align.wav
|- ...
以上是92K次迭代后保存下来的模型和alignment图,顺便说一下我们不需要关注step-92000-align.wav这个音频文件,这并不是通过模型预测的实际效果,只是在训练中使用了teacher forcing方法,不代表evaluation效果,可以不去管它。
如何判断训练是否达到预期呢?个人经验有两个:一看学习是否收敛;二看损失(loss)低于某个值。由于Tacotron模型本质上是基于编码器解码器模式的seqtoseq模型,所以学习是否收敛可以从编码器序列和解码器序列是否对齐(alignment)判断。
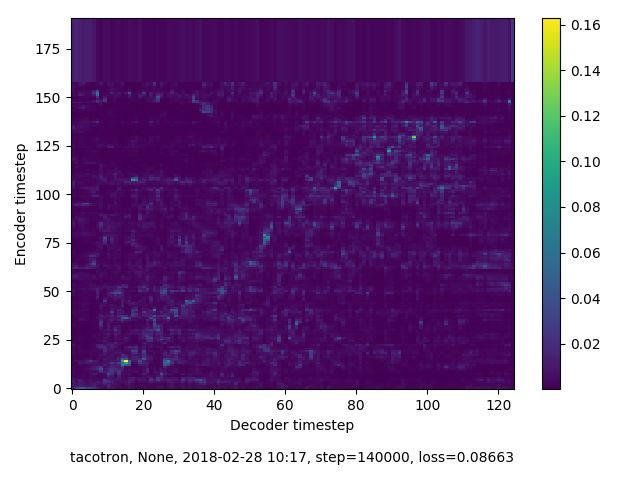
我们放了两张alignment图对比,上图训练了140K次迭代,可以看到没有出现对齐,说明没有收敛。可能的原因很多,比如数据集质量不好,标注不正确等等。下图是92K次迭代,可以看到对齐情况良好,表明基本上可以通过文本来合成出有效的语音。这里要指出,所谓对齐并不是一定要笔直的斜线,它只是代表编码器序列(文本)和解码器序列(声谱)是否对应起来,而且像素点越亮,效果越好。
第二个判断点是loss值,越小表明越接近地真值(ground truth),当然必须在收敛的前提下,loss会趋于稳定。在实际训练中有可能出现loss值很低,但是仍然没出现alignment的情况,这是是无法合成语音的。
当我们从训练日志上看到,loss值低于0.07的时候,基本表示学习收敛并且效果稳定了。可以杀掉后台Python进程,别担心,logs-thchs30目录下已经保存了之前训练过程中产生的模型,你可以从任意时刻生成模型随时恢复继续训练,比如我们需要从92K次迭代生成的模型基础上继续训练,命令行如下:
> nohup python3 train.py --name thchs30 --restore_step 92000 >> output.out &
好了,现在终于到了检验我们录音效果的时刻了!不过我们无法直接输入汉字文本,而是拼音标注,好在有开源项目python-pinyin帮我们搞定:https://github.com/mozillazg/python-pinyin
比如我们想合成一句“每个内容生产者都可以很方便地实现自我价值,更多的人有了微创业的机会。”我们使用python-pinyin输出的拼音标注拷贝到eval.py里,输入命令行:
> python3 eval.py --checkpoint logs-thchs30/model.ckpt-133000
一段时间后,就会在logs-thchs30目录下生成了eval-133000-0.wav,这就是我们想要的结果,一起来听听看吧~
-
语音合成
+关注
关注
2文章
89浏览量
16161 -
GitHub
+关注
关注
3文章
471浏览量
16455
原文标题:基于Tacotron汉语语音合成的开源实践
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络的实现工具与框架
真格基金宣布捐赠开源AI项目vLLM
如何在Tensorflow中实现反卷积
TensorFlow是什么?TensorFlow怎么用?
tensorflow和pytorch哪个更简单?
tensorflow和pytorch哪个好
tensorflow简单的模型训练
keras模型转tensorflow session
如何使用Tensorflow保存或加载模型
TensorFlow的定义和使用方法
TensorFlow与PyTorch深度学习框架的比较与选择
蚂蚁集团发布首个开源金融场景多智能体框架
星动纪元开源人形机器人训练框架Humanoid-Gym
谷歌模型框架是什么软件?谷歌模型框架怎么用?
基于TensorFlow和Keras的图像识别






 工商网监
工商网监
评论