 Linux通用块层之deadline简介及通用块层调度器框架
Linux通用块层之deadline简介及通用块层调度器框架
deadline 简介
deadline 是linux内核通用块层中自带的四个IO电梯调度器之一,其他的三个分别为noop(no operation)、cfq(completely fair queuing)、as(anticipatory scheduling),其中noop是个空的调度器,仅仅直接转发IO请求,不提供排序和合并的功能,适合ssd和nvme等快速存储设备。deadline 调度器由通用块层的maintainer Jens Axboe在2002年首次写出并于同期合并进内核,此后几乎没经过大的修改,历久弥坚,现在已是通用块层单队列的默认IO调度器。deadline相对与其他电梯调度器综合考虑IO请求的吞吐量和时延性,最要体现在以下三个方面:
ü电梯性
ü饥饿性
ü超时性
各个性质的解析后面会具体介绍。测试数据表明,deadline在大多数多线程应用场景和数据库应用场景下表现的性能要优于cfq和as。
通用块层调度器框架
内核通用块层自带四种IO调度器,每个块设备在注册的时候都会为其指定一种调度器,块设备在运行的时候可以通过/sys接口动态调整当前块设备使用的调度器,当然如果你喜欢,也可以自己实现一种满足自己需求的IO调度器,并按照接口标准注册到通用块层。通用块层为了满足调度器的扩充,方便管理各式各样的调度器,提炼出了一个统一的框架,称之为电梯框架。每个调度器只需要需按照框架的标准实现自己调度策略的钩子函数,然后向电梯框架注册自己,后续的块设备就可以使用该注册的调度器。内核中大量使用了设计与实现分离的编程手法,熟悉内核md(multi device)子系统的开发人员应该很了解这种手法,md子系统规范出一个统一的接口,然后各个特性化的raid实现这些接口,并向md层注册自己。电梯调度器框架所包含的接口由内核源码下的include/linux/elevator.h中的struct elevator_ops结构体定义,每个调度器根据自己的特性只需要实现其中部分接口即可。其中最基本的接口有四个:
lelevator_init_fn:调度器初始化接口,注册时被调用,用于初始化调度器的私有数据结构;
lelevator_exit_fn:调度器退出接口,解注册时被调用,用于释放申请的数据结构;
lelevator_add_req_fn:调度器入口函数,用于向调度器中添加IO请求;
lelevator_dispatch_fn:调度器出口函数,用于将调度器内的IO请求派发给设备驱动;
deadline 实现原理
deadline调度器实现的接口有:
static struct elevator_type iosched_deadline = {
.ops.sq = {
.elevator_merge_fn = deadline_merge,
.elevator_merged_fn= deadline_merged_request,
.elevator_merge_req_fn = deadline_merged_requests,
.elevator_dispatch_fn = deadline_dispatch_requests,
.elevator_add_req_fn = deadline_add_request,
.elevator_former_req_fn = elv_rb_former_request,
.elevator_latter_req_fn = elv_rb_latter_request,
.elevator_init_fn = deadline_init_queue,
.elevator_exit_fn = deadline_exit_queue,
},
.elevator_attrs = deadline_attrs,
.elevator_name = "deadline",
.elevator_owner = THIS_MODULE,
};
这些接口在调度器注册的时候告诉调度器框架本调度器对外暴露的方法,除了对外暴露的接口以外,deadline内部还有一些数据结构,用于快速的保存和操作IO请求,如红黑树,链表等。这些数据结构是deadline内部使用的,可以统称为调度器的调度队列,对外不可见,需要调度器的接口才能操作。
struct deadline_data {
struct rb_root sort_list[2];
struct list_head fifo_list[2];
struct request *next_rq[2];
unsigned int batching; /* number of sequential requests made */
unsigned int starved; /* times reads have starved writes */
int fifo_expire[2];
int fifo_batch;
int writes_starved;
int front_merges;
};
从面向对象的角度来理解deadline调度器的话,可以将deadline看作一个封装好的类,上面介绍的接口就是这个类的方法,上面介绍的数据结构就是这个类的数据成员。deadline_init_queue是这个类的构造函数,在给块设备队列分配调度器的时候被调用,用户初始化类的数据成员。deadline_exit_queue相当于析构函数,用于释放调度器实例化时申请的资源。其他的接口包括将IO请求加入到调度器内部数据结构中,将IO请求从调度器内部派发出去,将一个bio合并到调度器内部的一个request中等。deadline内调度队列中最重要的两个成员为:
lstruct rb_root sort_list[2];
lstruct list_head fifo_list[2];
sort_list是两颗红黑树,用于对io请求按起始扇区编号进行排序,deadline的电梯扫描就是基于这两个红黑树进行的,这里有两颗树,一颗读请求树,一颗写请求树,分别作用于读和写。 fifo_list是普通的先进先出链表,也有两个,分别对应读和写。每个IO请求在进入调度器的时候都会根据当前系统时间和超时时间给它赋上一个时间厝,然后根据IO方向添加到读或者写fifo_list,fifo_list头部保存即将超时的IO请求,调度器在派发IO请求的时候会检测fifo_list中是否有已经超时的IO请求,如果有则必须进行派发处理,这就是deadline的字面意思,每个IO请求都有一个死亡线的截至时间,读和写的超时时间由fifo_expire成员定义,默认读为500ms,写为5s,因此读的优先级比写要高,因为读请求大部分情况下是同步的,需要尽快得到满足。
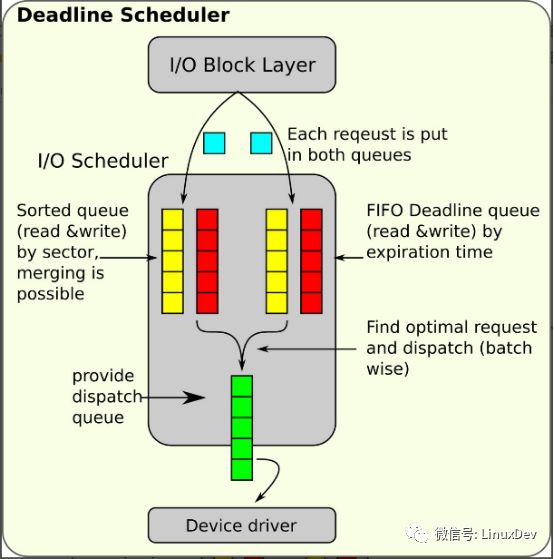
deadline调度器的工作过程就是: 通用块层通过deadline注册的操作接口将IO请求提交给deadline,deadline在收到请求之后根据请求的扇区编号将请求在sort_list中排好序,同时给每个请求添加超时时间厝,并插入到fifo_list尾部。一个IO请求同时挂接在sort_list和fifo_list中。通用块层需要派发IO请求(泻流或者direct IO)的时候也是调用deadline注册的电梯派发接口,deadline在派发一个IO请求时会基于电梯算法综合考虑IO请求是否超时、写饥饿是否触发、是否满足批量条件来决定到底派发哪个IO请求,派发之后会将该IO请求同时从sort_list和fifo_list中删除。deadline服务的整个过程都是由通用块层驱动的,换言之deadline是被动的,在内核中不提供工作队列或工作线程。
deadline IO请求的添加
deadline 的调度队列(数据结构)容纳的是request请求,本系列文章的《Linux通用块层介绍(part1: bio层)》、《Linux通用块层介绍(part2: request层)》从宏观上介绍了bio请求如何转化为request请求并添加到调度器的调度队列中、如何合并进现有的request请求(包括plug 链表中的request和调度队列中的request)。对于deadline来说,IO请求的合并和排序都是在请求添加到deadline 的调度队列中的过程完成的。bio请求进入deadline 调度队列有两条路径:
bio通过deadline_add_request接口添加到调度队列
deadline_add_request接口的参数形式是request,bio在通用块层会申请一个新的request或者合并到plug 链表中的现有的request中,最后调用deadline_add_request添加到调度队列。
/*
* add rq to rbtree and fifo
*/
static void
deadline_add_request(struct request_queue *q, struct request *rq)
{
struct deadline_data *dd = q->elevator->elevator_data;
const int data_dir = rq_data_dir(rq);
deadline_add_rq_rb(dd, rq);
/*
* set expire time and add to fifo list
*/
rq->fifo_time = jiffies + dd->fifo_expire[data_dir];
list_add_tail(&rq->queuelist, &dd->fifo_list[data_dir]);
}
接口很简单,首先判断request的IO方向,根据IO方向通过deadline_add_rq_rb将request添加到读/写红黑树中,request在红黑树中以请求的起始扇区作为节点的key value,可以直接认为红黑树中的request是按扇区增加的方向排好了序。然后给request添加一个超时时间厝,根据IO方向添加到先进先出链表尾部,fifo_list中同一IO方向上的request具有相同的fifo_expire,所以先添加进来的request先超时,每次都是从尾部添加,所以头部的request先超时,这也是fifo_list名字的由来吧。
bio通过deadline_merge*接口合并到调度队列中的request
在《Linux通用块层介绍(part2: request层)》中我们介绍了通用块层的blk_queue_bio接口,其中有如何一段代码:
static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio)
{
...
switch (elv_merge(q, &req, bio)) {
case ELEVATOR_BACK_MERGE:
if (!bio_attempt_back_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_back_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
goto out_unlock;
case ELEVATOR_FRONT_MERGE:
if (!bio_attempt_front_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_front_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
goto out_unlock;
default:
break;
}
...
}
这段代码的意思就是尝试将bio合并到电梯调度队列中现有的request中去,首先调用elv_merge->deadline_merge判断是哪种合并(见《Linux通用块层介绍(part2: request层)》中介绍的合并类型),如果可以合并,则根据合并类型进行相应的合并,bio合并到request的功能由通用块层的bio_attempt_front_merge/bio_attempt_back_merge接口完成。对于deadline IO调度器来说,request在红黑树中是以起始扇区作为key value的,如果是前向合并则会改变合并后的request的起始扇区号,因此bio合并之后还需调用elv_bio_merged->eadline_merged_request来重新更新request在红黑树中的key value和位置。不管是前向合并还是后向合并,都有可能触发进阶合并,最后都会调用一次attempt_front/back_merge->deadline_merged_requests来处理这种进阶合并,过程就是调用deadline_remove_request接口将被合并的request从sort_list和fifo_list中删除,同时更新合并后的request的超时时间。
deadline IO请求的派发
deadline 调度算法的核心思想就蕴含在请求的派发接口中,接口代码比较简洁,逻辑清晰,单次调用只派发一个request请求,调度数据结构记录了派发的上下文,调度时充分权衡了请求的电梯性、饥饿性、超时性。
/*
* deadline_dispatch_requests selects the best request according to
* read/write expire, fifo_batch, etc
*/
static int deadline_dispatch_requests(struct request_queue *q, int force)
{
struct deadline_data *dd = q->elevator->elevator_data;
const int reads = !list_empty(&dd->fifo_list[READ]);
const int writes = !list_empty(&dd->fifo_list[WRITE]);
struct request *rq;
int data_dir;
/*
* batches are currently reads XOR writes
*/
if (dd->next_rq[WRITE])
rq = dd->next_rq[WRITE];
else
rq = dd->next_rq[READ];
if (rq && dd->batching < dd->fifo_batch)
/* we have a next request are still entitled to batch */
goto dispatch_request;
/*
* at this point we are not running a batch. select the appropriate
* data direction (read / write)
*/
if (reads) {
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ]));
if (writes && (dd->starved++ >= dd->writes_starved))
goto dispatch_writes;
data_dir = READ;
goto dispatch_find_request;
}
/*
* there are either no reads or writes have been starved
*/
if (writes) {
dispatch_writes:
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE]));
dd->starved = 0;
data_dir = WRITE;
goto dispatch_find_request;
}
return 0;
dispatch_find_request:
/*
* we are not running a batch, find best request for selected data_dir
*/
if (deadline_check_fifo(dd, data_dir) || !dd->next_rq[data_dir]) {
/*
* A deadline has expired, the last request was in the other
* direction, or we have run out of higher-sectored requests.
* Start again from the request with the earliest expiry time.
*/
rq = rq_entry_fifo(dd->fifo_list[data_dir].next);
} else {
/*
* The last req was the same dir and we have a next request in
* sort order. No expired requests so continue on from here.
*/
rq = dd->next_rq[data_dir];
}
dd->batching = 0;
dispatch_request:
/*
* rq is the selected appropriate request.
*/
dd->batching++;
deadline_move_request(dd, rq);
return 1;
}
deadline的电梯性
电梯调度器最重要的属性就是保持IO请求按适应磁头臂移动的方向去派发请求,从而尽可能的减少IO请求的在磁盘上的寻道时间,提升IO处理能力,类似于电梯移动算法,尽可能减少移动距离来提升运行效率,这就是IO调度器称之为电梯调度器的原因。硬盘的读写原理这篇博文详细介绍了磁盘构造原理以及为什么需要IO调度的原因。deadline的电梯性是通过批量(batching)机制来实现的,前面介绍了IO请求在红黑树中已排好序,deadline每次派发完一个request请求都会将红黑树中排好序的下一个request(如果有)暂存到next_rq成员中,下一次再次调用deadline_dispatch_requests时直接派发next_rq成员中的request,同时按红黑树的顺序更新next_rq。如果一直按照这种思路派发,那么相反IO方向的请求有可能很长时间得不到响应,同一IO方向的请求也有可能出现超时。因此这种完全按红黑树的顺序派发请求的机制必须有个限制,deadline 中的batching和fifo_batch就是起这个作用的,每顺序派发一次,batching加一,如果batching超过了fifo_batch(默认16)就需要考量其他派发因子,如请求超时,fifo_batch设置过大会提升IO请求的吞吐率,增大IO请求的延迟,反之相反。这种同IO方向上的按顺序批次派发我们称只为批量机制,这种批量机制可能提前结束,如IO方向上没有可继续派发的IO请求了。
deadline的饥饿性
deadline的饥饿性说的是写饥饿,写饥饿产生的原因是deadline给予读方向的IO请求更高的优先级,即优先处理读请求,这是因为从实际应用角度来说读请求一般都是同步的,给予读更高的优先级有助于提升用户体验。总是一直优先处理读请求势必会造成写请求的饥饿,为此deadline引入starved和writes_starved成员变量来防止写饥饿,每优先处理一次读请求则计数器starved加一,一旦starved达到阀值writes_starved(默认2)且还有写请求,则下次派发时转向派发写请求。考虑到deadline的批量机制,默认情况下写请求最多让步于16 * 2 = 32个读请求。
deadline的超时性
deadline的饥饿性只会影响IO请求派发的方向,deadline的电梯性和超时性决定派发哪个IO请求。前面已经介绍了每个进入调度器的request都会按照超时先后挂接到fifo_list中,头部的request先超时,尾部的request后超时。在处理完一个批次的request之后,deadline会根据饥饿性确定的IO方向上有没有request超时,如果有超时的request则转向处理该request(fifo_list头部request)。如果还没有request超时,且同方向的next_rq有暂存的request,则继续批量化处理next_rq中的request。如此以来,fifo_batch并不是批量机制的上限,只是给超时和饥饿的request提供处理的机会,如果即没有超时又没有饥饿则当然继续按顺序批量化处理request会提升效率。
-
Linux
+关注
关注
87文章
11355浏览量
210690 -
调度器
+关注
关注
0文章
98浏览量
5305
原文标题:刘正元: Linux 通用块层之DeadLine IO调度器
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式操作系统的通用硬件抽象层设计
EPA功能块及用户层技术研究
嵌入式操作系统的通用硬件抽象层设计

基于块层的组成“bio层”的详细解析
Linux IO系统简介和调度器的工作流程详细概述

Linux块层架构介绍 块层IO流程与块层IO调度器详解
查看linux系统磁盘io情况的办法是什么
SCP基本构建块介绍






 工商网监
工商网监
评论