 视达科用户画像精准定位,大数据为用户提供高质量服务
视达科用户画像精准定位,大数据为用户提供高质量服务
随着互联网逐渐步入大数据时代,运营商和用户的行为不可避免的发生了改变和重塑。最为突出的变化是,大数据使得用户行为“可视化”。利用海量数据精准生成的“用户画像”,可以使营销推广更加的精准、高效,这也成为了视频营销不可或缺的技术手段之一。
相较于传统的用户画像,视达科用户画像基于用户行为轨迹的实时追踪和模型计算生成,用户画像更加细致,更注重细节拆分,进一步提高特征描绘的精准度,能够精准定位不同用户的观影需求,从而提升服务质量。
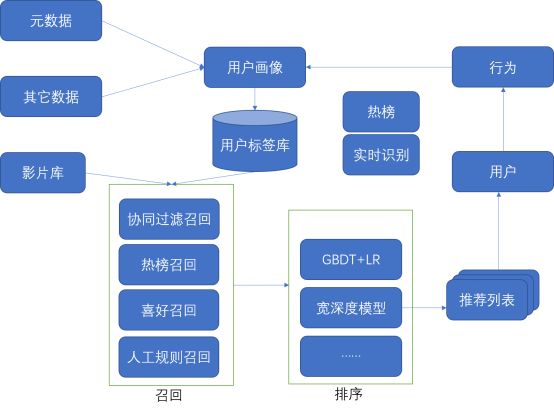
(视达科用户画像系统架构)
在TF-IDF的基础上,考虑了不同行为有不同的权重,且标签会随着时间而变化衰减。为了提高用户标签的准确度,视达科用户画像采用改进的IF-IDF算法计算标签权重。
标签值上的weights字段值,代表着2层意义:这个用户的某标签,其多个标签值之间的重要程度;对于某标签的一个标签值,所有用户之间的重要程度。
例如:用户喜欢的影片类型这个标签来说,会有多个标签值:喜剧片、爱情片、恐怖片、科幻片...某用户A,这标签的几个值:科幻片的权重是0.5,喜剧片的权重是0.3,则说明这用户更喜欢“科幻片”。另一用户B,这标签的几个值:科幻片的权重是0.7,恐怖片的权重是0.1,则说明用户B比用户A更喜欢科幻片。
TF-IDF权重函数:
w(u, t, T) = TF(u, t, T) * IDF(t, T) * degree(u, t, T) * (1 / (1 + decay(T) ) ) + w(u, t, T-1) * (decay(T) / (1 + decay(T)))
一、 多重召回策略,对海量数据进行筛选过滤
如何在海量的视频内容中,筛选出一个模型组成内容库。视达科采用了多种召回策略,综合考虑视频的热度、相似度、动作等,根据用户兴趣标签对视频内容做截断,高效从庞大的内容库中筛选符合用户喜好的一小部分内容。
(1)协同过滤召回
包括基于视频、基于用户的协同过滤推荐,前者依照视频之间的相似性,将相似影片推荐给同一位用户。例如:影片A与影片B相似,用户喜欢影片A,则将影片B也推荐给用户;后者依照用户之间的相似性,将同一影片推荐给相似用户,例如用户A与用户B相似,用户A喜欢影片A,则将影片A也推荐给用户B。
(2)热榜召回
基于视频播放频率,形成视频热播榜单,将热门影片推荐给其他用户。例如:影片A在本时段内播放次数增多,成为热播榜影片,则将影片A推荐给其他用户。
(3)其他召回
除了上述两种常规召回策略,我们还使用了喜好召回、人工规则召回等多重召回策略,把一个海量、无法把握的内容库,变成一个相对小、可以把握的内容库,再进入推荐模型。这样能够有效平衡计算成本和效果。
三、精准排序模型,实现个性化推荐
在用户意图明确时,我们用搜索引擎来解决视频内容库太大的问题,但当用户的意图不明确或者很难用清晰的语义表达,搜索引擎就无能为力。视达科通过精准的排序模型,将筛选后的小型内容库进行重新排序,在用户完全没有需求目标的情况下给出的全局推荐,为其推送个性化的视频内容。
(1)GBDT+LR
GBDT(Gradient Boost Decision Tree)是非线性模型,会建立多棵决策树,但每棵树拟合的是上一棵树的残差。
LR是广义线性模型,速率快,对特征和特征组合要求高,在传统效果预测方面使用广泛。
使用GBDT结合LR进行推荐预测,facebook在2014年就进行了实践,取得了很好的效果。
我们使用用户画像出来的兴趣爱好、年龄、时段、时长等特征与用户实际播放的影片的标签属性、演员、导演等特征作为输入GBDT的输入,GBDT的叶子结点作为LR的输入进行训练。推荐时使用该模型对被推荐用户的召回集影片做预测排序,将靠前的推荐出去。
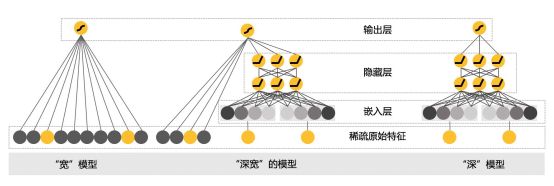
(2)深宽度模型
宽深度(Wide and deep)模型是谷歌2016年发布的,并在Google Play的应用推荐中实际使用,是经过检验的模型。
宽度模型用的是逻辑回归,形式如下:
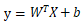 ,其中X是特征向量,W是特征权重,b是偏置。
,其中X是特征向量,W是特征权重,b是偏置。
深度模型通过DNN来提供泛化能力,每个隐层激活方式表示如下:
 其中l表示第l个隐藏层,f是激活函数 。
其中l表示第l个隐藏层,f是激活函数 。
深宽度模型最后的输出过程公式表示就是:
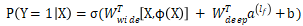
 是sigmoid函数 ,
是sigmoid函数 ,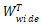
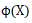 是组合特征,
是组合特征,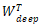 是深度模型输出的权重,
是深度模型输出的权重,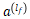
宽深度模型结合传统线性模型和深度模型,能兼顾记忆和归纳。宽度模型能根据历史播放、浏览等行为相关性,推荐关联产品;深度模型用于发现历史行为中出现很少或未出现的特征组合。
四、智能调优,提高推荐准确度
采用智能调优技术,将推荐效果进行评估,系统根据评估结果自动对各种推荐算法进行比例调优,不断自动迭代,实现推荐准确度优化提高的技术。
通过调整各类推荐算法间的分配比例,每次推荐任务会将任务分配给不同的推荐引擎,最终通过结果评估观测哪种推荐引擎推荐效果更好,效果更好的下次自动分配更高比例任务。
基于改进的TF-IDF算法计算标签权重,采取多重召回策略并进行精准排序,利用智能调优技术,对用户画像进行精准刻画,我们得以实时、精确、全面的了解用户诉求,为用户的个性化服务提供及时有效的数据支撑,全方位提升用户体验,进一步提高视频运营服务质量。
企业简介
视达科,初灵信息(股票代码:300250)全资子公司,以“创造一流视频体验”为愿景,通过数据推动决策与运营,助力合作伙伴的视频业务不断增长。
-
互联网
+关注
关注
54文章
11198浏览量
104297 -
大数据
+关注
关注
64文章
8925浏览量
138170 -
用户画像
+关注
关注
0文章
7浏览量
2437
原文标题:【深度】基于视达科用户画像,精准定位用户需求
文章出处:【微信号:iptvott,微信公众号:流媒体网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
UWB模块SKU609:精准定位与多功能融合的卓越之选
广汽集团召开高质量发展大会
制造业升级新引擎:单北斗有源终端赋能精准定位与追踪

精准定位,深度清洁:揭秘工厂清洁机器人的核心技术
如何实现室内精准定位?分享室内精准定位技术及方法
单北斗精准定位,顶坚北斗有源终端赋能行业新应用!
UTB定位技术能不能精准定位
室内精准定位都有哪些亮眼的优势?
室内精准定位的应用范围?室内精准定位的方式有哪些
室内精准定位是什么?室内精准定位的方式有哪些?
云知声入选中国信通院《数字医疗产品及服务高质量发展全景图》
北斗芯片产业的高质量发展之路






 工商网监
工商网监
评论