 概念化的简单强化学习框架让虚拟特技演员做出难度更高的动作
概念化的简单强化学习框架让虚拟特技演员做出难度更高的动作
「运动控制问题已经成为强化学习的基准,而深度强化学习的方法可以很高效的处理控制和运动等问题。然而,使用深度强化学习训练的目标对象也经常会出现不自然动作、异常抖动、步伐不对称以及四肢过度摆动等问题。我们可以将我们的虚拟人物训练的行为表现更加自然吗?」
伯克利 BAIR 实验室介绍了他们对于运动建模的最新研究成果,他们使用动作捕捉片段训练自己的模型。训练中着力减小跟踪误差并采用提前终止的方法来优化训练结果。训练模型最终表现优秀。 详情介绍如下。
虚拟特技演员
我们从计算机图形学研究中获得了启发。在这一领域中基于自然动作的人体仿真模拟已经存在大量的工作,相关研究已经进行了很多年。由于电影视觉效果以及游戏对于动作质量要求很高,多年下来,基于丰富的肢体动作动画已经开发相应控制器,这个控制器可以生成大量针对不同任务和对象的鲁棒性好又自然的动作。这种方法会利用人类洞察力去合并特定任务的控制结构,最终会对训练对象所产生的动作有很强的归纳偏向。这种做法会让控制器更加适应特定的训练对象和任务。比如被设计去生成行走动作的控制器可能会因为缺乏人类洞察力而无法生成更有技巧性的动作。
在本研究中,我们将利用两个领域的综合优势,在使用深度学习模型的同时也生成自然的动作,这动作质量足以匹敌计算机图形学当前最先进的全身动作模拟。我们提出了一个概念化的简单强化学习框架,这个框架让模拟对象通过学习样例动作剪辑来做出难度更高的动作,其中样例动作来自于人类动作捕捉。给出一个技巧的展示,例如旋踢或者后空翻,我们的训练对象在仿真中会以稳健的策略去模仿这一动作。我们的策略所生成的动作与动作捕捉几乎没有区别。
动作模拟
在大多数强化学习基准中,模拟对象都使用简单的模型,这些模型只有一些对真实动作进行粗糙模仿的动作。因此,训练对象也容易学习其中的特异动作从而产生现实世界根本不会有的行为。故该模型利用的现实生物力学模型越真实,就会产生越多的自然行为。但建设高保真的模型非常具有挑战性,且即使在该模型下也有可能会生成不自然行为。
另一种策略就是数据驱动方式,即通过人类动作捕捉来生成自然动作样例。训练对象就可以通过模仿样例动作来产生更加自然的行为。通过模仿运动样例进行仿真的方式在计算机动画制作中存在了很久,最近开始在制作中引入深度强化学习。结果显示训练对象动作的确更加自然,然而这离实现多动作仿真还有很长一段距离。
在本研究中,我们将使用动作模仿任务来训练模型,我们的训练目标就是训练对象最终可以复现一个给定的参考动作。参考动作是以一系列目标姿势表示的(q_0,q_1,…,q_T),其中 q_t 就是目标在t时刻的姿势。奖励函数旨在缩小目标姿势 q^_t 与训练对象姿势 q_t 之间的方差。
虽然在运动模仿上应用了更复杂的方法,但我们发现简单的缩小跟踪误差(以及两个额外的视角的误差)表现的出人意料的好。这个策略是通过训练使用PPO算法优化过的目标实现的。
利用这个框架,我们可以开发出包含大量高挑战性技巧(运动,杂技,武术,舞蹈)的策略。
接着我们比较了现有方法和之前用来模仿动作捕捉剪辑的方法(IGAL)。结果显示我们的方法更加简单,且更好的复现了参考动作。由此得到的策略规避了很多深度强化学习方法的弊端,可以使得训练对象的像人一样行动流畅。
Insights
参考状态初始化
假设虚拟对象正准备做后空翻,它怎样才能知道在半空做一个完整翻转可以获得高奖励呢?由于大多强化学习方法是可回溯的,他们只观察已访问到的状态的奖励。在后空翻这个实验中,虚拟对象必须在知道翻转中的这些状态会获得高奖励之前去观察后空翻的运动轨迹。但是因为后空翻对于起始和落地的条件非常敏感,所以虚拟对象不太可能在随机尝试中划出一条成功的翻转轨迹。为了给虚拟对象提示,我们会把它初始化为参考动作的随机采样状态。所以,虚拟对象有时从地面开始,有时从翻转的中间状态开始。这样就可以让虚拟对象在不知道怎么达到某些状态之前就知道哪些状态可以获得高奖励。
下图就是是否使用RSI训练的策略之间的差别,在训练之前,虚拟对象都会被初始化至一个特定的状态。结果显示,未使用RSI训练的对象没有学会后空翻只学会了向后跳。
提前终止
提前终止对于强化学习研究者来说很重要,他经常被用来提升模仿效率。当虚拟对象处于一种无法成功的状态时,就可以提前终止了,以免继续模仿。这里我们证明了提前终止对结果有很重要的影响。我们依旧考虑后空翻这一动作,在训练的开始阶段,策略非常糟糕,而虚拟对象基本上是不停的失败。当它摔倒后就极难恢复到之前的状态。首次试验成败基本由样本决定,所以虚拟对象大多数时间都是在地上徒劳挣扎。其他的方法论也曾经遭遇过这样的不平衡问题,比如监督学习。当虚拟对象进入无用状态时,就可以终结这次训练来缓解这个问题。ET结合RSI就可以保证数据集中的大部分样本是接近参考轨迹的。没有ET,虚拟对象就学不会空翻,而只会摔倒然后在地上尝试表演这一动作。
其他成果
通过给模型输入不同参考动作,模拟对象最终可以学会24中技巧。
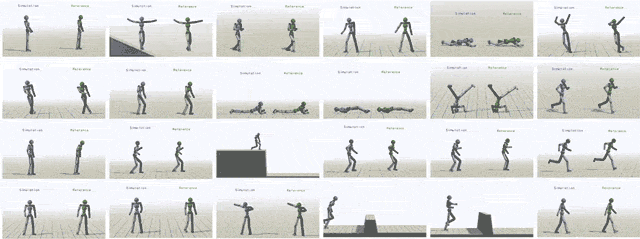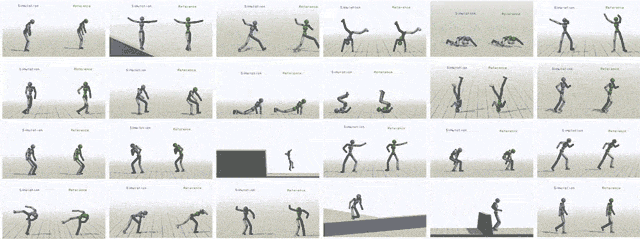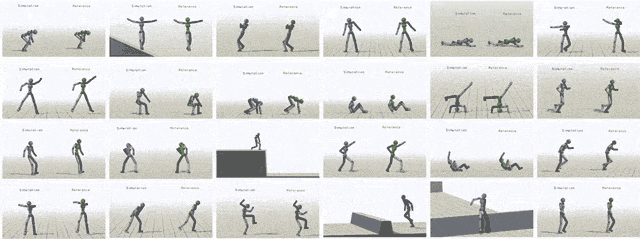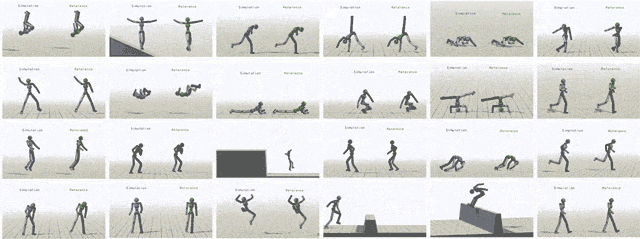
除了模仿动作捕捉片段之外,我们还可以让虚拟对象执行其他任务。比如提一个随机放置的目标,或者向某个目标扔球。
我们还训练的 Atlas 机器人去模仿人类动作捕捉的剪辑。尽管 Atlas 拥有与人不同的形态和质量分布,但它依旧可以复现目标动作。该策略不仅可以模仿参考动作,还可以在模仿过程中抵抗异常扰动。
如果没有动作捕捉剪辑怎么办?假设我们要做霸王龙仿真,由于我们无法获得霸王龙的的动作捕捉影像,我们可以请一个画家去画一些动作,然后用使用画作来训练策略。
为什么只模仿霸王龙呢?我们还可以试试狮子
还有龙
最终结论是一个简单的方法却取得了很好的结果。通过缩小跟踪误差,我们就可以训练处针对不同对象和技巧的策略。我们希望我们的工作可以帮助虚拟对象和机器人习得更多的动态运动技巧。探索通过更常见的资源(如视频)来学会动作模仿是一项激动人心的工作。这样我们就可以克服一些没法进行动作捕捉的场景,比如针对某些动物或杂乱的环境动作捕捉很难实现。
-
机器人
+关注
关注
212文章
29086浏览量
210443 -
人工智能
+关注
关注
1801文章
48279浏览量
243716 -
计算机图形
+关注
关注
0文章
11浏览量
6567
原文标题:学界 | 伯克利 DeepMimic:虚拟特技演员的基本修养
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度强化学习实战
将深度学习和强化学习相结合的深度强化学习DRL
简单随机搜索:无模型强化学习的高效途径

什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

谷歌推出新的基于Tensorflow的强化学习框架,称为Dopamine
机器学习中的无模型强化学习算法及研究综述

模型化深度强化学习应用研究综述

基于深度强化学习的路口单交叉信号控制
虚拟乒乓球手的强化学习模仿训练方法
强化学习的基础知识和6种基本算法解释

什么是强化学习






 工商网监
工商网监
评论