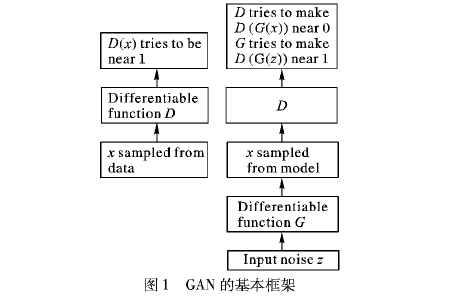
 基于生成对抗网络(GAN)的框架
基于生成对抗网络(GAN)的框架

来自瑞士苏黎世联邦理工学院的研究人员们提出了一种基于生成对抗网络(GAN)的框架,可以以高画质压缩图像,并保证图像尺寸降到最小。以下是论智对原论文的大致报道。

基于深度神经网络的图像压缩系统最近逐渐受到人们的关注。这些系统通常比目前由编码解码器驱动的系统(如BPG、WebP和JPEG2000)表现得好,除了能在自然图像上实现更高的压缩率之外,他们可以很容易地适应特定目标领域,例如立体图像或医学图像,并且可以从压缩版本中直接进行高效地处理和索引。
然而,对于低于像素深度低于0.1bpp的图像来说,这些算法仍会导致严重的画质下降。随着比特率趋近于零,想呈现完整地图像内容就很困难,而且这样会使峰值信噪比(PSNR)或多比例结构相似性(MS-SSIM)等常见指标将变得毫无意义,因为它们更倾向于精确地保留局部(高熵)结构,而不是保持总体的纹理。
为了进一步提升深度图像压缩的质量,开发超越PSNR和MS-SSIM的新指标非常重要。其中重点关注的是对抗损失,最近的成果表明它能捕捉到全局的语义信息和局部纹理,产生强大的生成器,从而通过语义标签映射生成在视觉上吸引人的高分辨率图像。
于是,来自苏黎世联邦理工学院的研究人员们提出并研究了基于生成对抗网络(GAN)的针对极限压缩图像的框架,目标是像素深度低于0.1bpp的图像。他们提出了一个通用性的GAN公式,用于深度图像压缩,可以生成不同程度的图像内容。与先前的图像压缩工作相比,这次的生成器/解码器在全分辨率的图像上工作,并用多尺度鉴别器进行训练。
研究人员对两种操作模式进行了分别研究:
全局生成压缩(GC),保留图像所有内容,同时生成不同尺寸的结构,例如树上的叶子或者某建筑物阳台上的窗户;
选择性生成压缩(SC),只通过语义标签映射生成图像的部分内容,同时以高还原度保留用户指定区域。

上图是研究人员所提出的压缩网络。E代表图像x的编码器,或者作为图像s的语义标签映射。q将潜在的代码w量化为w^。G是生成器,产生解压缩的图像x^,D是用于对抗训练的鉴别器。对于SC,F从s中提取特征,经过二次采样的热图乘以z^以分配空间位。
GC的典型应用场景是带宽受限的区域,在这种情况下用户想尽可能保留完整的图像,但没有足够的位数储存原始像素,无法合成块状或模糊的斑点,只能合成内容。SC可以用于视频场景,如果用户想要完全保留视频中的人物,但是看起来吸引人的合成背景能满足我们的目的,即作为真实的背景。在GC操作模式下,图像被转换成比特流格式,并且用算数编码进行编码。SC需要一个原图的语义或实例标签映射,它们可以从语义或实例分割网络得来(例如PSPNet或Mask R-CNN)。相比于编码的成本,这种图像压缩的开销是少的。另一方面,压缩图像的大小根据语义标签生成的区域按比例减少,通常也会降低储存成本。
经过综合性的研究,在GC方面,研究人员提出的压缩系统生成的图像结果比BPG和基于自动编码器的深度压缩系统更好(BPG是目前最优秀的压缩算法)。尤其是从Cityscapes数据集中选取的街景图片,用户更喜欢本次系统生成的图片,即使BPG使用的位数是我们的两倍。据他们所知,这是第一个证明深度压缩方法由于BPG的研究。
在SC操作模式中,该系统能将图像中保留下来的内容和合成内容无缝衔接,即使被许多物体隔开的场景也很自然。利用这种分区域图像生成的方法,图像的像素深度减少了50%,但是没有明显降低图像质量。
结果对比
下面的表格展示了本文提出的方法的结果和最先进的系统在Cityscapes数据集上的对比:

此次试验结果要比BPG好,即使当BPG使用的bpp数量是我们的两倍也是如此。在本文中,系统在ADE20K数据集和Kodak压缩基准测试上获得了相似的结果。
接着,研究人员用经过预训练的PSPNet来测量保留的语义,结果如下:
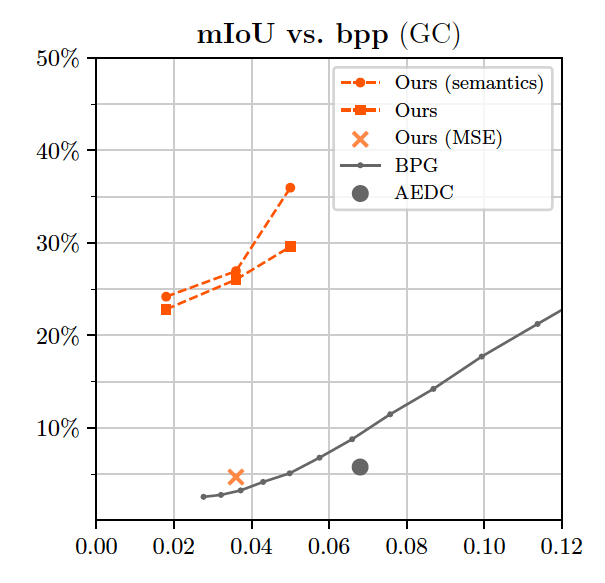
与BPG相比,我们达到了较高的mIoU的值,利用语义进行训练时这个值进一步增加
将所提的方法与其他方法对比。同样一张Kodak Image 13,用本文所提出的方法压缩与BPG、JPEG2000等方法效果非常不同:

在选择性合成方面,该方法可以选择性地保留一部分内容,将剩下的部分重新合成。

左下角的热图显示了合成对象,灰色是合成的部分。同时还显示了每张图的bpp,以及由于选择性生成节省的尺寸
-
神经网络
+关注
关注
42文章
4845浏览量
108326 -
GaN
+关注
关注
21文章
2390浏览量
84861
原文标题:基于GAN的极限图像压缩框架
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
图像生成对抗生成网络gan_GAN生成汽车图像 精选资料推荐
图像生成对抗生成网络

生成对抗网络在计算机视觉领域有什么应用
如何使用生成对抗网络进行信息隐藏方案资料说明
如何使用深度残差生成对抗网络设计医学影像超分辨率算法
必读!生成对抗网络GAN论文TOP 10
基于密集卷积生成对抗网络的图像修复方法
GAN:生成对抗网络 Generative Adversarial Networks
生成对抗网络GAN的七大开放性问题





评论