 Batch,是深度学习中的一个重要概念
Batch,是深度学习中的一个重要概念
批量,即Batch,是深度学习中的一个重要概念。批量通常指两个不同的概念——如果对应的是模型训练方法,那么批量指的是将所有数据处理完以后一次性更新权重或者参数的估计;如果对应的是模型训练中的数据,那么批量通常指的是一次输入供模型计算用的数据量。
基于批量概念的模型训练通常按照如下步骤进行:
初始化参数
重复以下步骤
● 处理所有数据● 更新参数
和批量算法相对应的是递增算法,其步骤如下:
初始化参数
重复以下步骤
● A.处理一个或者一组数据点●B.更新参数。
这里的主要区别是批量算法一次处理所有的数据;而在递增算法中,每处理一个或者数个观测值就要更新一次参数。在后向传播算法中,“处理”对应的具体操作就是计算损失函数的梯度变化曲线。如果是批量算法,则计算平均或者总的损失函数的梯度变化曲线;而如果是递增算法,则计算损失函数仅在对应于该观测值或者数个观测值时的梯度变化曲线。“更新”则是从已有的参数值中减去梯度变化率和学习速率的乘积。
在线学习和离线学习
在深度学习中,另外两个常见的概念是在线学习和离线学习。在离线学习中,所有的数据都可以被反复获取,比如上面的批量学习就是离线学习的一种。而在在线学习中,每个观测值在处理以后会被遗弃,同时得到更新。在线学习永远是递增算法的一种,但是递增算法却既可以离线学习也可以在线学习。
离线学习有如下几个优点:
对于任何固定个数的参数,目标函数都可以直接被计算出来,因此很容易验证模型训练是否在朝着所需要的方向发展。
计算精度可以达到任意合理的程度。
可以使用各种不同的算法来避免出现局部最优的情况
可以采用训练、验证、测试三分法对模型的普适性进行验证
可以计算预测值及其置信区间
在线学习无法实现上述功能,因为数据并没有被存储,不能反复获取,因此对于任何固定的参数集,无法在训练集上计算损失函数,也无法在验证集上计算误差。这就造成在线算法一般来说比离线算法更加复杂和不稳定。但是离线递增算法并没有在线算法的问题,因此有必要理解在线学习和递增算法的区别。
偏移/阈值
在深度学习中,采用sigmoid激活函数的隐藏层或者输出层的神经元通常在计算网络输入时加入一个偏移值,称为Bias。对于线性输出神经元,偏移项就是回归中的截距项。 跟截距项的作用类似,偏移项可以被视为一个由特殊神经元引起的链接权重,这是因为偏移项通常链接到一个取固定单位值的偏移神经元。比如在一个多层感知器神经网络中,某一个神经元的输入变量为N维,那么这个神经元在这个高维空间中根据参数画一个超平面,一边是正值,一边为负值。所使用的参数决定了这个超平面在输入空间的相对位置。如果没有偏移项,这个超平面的位置就被限制住了,必须通过原点;如果多个神经元都需要各自的超平面,那么就严重限制住了模型的灵活性。这就好比一个没有截距项的回归模型,其斜率的估计值在大多数情况下会大大偏移最优估计值,因为生成的拟合曲线必须通过原点。因此,如果缺少偏移项,多层感知器的普适拟合能力就不存在了。 通常来说,每个隐藏层和输出层的神经元都有自己的偏移项。但是如果输入神经已经被等比例转换到一个有限值域中,比如[0,1]区间,那么等第一个隐藏层的神经元已经设置过偏移项以后,后面任何层跟这些具备偏移项的神经元有链接的其他神经元就不需要再额外设置偏移项了。
标准化数据 在机器学习和深度学习中,常常会出现对数据标准化这个动作。那么什么是标准化数据呢?其实这里是用“标准化”这个词代替了几个类似的但又不同的动作。
下面详细讲解三个常见的“标准化”数据处理动作。
(1)重放缩:通常指将一个向量加上或减去一个向量,再乘以或者除以一个常亮。比如将华氏温度转换成摄氏温度就是一个重放缩的过程。
(2)规范化:通常指将一个向量除以其范数,比如采用欧式空间距离,即用向量的方差作为范数来规范化向量。在深度学习中,规范化通常采用极差为范数,即将向量减去最小值,并除以其极差,从而使数值范围在0和1之间。
(3)标准化:通常指将一个向量移除其位置和规模的度量。比如一个服从正态分布的向量,可以减去其均值,并除以其方差来标准化数据,从而获得一个服从标准正态分布的向量。
-
标准化
+关注
关注
1文章
30浏览量
8037 -
深度学习
+关注
关注
73文章
5504浏览量
121224
原文标题:深度学习中常见概念
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习在汽车中的应用
改善深层神经网络--超参数优化、batch正则化和程序框架 学习总结
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析
深度学习介绍
超参数优化是深度学习中的重要组成部分
理解Batch Normalization中Batch所代表具体含义的知识基础
Batch的大小、灾难性遗忘将如何影响学习速率
batch normalization时的一些缺陷
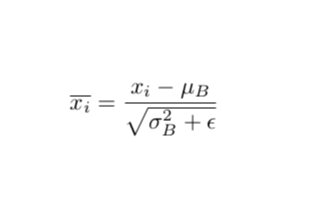





 工商网监
工商网监
评论