 自动驾驶领域的技术变革呼之欲出,深度学习进入“视频学习”时代
自动驾驶领域的技术变革呼之欲出,深度学习进入“视频学习”时代
自动驾驶领域的技术变革呼之欲出。
如果说,自动驾驶大规模落地的痛点在于深度学习的范畴仅限于图像等静态材料,那很快,自动驾驶深度学习的范围将扩展到视频领域。
近日,众安信息技术服务有限公司(以下简称“众安科技”)数据科学实验室的论文"Dense Dilated Network for Few Shot Action Recognition"(《基于密集扩展网络的少样本视频动作识别》)被ICMR(国际多媒体图像分析峰会)录用,这是深度学习在视频分类领域的创新应用,在驾驶行为分析、视频检索等领域有重要的业务价值。
深度学习进入“视频学习”时代
“读图”已经无法满足机器的学习胃口。深度学习是机器学习中一种基于对数据进行表面特征的方法,其概念源于人工神经网络的研究。目前,深度学习的主要素材来源于文字、图片,而随着智能手机等设备的发展,视频沉淀了大量深度学习素材。近年来人工智能、神经网络的发展更是促进了视频的分类、识别的研究。
不过,机器想要学习视频素材绝非易事。一般来说,训练深度神经网络需要大量标记良好的数据。对于机器来说,由于视频动作、视角较多,且视频每秒都包含了20-30帧画面,数据规模较大,机器的标注难度比标注图像复杂很多倍。另一方面,就视频本身而言,虽然不同的视频内容差异很大,但同一类的视频在语义上有着很高的相似性,对于机器学习来说,如何避免“重复劳动”也是摆在现实面前的一道难题。
针对上述难题,众安科技通过在视频多样性中提取高层共有的特性来实现机器学习。
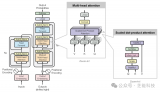
众安科技方面表示,基于机器学习视频的痛点,数据科学实验室研发了一种新颖的神经网络架构来同时捕获局部信息和整体时空信息。具体来看,众安科技采用了扩张卷积网络,在这个网络的不同层之间,使用密集连接的方式组合,由此可以融合每一层的输出,从而学习视频的高级特征。
和其他网络架构相比,众安科技的这款神经网络架构利用每层与之前所有层相连的方式,可以得到从最初局部特征到总体视频的所有特征信息。而每层网络使用了扩张卷积(dilated convolution),相比原始的卷积方式,可以更加充分利用时空信息。因此不需要很深的层数,在少量数据下就可以训练效果较好的网络。
以目前动作类别数、样本数较多的数据库之一UCF101为例,众安科技在此数据库的通用视频数据集上进行了大量实验,在仅有20%的训练数据时(模拟对新任务的快速学习),利用该神经网络架构,机器仍然可以学到每类视频的高层语义特征。
视频深度学习下个落地场景:出行、医疗
视频深度学习有望率先在出行和医疗领域落地。
众安科技研发的这款神经网络架构在实战中也有很高的应用价值,由于该架构只需要少量训练数据就可以促进不同任务之间的迁移学习,帮助系统快速上线,从而减少了大量采集数据和训练过程。
如在车险领域,可以使用该方法对路口监控或行车记录仪等视频进行快速分析,识别碰撞和高危驾驶片段,从而对车主的驾驶行为进行建模,实现车险的自主定价。
此外,在医疗方面,目前人工智能辅助医疗的手段除了CT图片等,还有许多造影等多样的数据有待分析。该方法利用时序信息,可以针对造影进行识别诊断,尤其是对于病例较少的罕见病分析更为高效。
众安科技数据科学实验室认为,该神经网络架构针对出行和医疗领域会有较大的帮助,这也是该团队未来产学研结合的落地方向之一。
-
神经网络
+关注
关注
42文章
4762浏览量
100527 -
机器学习
+关注
关注
66文章
8375浏览量
132398 -
自动驾驶
+关注
关注
783文章
13680浏览量
166115
原文标题:从图像识别走向视频识别,众安科技推出视频深度学习利器
文章出处:【微信号:robot-1hjqr,微信公众号:1号机器人网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
GPU深度学习应用案例
Mobileye端到端自动驾驶解决方案的深度解析

NVIDIA推出全新深度学习框架fVDB
FPGA在自动驾驶领域有哪些优势?
FPGA在自动驾驶领域有哪些应用?
中级自动驾驶架构师应该学习哪些知识
初级自动驾驶架构师应该学习哪些知识
智能驾驶大模型:有望显著提升自动驾驶系统的性能和鲁棒性






 工商网监
工商网监
评论