 一文看懂ARM架构的苹果处理器强在哪里
一文看懂ARM架构的苹果处理器强在哪里
ARM架构
ARM架构过去称作进阶精简指令集机器(Advanced RISC Machine,更早称作:Acorn RISC Machine),是一个32位精简指令集(RISC)处理器架构,其广泛地使用在许多嵌入式系统设计。由于节能的特点,ARM处理器非常适用于移动通讯领域,符合其主要设计目标为低耗电的特性。
在今日,ARM家族占了所有32位嵌入式处理器75%的比例,使它成为占全世界最多数的32位架构之一。ARM处理器可以在很多消费性电子产品上看到,从可携式装置(PDA、移动电话、多媒体播放器、掌上型电子游戏,和计算机)到电脑外设(硬盘、桌上型路由器)甚至在导弹的弹载计算机等军用设施中都有他的存在。在此还有一些基于ARM设计的派生产品,重要产品还包括Marvell的XScale架构和德州仪器的OMAP系列。
ARM 指令集走向64 位元带来的重大改革
苹果在2008年4月23日,冒着极大风险硬着头皮发表初代iPhone的隔年,耗费2亿7,800 万美元,购并了专注开发高效能Power 处理器的PA Semi,组成其处理器研发团队的骨干,然后在2012年9月发表的iPhone 5,其心脏「A6」处理器,终于不再使用来自ARM授权的核心,采用自家的「Swift」微架构(Micro Architecture)。
再以世界上首款抢滩登陆智慧型手机与平板的64位元ARM处理器「A7」(Cyclone微架构)为起点,苹果自家SoC开始逐渐展现压倒ARM Cortex家族(与躺着中枪的Qualcomm自有核心)效能优势,且随着时间演进,差距越拉越开。
让ARM 指令集迈向64 位元的ARMv8-A,并非只有「将整数逻辑暂存器宽度延长到64 位元」和「提供64 位元记忆体定址空间」这么简单,抛弃昔日专注于嵌入式应用的遗产,更加的简洁优雅,更利于打造高效能微架构,引领ARM 荣登高效能的天堂,是这次指令集改版最神圣不可侵犯的绝对使命。
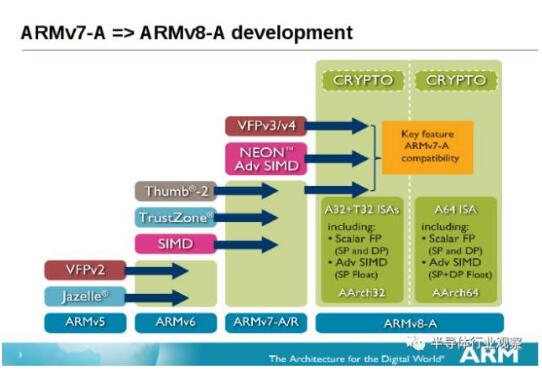
ARMv8-A 修订项目极多,但就笔者的角度,除了取消「加速重建储存CPU 状态的Context Switch 相关机制」(一堆就今日观点实在很小家子气的技术),和简化例外处理与执行特权阶层外,最重大的改革,只有两项:
倍增通用暂存器(GPR)数量,这件事在当年AMD 让x86 迈向64 位元时也发生过,意义重大。
取消涵盖整套指令集的「条件执行」(Conditional Execution),这和前者互为表里,因为总算挤出了珍贵的指令编码空间去增加暂存器数量。
其中又称为「引述式执行」(Predicated Execution,或Guarded Exectuion)的后者,目的在于减少程式中的分支,指令集提供简单扼要的条件执行指令,一次做完所有事情。
ARMv8架构及技术特点
2011年11月,ARM公司发布了新一代处理器架构ARMv8的部分技术细节。这是ARM公司的首款支持64位指令集的处理器架构。由于ARM处理器的授权内核被广泛用于手机等诸多电子产品,故ARMv8架构作为下一代处理器的核心技术而受到普遍关注。ARM将在2012年间推出基于ARMv8架构的处理器内核并开始授权,而面向消费者和企业的样机于2013年由苹果的A7处理器上首次运用。
ARMv8技术特点
ARMv8是在32位ARM架构上进行开发的,将被首先用于对扩展虚拟地址和64位数据处理技术有更高要求的产品领域,如企业应用、高档消费电子产品。
ARMv8架构包含两个执行状态:AArch64和AArch32。AArch64执行状态针对64位处理技术,引入了一个全新指令集A64;而AArch32执行状态将支持现有的ARM指令集。目前的ARMv7架构的主要特性都将在ARMv8架构中得以保留或进一步拓展,如:TrustZone技术、虚拟化技术及NEON advanced SIMD技术,等。
配合ARMv8架构的推出,ARM正在努力确保一个强大的设计生态系统来支持64位指令集。ARM的主要合作伙伴已经能够获得支持ARMv8架构的ARM编译器和快速模型(Fast Model)。在新架构的支持下,对一系列开源操作系统、应用程序和第三方工具的初始开发已经在开展中。通过合作,ARM合作伙伴们共同加速64位生态系统的开发,在许多情况下,这可视为是对现有支持基于ARMv7架构产品的广泛生态系统的自然延伸。
具备64位计算能力的ARMv8架构,将使其合作伙伴有望进入高端服务器市场。然而,很多合作伙伴却缺乏在该市场的技术积累。
ARM架构的苹果处理器强在哪里
苹果从2013年九月发布iPhone 5S配备了自家的A7处理器开始,正式迈进64位处理器的时代,也以此为起点,苹果的A系列处理器开始展现惊世骇俗的性能优势,从2015年六月赶尽杀绝32位应用程序,直到去年苹果的iOS 11系统正式宣布不再支持32位处理器(意思就是iPhone 5S以前的机型不再支持升级系统到iOS 11),更是深具重大意义的里程碑。
高性能之路:让处理器在同一时间处理更多的指令
但64位运算真的有这么神奇吗?当然不是,真正有举足轻重影响的,是ARM升级到64位指令集时,「顺便」带来的革新,特别是铲平了打造高性能构架的重大障碍。
要提高处理器性能,不外乎增加每个时钟周期可处理的指令数:
· 提高时钟周期,对于便携移动设备来说,这几乎是不切实际的选项,提高时钟周期预示着在同样的技术条件下需要更多的能耗。
· 增加同时可以平行处理的指令数量,不再像以前那样每次只能一个萝卜种一个坑,现在你可以同时种多个萝卜到多个坑中。
· 提高管线效率,特别是当发生同时执行的指令,要存取相同储存器而撞车时,需要以「储存器更名机制」为中心的「非循序指令执行」来解决。
前面有提到,电脑有别于计算器的最大差别,在于「条件判断的能力」。
你可将计算机程序的正常执行流程,想像成一个「棋盘」,以一个角落当做起点,对角线的角落作为终点,在棋盘上反复移动,不限制前进或后退。如发生条件判断的分支(Branch),或无条件判断的跳跃(Jump),就会变更指令流,并且中断指令管线的运作,特别是必须先等待条件判断的执行结果,才能决定该分支是否发生的分支,对性能的影响尤其明显。
所以某些指令集就具备了所谓「引述执行(Predicaton)」的能力,包含32位的ARM指令集。一个在一般指令集的简单条件判断(相信各位一定看得懂):
beq ra,label // if(ra)= 0,branch to‘label’ or rb,rb,rc // else move(rb)into rc
改用具备引述执行的条件搬移指令,一行就解决了,避开了分支指令,也无须启动分支预测机制。讲的直白一点,就是把所有相关工作打包起来,一次搞定。
cmovne ra,rb,rc
这对追求高度平行化的指令集,有着莫大的吸引力,所以也不外乎多数超长指令集(VLIW)电脑,都具备这样的能力,包含Intel的IA-64(Itanium),连x86从Pentium Pro开始也有cmov体系指令,只是因种种因素不那么实用,而逐渐边缘化了。
苹果看到的64位大未来
基于未来性,苹果也很早就把重心放在64位性能,根据某些实际的指令排程输出率测试,苹果兼具32/64位兼容性的Ax应用处理器,64位的指令输出量,就几乎是32位的足足两倍,例如每个时钟周期可输出6个64位指令,32位就会腰斩。当然,苹果自家芯片亦具备极度优异的内存性能,A10X走向大型化L2缓存,也隐约透露出些有趣的弦外之音,这就有赖前P.A. Semi团队的功力了。
-
处理器
+关注
关注
68文章
19274浏览量
229735 -
ARM架构
+关注
关注
14文章
177浏览量
36307
发布评论请先 登录
相关推荐
有朋友对苹果的处理器有研究的么
苹果公司为什么要用ARM处理器
深解苹果iphone5 A6处理器:相比A5强在哪里
ARM公版架构 真的是麒麟处理器的槽点吗?

苹果电脑处理器将摒弃英特尔处理器,采用ARM架构处理器
从酷睿11代i5-11300H,看新一代处理器到底强在哪里

苹果凭借M1系列占据ARM架构处理器市场的90%收入





 工商网监
工商网监
评论