 梯度爆炸问题的介绍和如何解决爆炸问题详细概述
梯度爆炸问题的介绍和如何解决爆炸问题详细概述
最近在做一个文本检测的项目,在训练的过程中遇到了很严重的梯度爆炸情况,今天就来谈谈梯度爆炸怎么解决。
首先我们要清楚,为什么会产生梯度爆炸。要知道就目前来说,我们一般都认为深层的神经网络会比浅层的神经网络的表现要好,所以在处理一些较为复杂的任务的时候,人们往往会使用更深层次的神经网络,而现在的大部分神经网络的权重更新都要依靠反向传播。
那么,问题来了。要知道权重的更新的公式是这样的:
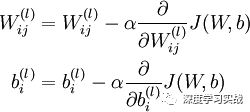
对于每个变量的更新,都要求梯度,也就是求链式偏导。假如,我们想象一下,我们的模型处在一个很陡的陡坡上,那么在求梯度的时候,在网络层上出现了指数型的递增,也就是说,梯度爆炸了。
那么具体上是怎么样的呢?我们来看下面这张图:
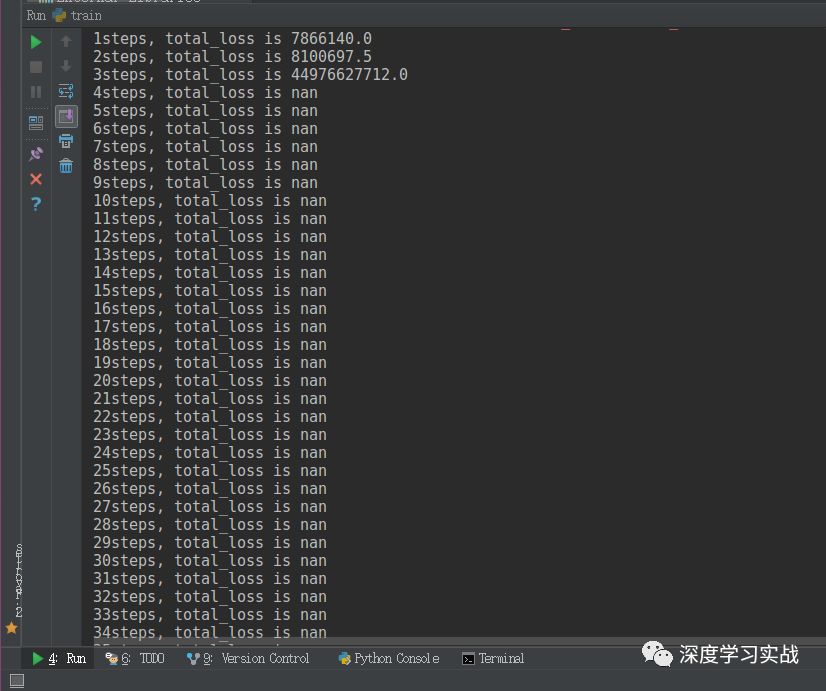
可以看到,上面是我输出的每一步的损失函数的值,损失值在指数型地增加。nan是not a number的意思,它表示无穷大的数或者无意义的数。遇到这个问题的时候,我第一反应是:是不是我学习率太大了。然后我调小了学习率,发现情况有所改善,但是到最后还是出现的梯度爆炸。然后我又思考,会不会是我网络结构有问题啊,为了验证这问题,我把batch size调为了1,固定输入一张图片,发现也是收敛到一定程度也出现了梯度爆炸的情况。那么我可以断定了,是由于网络层数过多导致的梯度爆炸的问题。
问题找到了,那我面临了两个选择:一是降低网络层数,二是做梯度裁剪。考虑到了数据的复杂性,我选择了后者。好,那就来说说梯度裁剪是什么?如何做梯度裁剪。
梯度裁剪
梯度裁剪是指在一个变量计算的梯度过大的情况下,人为地将梯度控制在一定的范围以内。

那直接来看一下代码实现。
optimizer = tf.train.GradientDescentOptimizer(learning_rate)params = tf.trainable_variables()gradients = tf.gradients(loss, params)clipped_gradients, norm = tf.clip_by_global_norm(gradients, clip_norm)optimizer_op = optimizer.apply_gradients(zip(clipped_gradients, params), global_step)
你只要设置里面的clip_norm就可以了,那么设置多少合适呢?
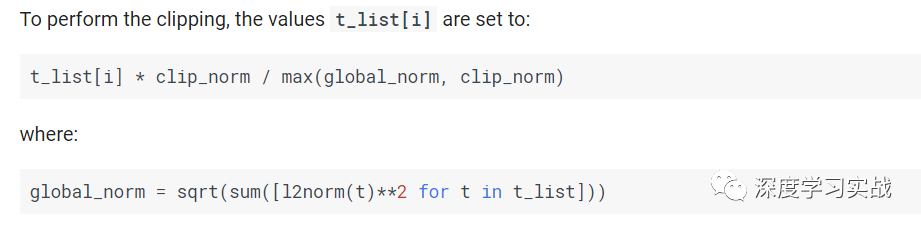
t_list在这里是所有梯度的张量,然后可以看下它是怎么算的。如果global_norm
-
神经网络
+关注
关注
42文章
4773浏览量
100890 -
梯度
+关注
关注
0文章
30浏览量
10331
原文标题:项目实战 | 实战中如何解决梯度爆炸的问题
文章出处:【微信号:gh_a204797f977b,微信公众号:深度学习实战】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电视机显像管为什么能爆炸伤人
格氏锂电池爆炸了!!!爆炸了!!!
冲击、碰撞、爆炸、跌落力测量系统介绍
电解电容爆炸的原因及措施
电解电容爆炸的原因分析
铅酸电池会爆炸吗_铅酸电池爆炸的原因
电动车锂电池爆炸原因_怎么防止电动车锂电池爆炸
深度神经网络的困扰 梯度爆炸与梯度消失






 工商网监
工商网监
评论