 IBM开发“混合精度内存计算”,能耗降低了80倍
IBM开发“混合精度内存计算”,能耗降低了80倍
IBM Research 称,已经开发出了一种内存计算新方法,可以为微软和谷歌寻求的高性能和机器学习应用的硬件加速器提供答案。
在近日 Nature Electronics 期刊上发表的一篇论文中,IBM 研究人员描述了这种新的 “混合精度内存计算” 方法。
IBM 关注传统计算体系结构的不同看法,在这种体系结构中,软件需要在单独的 CPU 和 RAM 单元之间进行数据传输。
据 IBM 称,这种被称为 “冯·诺依曼” 的体系结构设计,为数据分析和机器学习应用制造了一个瓶颈,这些应用需要在处理单元和内存单元之间进行更大的数据传输。传输数据也是一个耗能的过程。
应对这一挑战,IBM 给出的一种方法是模拟相变内存(PCM)芯片,该芯片目前还处于原型阶段,500 万个纳米级 PCM 器件组成 500×2000 交叉阵列。
PCM 的一个关键优势是可以处理大多数密集型数据处理,而无需将数据传输到 CPU 或 GPU,这样以更低的能量开销实现更快速的处理。
IBM 的 PCM 单元将作为 CPU 加速器,就像微软用于加速 Bing 和加强机器学习的 FPGA 芯片一样。
据 IBM 称,研究表明在某些情况下,其 PCM 芯片能够以模拟的方式进行操作,执行计算任务,并提供与 4 位 FPGA 存储器芯片相当的准确度,但能耗降低了 80 倍。
模拟 PCM 硬件并不适合高精度计算。所幸的是,数字型 CPU 和 GPU 是适合的,IBM 认为混合架构可以实现更高性能、更高效率和更高精度的平衡。
这种设计将大部分处理留给内存,然后将较轻的负载交给 CPU 进行一系列的精度修正。
根据 IBM 苏黎世实验室的电气工程师、也是该论文的主要作者 Manuel Le Gallo 称,这种设计有助于云中的认知计算,有助于释放对高性能计算机的访问。
Le Gallo 表示:“凭借我们现在的精确度,我们可以将能耗降低到是使用高精度 GPU 和 CPU 的 1/6。”
“所以我们的想法是,为了应对模拟计算中的不精确性,我们将其与标准处理器结合起来。我们要做的是将大量计算任务转移到 PCM 中,但同时得到最终的结果是精确的。”
这种技术更适合于如数字图像识别等应用,其中误解少数像素并不会妨碍整体识别,此外还有一些医疗应用。
“你可以用低精度完成大量计算——以模拟的方式,PCM 会非常节能——然后使用传统处理器来提高精度。”
对于只有 1 兆字节大小的 IBM 原型内存芯片,现在还处于初期阶段。为了适用于现代数据中心的规模化应用,它需要达到千兆字节的内存量级,分布在数万亿个 PCM 中。
尽管如此,IBM 认为可以通过构建更大规模的 PCM 设备或使其中 PCM 并行运行来实现这一目标。
-
IBM
+关注
关注
3文章
1758浏览量
74725 -
cpu
+关注
关注
68文章
10873浏览量
212054 -
gpu
+关注
关注
28文章
4743浏览量
129006
原文标题:IBM 取得内存计算新突破,AI 训练能耗降低 80 倍
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
为什么隔离ADC的采样频率可以如此显著的提高?但是带宽反而降低了?
虚拟内存对计算机性能的影响
AMD Alveo V80计算加速器网络研讨会
是什么原因降低了INA116的输入阻抗?
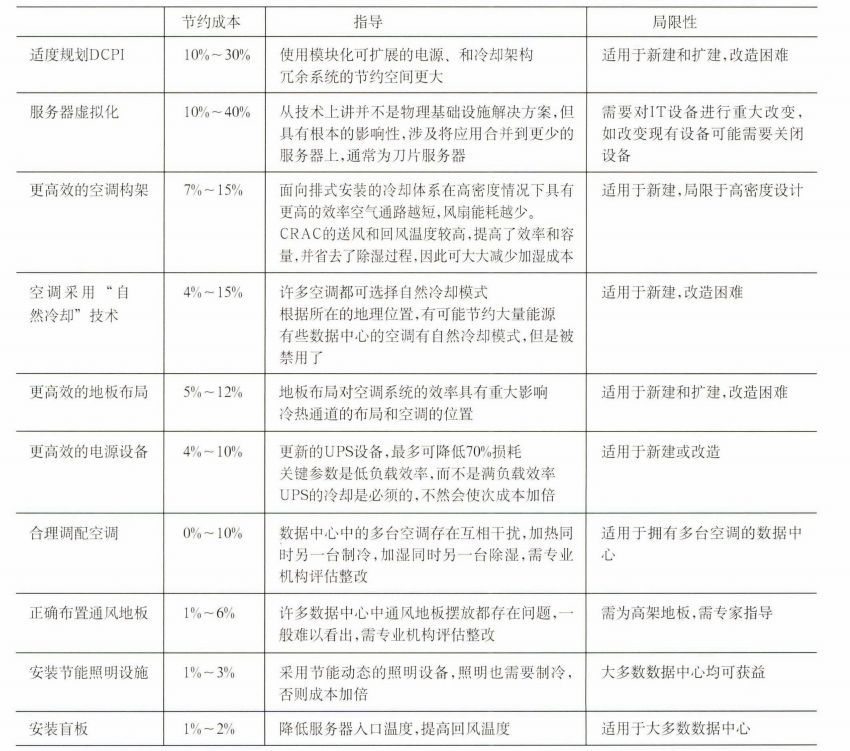
浅析如何降低数据中心电力能耗
IBM与日本AIST携手,共创量子计算新纪元
浅析物联网环境下小麦加工过程能耗监测系统设计
高性能计算集群的能耗优化

借助全新 AMD Alveo™ V80 计算加速卡释放计算能力







 工商网监
工商网监
评论