 meltdown产生的主要原因是CPU的投机执行
meltdown产生的主要原因是CPU的投机执行
1.meltdown的补丁:KPTI(X86和AARCH64)
meltdown产生的主要原因是CPU的投机执行(speculative execution)。本质上是硬件的漏洞,那么我们如何从软件层面进行修复呢?
1.meltdown修复的出发点
在x86中,每个进程都有一张页表,此页表覆盖内核空间+用户空间地址,在用户态执行时,页表中也有内核空间的地址映射,所以才使得用户空间非法访问内核空间地址的代码被投机执行(之后才收到page fault)。那么,修复漏洞最简单有效的软件手段就是让CPU运行在用户态的时候,页表不覆盖内核空间地址。
所以,为了修复漏洞,添加一张页表,使用户态一张页表,内核态一张页表,每次从用户态切换到内核态时也切换页表。但在用户态运行时完全不覆盖内核地址也不可行,因为发生中断、系统调用和异常时,需要切入和换出内核空间,切入和换出接口的地址是内核空间的。所以,用户态的页表覆盖修改为用户态+内核态跳转(trampoline),一旦系统调用发生,接口代码负责立即将页表切换成完整的覆盖用户态+内核态的页表;从系统调用中出来时,再切换回覆盖用户态+内核态跳转的页表。如下图所示:
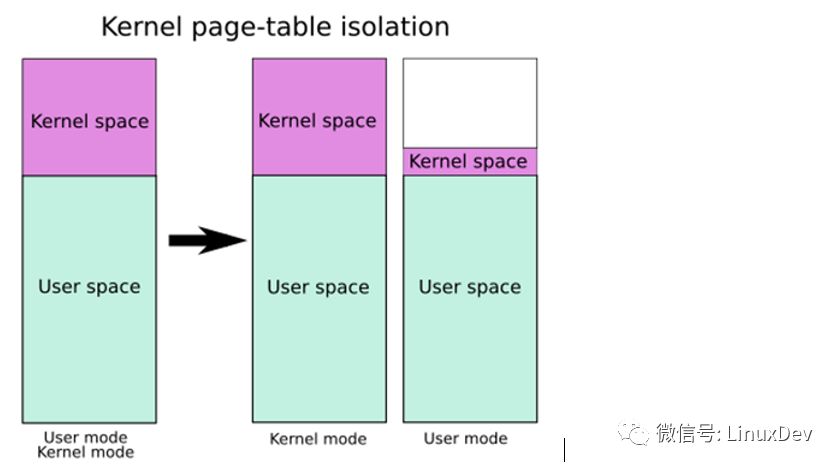
可以看出,修复meldown后,如果应用中系统调用很多,运行时不断的发生中断,每次用户态与内核态切换时就要完成页表的切换,开销会很大,性能也会下降。
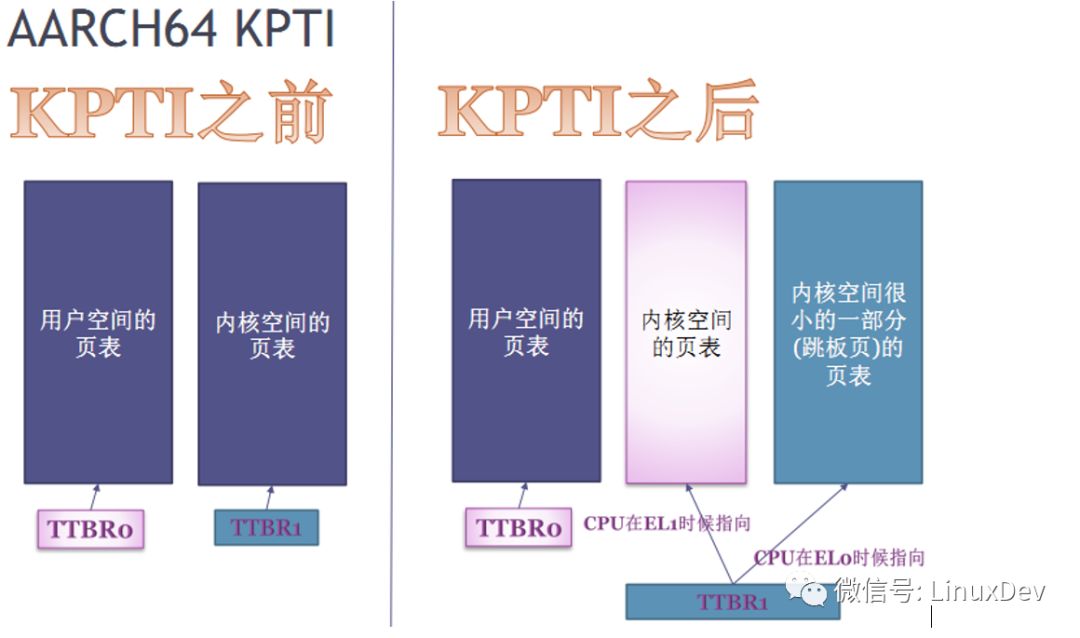
在AARCH64中,本来就是两张页表,硬件上存在TTBR0,TTBR1两个寄存器,TTBR0中填的页表只覆盖用户空间,TTBR1中填的页表只覆盖内核空间。但AARCH64仍然存在meltdown的漏洞,因为TTBR1仍然是覆盖整个内核空间的,在用户态切换到内核空间时仍然可以投机访问到内核空间的所有地址。
所以在AARCH64中修复meltdown漏洞,采取类似x86的方法,让TTBR1中填的页表不覆盖全部的内核地址空间,引入第三张页表(trampoline),也被TTBR1指向,但此页表只指向中断、系统调用、异常切入和换出内核的代码,在切换用户态/内核态时修改TTBR1的指向即可。如下图所示:保证在user模式(EL0)运行时,没有一张页表可以覆盖整个内核空间的地址。
2.内核与用户交界点的安全性问题

i.为什么要检查地址范围?access_ok?
应用程序有无数种方法可以伪造一个指向内核态的指针,所以内核在访问用户数据时存在一系列安全问题。
kernel space在访问user space时,必须判断user space地址的合法性:
2.为什么要做access_ok
比如,将kernel space的一个数据a存放到user space的地址b(*b =a;),但如果不做access_ok的检查,是不能确保地址b一定是user space的,这样就可以通过用一个kernel space的地址伪装成user space地址的方式,将kernel space地址的内容修改掉(*k = a)。这样就有无数种方法将Linux Kernel攻陷,如修改代码逻辑突破root权限等。
有很多漏洞都是诞生在kernel和user的交界点上,所以在交界点上一定要确保地址的合法性及使用copy_from/to_user。
更多安全漏洞参考:
CVE Details
https://www.cvedetails.com/product/47/Linux-Linux-Kernel
CVE-2017-5123漏洞
https://github.com/nongiach/CVE/tree/master/CVE-2017-5123
ii.copy_from/to_user等API

3.为什么要u_k copy
比如,kernel不能直接操作user space的数据,而是操作copy_from_user后的kernel space的副本。如果直接操作user space数据,而user space的程序是多线程的,某个线程就可以在操作user space数据过程中修改这块数据,来实现对内核的攻击。
i.阻止内核访问用户的PAN和SMAP
最保险的方法是让userspace完全不能访问kernel space,但这是不可行的。次安全的方法,比如硬件上提供一个开关,每次在kernel space中访问user space时打开,访问后关闭,即可把kernel space对user space的访问限制在copy_from/to_user这样的API中。ARM中的PAN及x86中的SMAP即为实现此功能的机制。

3.内存碎片避免
什么是碎片?
Internal fragmentation:申请32个字节,但是buddy要给1页-> slab。
External fragmentation : 申请2n连续页,但是系统尽管空闲内存很多,由于非连续,也无法满足。
内存连续的好处:一方面可服务需要连续内存的申请(如CMA本身就需要连续内存);另一方面,利用MMU支持巨页的技术,提高TLB命中率,内存访问遍历Page table的开销被减小。
早期的buddy算法不区分申请内存的类型,如下图红色页面被不可移动的页申请走,如内核中kmalloc申请内存。但周围很多页都是空闲的,并且红色的页面一直不释放,导致红色页面和空闲白色页面无法合并到一起。所以,Linux后期采用将不可移动的页面与可移动的页面分开,将空闲的内存分为可移动(一般为用户程序的内存),可回收(一般为文件系统的缓存),不可移动(一般为kernel的内存)。这样避免了不可移动的与可移动的页面混合在一起,从而使可移动的页面能够merge在一起,提供出更大的连续内存。
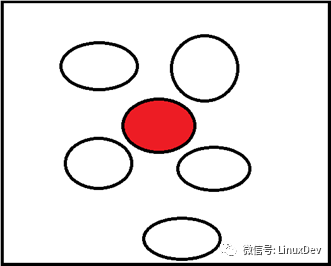
4.分migration type的意义

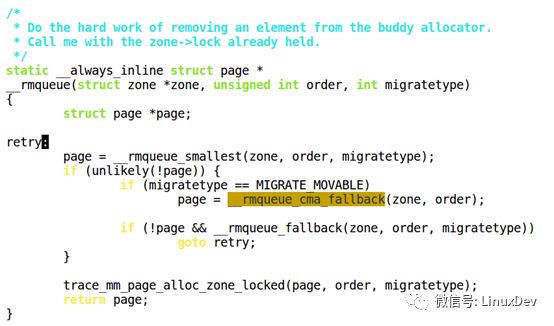
如上图所示,在每个ZONE的空闲内存free list中,分成UNMOVABLE、MOVABLE、RECLAIMABLE类型,分别管理,注意此三种类型的内存一直在动态的变化。比如,Linux刚刚启动时,默认情况下内存都是可移动的,此时有内核模块调用kmalloc申请一页不可移动内存,Linux内核不会只从可移动内存中申请一页作为不可移动的,而是一次性申请出较大一块内存作为不可移动的使用(如210个页面),所以可移动的则不再会被不可移动的所污染。如果210个页面不够用,则再次申请出一块作为不可移动内存使用。同时,不可移动的内存不再使用时也会被释放,释放掉后仍然可再次作为可移动的内存(fallback)。

如上图红色行所示,比如申请不可移动内存,但此时没有,则会先从可回收中去找,可回收中还是找不到则从可移动中去找。
CMA比较特殊,如下图代码所示,可移动的如果申请不到则会从CMA中去找,如果CMA中也申请不到,则会从fallback表中寻找内存(上图中绿色行所示)。
(对应第一次课:CMA内存在不使用时,会服务于可移动页面的内存申请。)
Linux内核中“内存紧凑技术”,类似于磁盘碎片整理。当申请比较大的连续内存时或申请巨页时,内核启用Memory compaction机制,如下图所示:红色部分为被申请掉的内存,白色的部分为空闲内存。Memory compaction将前面的红色部分移动到后面的白色部分,使空闲内存变连续。
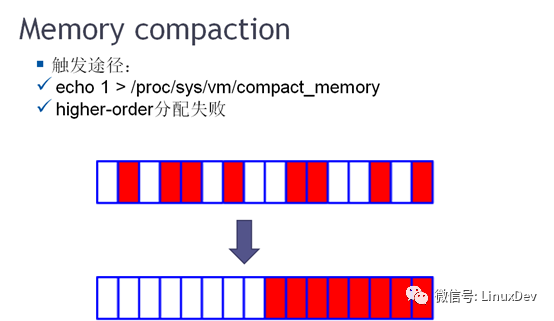
如下图所示,在echo 1 > compact_memory后可以看出低阶的空闲内存变少,而高阶的空闲内存变多。

总结
migrate type是anti-fragmentation:申请内存时归类,把可移动与不可移动的分开,属于一种预防技术。
compaction是de-fragmentation:已经发生碎片,做整理。
-
cpu
+关注
关注
68文章
10860浏览量
211719 -
Linux
+关注
关注
87文章
11303浏览量
209436 -
内存管理
+关注
关注
0文章
168浏览量
14137
原文标题:郝健: Linux内存管理学习笔记-第6节课
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
LED为什么会产生热量?LED发热的几个主要原因是什么?
产生Congestion的主要原因
锡膏焊接后PCBA焊点产生空洞的原因是什么?

放大电路中产生零点漂移的主要原因是什么
焊接质量缺陷产生的主要原因






 工商网监
工商网监
评论