 深度学习解决方案的构建方式及应用
深度学习解决方案的构建方式及应用
摘要:英特尔人工智能产品事业部,数据科学主任Yinyin Liu近日撰写了一篇文章,介绍了深度学习为自然语言处理带来的种种变化。有趣的大趋势是首先产生在CV领域的技术也不断用于NLP,而深度学习解决方案的构建方式也随着时间在进化。
自然语言处理(NLP)是最常见的人工智能的应用方式之一,它通过消费者数字助理、聊天机器人以及财务和法律记录的文本分析等商业应用变得无处不在。随着硬件和软件能力的提升,以及模块化NLP组件的发展,Intel 的技术也使得各种各样的 NLP 应用成为可能。
深度学习性能的上升趋势
近年来,许多 NLP 领域的进展都是由深度学习领域的普遍进步驱动的。深度学习拥有了更强大的计算资源,可以运用更大的数据集,并且在神经网络拓扑结构和训练范式方面有所发展。这些深度学习的进步始于推动计算机视觉应用的改进,但是也让自然语言处理领域极大地获益。
在深度学习的网络层方面,为了使得信号和梯度能够更容易地传递到深度神经网络的每一层,残差结构单元(residual layer)、highway 层(全连接的 highway 网络)以及稠密连接(dense connections)结构应运而生。有了这些网络层,目前最先进的计算机视觉技术通过利用深度学习网络的表示能力得以实现。同时,他们也在许多自然语言处理任务上提高了模型的性能。例如,将稠密连接的循环层用于语言模型(Improving Language Modeling using Densely Connected Recurrent Neural Networks,https://arxiv.org/abs/1707.06130 )。
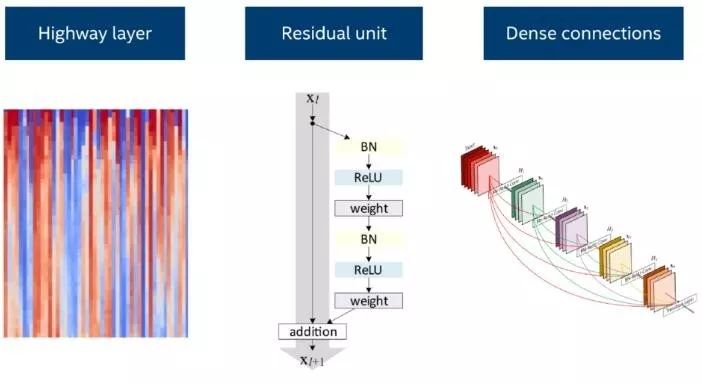
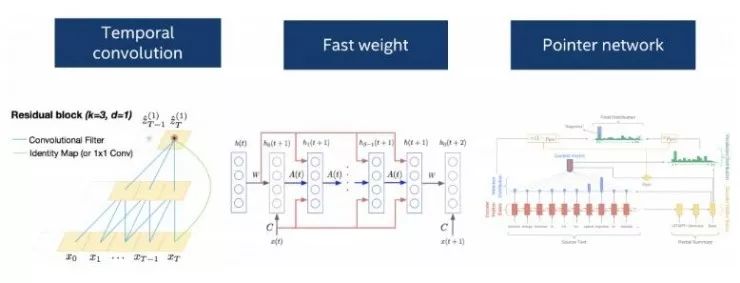
有实证研究中比较了卷积层、循环层或者一种结合了这两种思想的时序卷积层的表现,时序卷积层在一系列的语言数据集上取得了目前最好的效果(Convolutional Sequence to Sequence Learning,https://arxiv.org/abs/1705.03122;An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling,https://arxiv.org/abs/1803.01271)。有这些不同类型的层可供灵活使用,使得开发者能够在处理特定的自然语言处理问题时尝试各种各样的选项。
在深度学习的拓扑结构方面,一个自编码器(auto-encoder)模型可以被改进为一个序列到序列(seq2seq)模型用于处理顺序语言数据。注意力机制(attention mechanism)解决了随着时间的推移,解码网络应该如何对输入的编码做出响应。指针网络(Pointer network),作为注意力模型的一种变体,专门用于在输入序列中寻找词语的位置,它为机器阅读理解和文本摘要提供了一种新的处理机制(Machine Comprehension Using Match-LSTM and Answer Pointer,https://arxiv.org/abs/1608.07905;Get To The Point: Summarization with Pointer-Generator Networks,https://arxiv.org/abs/1704.04368)。通过增加快速权重(fast weights),(Fast Weights to Attend to the Recent Past,https://arxiv.org/abs/1610.06258)短期联想记忆的概念可以和长期序列的学习结合到一起。
在训练范式方面,无监督学习利用训练数据本身和迁移学习技术去构建数据表示,迁移学习可以把学到的将表征用于一个又一个的任务,都是从计算机视觉领域获得启发,推动了自然语言处理技术的进步。
由于这些深度学习模型共用了许多底层的组件,基于深度学习的自然语言处理解决方案可以与计算机视觉和其它人工智能功能的解决方案共用软件和硬件。对于深度学习的通用软件栈的优化也可以为深度学习自然语言处理解决方案的性能带来改善。英特尔的人工智能硬件和软件组合解决方案为这些在英特尔架构的系统上运行的深度学习进展提供了很好的示例。最近,在我们的硬件和对广泛使用的深度学习框架的优化上的工作提供了为在英特尔至强可扩展处理器上运行普遍使用的模型和计算任务优化后的工作性能。英特尔也积极地将他们的这些努力回馈到开放的框架中,这样一来,每个开发者都能很直接地获得这些经验。
为自然语言处理用例构建一个灵活的、模块化的栈
由于基于深度学习的自然语言处理模型通常拥有共用的构建模块(例如:深度学习网络层和深度学习拓扑结构),这让我们在构建自然语言处理用例的基础时拥有了一个全新的视角。一些底层的功能在很多种应用中同时被需要。在一个开放的、灵活的栈中获得基本组件对于解决各种各样的自然语言处理问题是十分恰当的。
相比之下,传统的机器学习或者深度学习的做法都是每一次只考虑某一个特定问题。而如今,由于深度学习社区已经提供了许多有用的基础功能模块,企业中的用户和数据科学家们就可以考虑其它的方面,在学习、构建起基础以后,着眼于如何把它们应用于各种不同的问题。
这种转换的好处主要有这么几点。首先,这些可以复用的组件可以帮助我们逐步构建「结构性资产」。通过重复应用之前已经构建好的东西,我们可以做得更快、评价得更快。其次,这些构建在英特尔的统一软硬件平台上的功能和解决方案可以持续不断地从英特尔未来的开发和改进中受益。另外,用现有的基础设施做实验可以拓展出令人惊喜的新的解决方案或者新的应用,这是更早时候的仅关注于问题本身的思考方式所无法带来的。
一个灵活的、模块化的栈还能使用户可以将传统的自然语言处理方法和基于深度学习的方法结合起来,并为不同的用户群提供不同层次的抽象。许多不同的企业用例表明了自然语言处理和它的基本组件的潜力。下面,我们为您提供了几个例子,但是显然还有很多别的可能性。
主题分析
金融业面临着巨大的知识管理挑战,这是由每天必须处理和理解的文件的数量(太大)所造成的。从一页又一页的文本中提取出诸如「某种特定产品的竞争力」这样的关键的见解是十分困难的。
自然语言处理主题分析技术现在可以被用来快速分析大量的文档,并且识别文档中不同的部分所关联的主题。不同的用户会关注不同的话题,例如:某个公司的价值、竞争力、领导力或者宏观经济学。自然语言处理主题分析让用户能够筛选出特定的感兴趣的主题,并且获得更加浓缩的信息。
为了利用大量未标记的数据,模型可以用内容类似的文本进行预训练,之后这些数据表示可以被迁移至主题分析或者其它附加的任务中。早前的一篇博客介绍了这种解决方案中涉及到的一些方法的概述。为了实现这种方案,从自然语言处理构建模块的角度来说,我们使用了序列到序列(seq2seq)的拓扑结构,长短期记忆网络(LSTM),词嵌入来自迁移学习,而后进行精细调节(fine-tune),还可以与命名实体识别等组件结合在一起。

趋势分析
诸如医疗保健、工业制造、金融业等行业都面临着从大量的文本数据中识别基于时间的趋势的挑战。通过将文本正则化、名词短语分块和抽取、语言模型、语料库的词频-逆文本频率指数(TF-IDF)算法,以及使用词向量的分组等技术,我们可以快速的生成一个解决方案,它可以从一组文档中抽取关键词和重要性估计。接着,随着时间的推移,通过比较这些抽取出来的关键词,我们能够发现有用的趋势,例如:天气变化如何能够造成库存的短缺,或者哪些领域的学术研究随着时间的推移会吸引更多的贡献和注意。
情感分析
情感分析功能通常被用于竞争力分析、沟通策略优化、以及产品或市场分析。一个提供了细粒度的情感分析的解决方案能够为企业用户提供可行的见解。例如:这种更有针对性的情感分析可以发现,关于一个特定商品的评论普遍是对于它的能耗的正面看法以及对它的可靠性的负面看法。对于这种细粒度的情感分析,我们使用了诸如词性标注(POS tagging)、文本正则化、依存分析和词汇扩展等组件。对于不同的领域,相同的的那次可能传递不同的情感,所以允许领域自适应的机制也是十分关键的。
多功能体系架构上灵活的构造模块
当我们看到巨大的自然语言处理市场中的种种规划时,我们应该如何构建解决方案、软件、硬件来利用这些机会并使它们成为可能?在英特尔,我们希望构建能够持续创新和改进的技术,这能够给我们一个用于研究、实践并应用算法的开放的、灵活的平台,这种技术还能够高效地扩展到多种应用程序中,最终形成影响深远的商业见解。
在英特尔人工智能实验室,我们的自然语言处理研究人员和开发者正在构建一个开放的、灵活的自然语言处理组件库,以便为我们的合作伙伴和客户实现多种自然语言处理用例。它使我们能够高效地将我们灵活、可靠高性能的英特尔架构为这些自然语言处理应用、其他的人工智能和先进分析工作流提供了硬件、框架工具和软件层。我们将继续努力优化这些组件,以提高深度学习的能力。
-
英特尔
+关注
关注
61文章
9949浏览量
171694 -
机器视觉
+关注
关注
161文章
4369浏览量
120282 -
深度学习
+关注
关注
73文章
5500浏览量
121113
原文标题:NLP 解决方案是如何被深度学习改写的?
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NPU在深度学习中的应用

AI大模型与深度学习的关系
FPGA做深度学习能走多远?
深度学习中的时间序列分类方法
基于AI深度学习的缺陷检测系统
深度学习在视觉检测中的应用
深度学习与nlp的区别在哪
深度学习与卷积神经网络的应用
TensorFlow与PyTorch深度学习框架的比较与选择
深度学习与传统机器学习的对比
深度解析深度学习下的语义SLAM






 工商网监
工商网监
评论