 多核计算芯片领域国际权威Kunle Olukotun教授:解读用摩尔定律扩展机器学习性能
多核计算芯片领域国际权威Kunle Olukotun教授:解读用摩尔定律扩展机器学习性能
多核计算芯片领域国际权威Kunle Olukotun教授:解读用摩尔定律扩展机器学习性能
4月18日,由鲲云科技协办的2018全球人工智能应用创新峰会在深圳落下帷幕,一场聚焦于人工智能落地应用的高端峰会暂告一段落。而峰会所传达的最新科研成果和前沿思想却在持续发酵。
峰会上,鲲云邀请到了来自全球人工智能各个领域的权威大咖进行个人演讲,分享他们的最新观点。本文所分享的《摩尔定律对机器学习的性能提升》,便是由其中一位大咖——Kunle Olukotun教授带来的。
Kunle Olukotun是斯坦福大学教授,Afara芯片创始人,UltraSPARC T1 芯片架构师。是多核计算芯片领域国际权威。
在他的演讲中,Kunle Olukotun教授介绍了DAWN(数据分析的下一步)项目。 其中包括一系列用于开发机器学习加速器的算法,方法和工具。这些加速器可由具有特定领域知识但没有硬件或机器学习背景的人员开发。通过忽略多核锁定; 低精度算术;并行编程语言和设计空间探索,该项目帮助提供高性能,高生产力和高效率的机器学习实现。
Kunle Olukotun 教授
今天非常高兴跟大家讲一下“用摩尔定律扩展机器学习性能”,我们这个项目的名字叫做下一阶段的数据分析。
机器学习的兴起
最近在影像识别、自然语言处理的进步,都是由机器学习所驱动的。这些应用已经在整个社会产生了非常重大的影响,我们觉得未来可能会出现自动驾驶的汽车,另外有一些更个性化的药物,比如根据基因序列产生出来的。它的药物作用是专门为你的基因所创造出来的。还可以进行医疗的诊断和预测。预测的质量有可能比医生预测的质量更高,所以机器学习有非常大的潜力。
开发高质量的机器学习应用,非常具有挑战性。前景非常好,但要开发应用程序却非常具有挑战性。这需要我们有深入的机器学习的知识、定制的工具以及这些要素如何组合以实现高性能的系统。
DAWN 提案
我们研究的项目包括什么?只要有数据以及某一个领域专业的知识,我们可以使任何人建立起自己的产品级机器学习产品。这也意味着这样的人不需要有机器学习方面博士学位,也没有必要成为一个DB系统的专家,更不需要理解最新的硬件。如果不了解最新硬件,不具备这方面的情况下,机器学习可以怎么样做呢?
20世纪80年代的机器学习
机器学习在20世纪80年代,这里显示的是例如影像识别或者自然语言处理任务的准确度以及它跟你对于机器学习的算法所提供的数据规模的关系。

80年代,当我们第一次讨论机器学习时,大家知道怎么样建立起一个多层神经网络。那个时代,一个普通的算法表现反倒更好,机器学习表现没有那么好。因为机器学习需要更多计算、更加复杂的模型。当然,机器学习有了这些之后,就能超过传统的算法。这就是为什么现在对于机器学习有那么多高期望。
软件 1.0 vs 软件 2.0
换句话说,在说到软件2.0,就是实现的一个概念,软件1.0大家都懂,先写代码,写完之后还要理解某一个领域,再把这个领域的专业知识进行应用。这样就可以做一个算法出来,然后可以把这个算法放到一个系统中。但软件2.0就不一样了。2.0你要做一个模型,就是一个神经网络,然后要把一些数据放到一个神经网络的架构中。软件2.0中最重要的一点是训练的数据量和能够训练一个非常复杂的神经网络的能力。这是要看计算能力了。训练数据就是编程2.0的关键。
训练数据的机遇和挑战
我现在想跟大家说一下训练数据。我们经常说训练数据就是新时代的石油。如果你想要做一些全新的基于神经网络的系统,就需要训练数据,也必须要标签。你要知道这是一个猫,那是一只狗,那是一部车。如果这是很简单的贴标签,那网上随便谁都可以做。但如果要看一个非常复杂的图像,比如诊断一个人有没有患癌,就需要一个专家。
呼吸管主要想法
这种训练数据的获得就更加难。传统训练的另外一个问题是,标签是静态的。但其实你要解决的问题不同,可能把这个标签改变了。但这个训练数据不会进行进化。我们做model时就在想怎么样才能更加容易更加高层次的生成训练数据,让我们更加容易的创造更多的训练数据。我们叫做弱监督,不再给很多标签,而是有更多的噪音输入,给它们进行训练。
整个系统看起来像是这样的,用一个标签功能。比如你看到这个化学物品,可能这个人得了那种病,就可以生成一系列标签功能,再把它跟数据合成。这样就可以去噪音,可以知道哪个标签是比较好用的,哪个标签成功率是90%,哪个标签只有50%的正确率。在基于有概率的标签,就能够做一个噪声感知的判别模型。
我们的目标是希望能够用这个创建应用程序。比如这是一个知识库,我们想做的事情是让这个神经网络的训练变得更加容易,希望让这个训练的数据更加容易。解决方案就是创造另外一个全新的神经网络模型。如果要让我们更加容易的做这个神经网络,让软件2.0做得更加容易,要做更多神经网络的训练,要做更多计算。
机器学习受计算限制
这个机器训练模型是受到计算能力所限制的。百度的工程师说可能需要让计算性能改善100倍。我们怎么做到?比如这个微处理器的改善,这是在过去40年微处理器改善的趋势,我的研究团队参加了这个研究。在这里会看到最顶层的是摩尔定律。每隔18月或者2年处理器性能会翻一番。但这个单线程的性能已经达到一个顶点,主要是因为功耗的问题,因为功耗是有限制的。这就限制了我们进行计算的能力。
当然,这也就影响了随之的表现以及影响了整个行业。这个行业就在一个芯片上多放一些核,就能有效使用能耗,不需要一个芯片把所有的事都做了。我也参与到这个多核的技术研发中。说到能耗和性能时,可以说这个能耗是效率乘性能就等于整个能耗。你就会知道功率是固定的,但你想要做的事情是希望它的性能可以改善,性能改善就可以训练更加复杂的神经网络的模型。
每年机器学习Arxiv论文
但问题是软件的算法也没有在原地踏步。这就给我们看到Arxiv的论文,在过去十几年,关于机器学习的论文的增长,它的增长是比摩尔定律更快。我们看到有多新的想法不断创造出来,但是我们没有办法去执行这些好的想法。

要懂执行这些算法的硬件,我们需要的时间更加长,它比软件算法的改善需要的时间更长。你的Arxiv设计时间大概需要两年。运用在Arxiv的想法在它做完时就已经过时了,因为设计时间那么长。
所以我们必须找一个更加灵活的方法解决这个问题。我们到现在还不知道到底是要让这个通用的机器设计怎么进行设计,而且现在的机器视觉想做的东西可能跟自然语言不一样,跟决策也不一样。比如商业决策或者其他地方的决策,也是不一样的。我们当然想要加快机器学习的速度,希望它们至少能够增加100倍。另外我们也希望让它每瓦特的性能提高,让我们可以在TB甚至PB上的大数据用实时/交互式机器学习。我们也可以开发一个神经架构。
关键问题和方法
现在最重要最核心的问题是怎么样在得到每一瓦类ASIC性能同时又能得到处理器一般的灵活性。这看起来是互相矛盾的,但我觉得有解决方法。我们必须要同时改善算法、编程语言、编译器和硬件架构。
硬件感知的机器学习算法可以改善效率,旧的计算模型也是前人开发出来的,他们要决定人来开发算法,计算是确定性的,因为这个人必须要知道到底怎么样去进行调试。但在软件2.0应用的底层模型是基于神经网络的,他们是根据概率的机器模型,是由数据进行训练的。而且技术很有意思,它们不需要是确定的,也不需要永远都是100%正确的,只需要在统计学上正确就可以了。既然它只需要统计学上正确,那我们有很多机会来改善它的性能,可以使用基础性的计算模型来改善。
方法一:硬件感知机器学习算法,可显著提高效率
现在说说用什么样的方法、算法做这个模型。它是改善或者最小化一个损失模型或者所谓的Loss function。我们有很多数据或者训练的例子,可能有数以十亿计的数据,其中有很多不同的机器与学习的方法,能够做分类或者深度学习等等。我们最重要的进行优化的方法是大家可能都熟悉的随机梯度下降。我们看着一个例子,就可以估计渐变。反过来,也可以看到某一个模型点,然后就可以推到一个训练集的数据点。有很多次迭代,最终得到最优化的模型,可以通过非常小的程序迭代来进行改善。
这个迭代的机器学习是有两种效率需要看。
1、统计学效率,我们到底需要做多少次迭代才能得到最高质量的训练结果
2、硬件效率,每次迭代需要多长时间。我们进行训练的总时间,是越低越好、越少越好,但我们需要进行一个取舍和衡量。
我们是不是要改善一个硬件效率,让统计效率稍微低一点。随机梯度下降法的核心是可能有数十亿个小的步骤。你可以问一个问题,我们能不能够并行做一个事情。这看起来是一个顺序的算法,但可以并行做。怎么样并行做?我在教我的学生时,你在放你的数据时,必须要锁了它,所以做一个已经编码的SGD。但锁了之后发现它做得没有那么好,因为加了更多处理器时会变得更加慢。
另外一件事情是低精度。低精度使用的能量能源会低了,另外存储的内容也会下降。也能够把你所需要的带宽尽量降低。既然你可以同时并行的处理计算更多信息。比如有8字节数据而不是16字节或者32字节的数据,也能增加吞吐量。这是我们经常要做的,比如在TPU、FPGA都在用。它最大的问题是准确性会降低。刚才说要做判断,低准确性是可以的。我们以前觉得训练至少需要16位的准确性。但我们做了一个高准确率低精度,我们能够随着更接近最佳值时把它的渐变变得更加小,我们在逐渐靠近中心。
方法二:编写一个机器学习程序并在所有这些体系结构上高效运行
加速器上可以有更好的效率,我们把机器学习的算法映射到加速器上,可以看到这些机构,它们也有一个编程模式。比如说有集群信息、GPU、FPGA。我们有一个算法,如果想进行有效的训练,需要在硬件的架构上进行实现。我们对于这个算法的描述以及有效的执行之间,是有一条鸿沟的。

因此,我们可不可以编写一个机器学习程序,它能够在这些体系结构上都高效运用。这样就可以填补这个鸿沟了。我们把这个叫做适定于特定情况的语言。现在有AI的应用,把不同领域的语言结合起来,他们专注于这个应用不同的组成部分。比如有一个比较稠密或者稀疏的算法,还有算法中的关系。比如你的重点是不是图像的算法。
总的来说,有各个不同领域的语言,把它结合起来,你怎么样把它组合起来。我们可以使用一个Delite DSL框架,可以在不同领域进行应用。我们有一个Delite DSL框架,把它叫做OptiML。这里有一些绿点,我们希望把它们分成群,有蓝色的X。首先把每一个样本分配到最近的平均值,计算到当前平均值的距离。将每一个群集移动到分配给他们的点的平均值。在这里有一个高层次的描述,可以在多核集群GPU上进行应用,甚至是FPGA。
我们看一下TensorFlow,也是注重于机器学习的,也使用了很多OptiML中使用的想法,它也是高性能适用于不同领域的语言。这里有一个高度抽象化,它比TensorFlow做得更好,而且同样给出描述。我们需要以这个领域为主的语言,就意味着需要不同的架构,所以就是Delite。任何人想开发以特定领域为基础的语言,我们希望这个工作变得更加容易。我们在这当中有一个嵌入在Scala中的DSL和IR。
除此之外,我们在继续改善机器学习,我们看到现在在做什么事情,也要看未来怎么做。怎么使用比较低的精度,稀疏性也是比较有意思的,很多开发者在关注稀疏新的神经网络模型。我们想要这个东西是比较灵活性的,加速性也是可编程的。这是为什么我们在用FPGA,这个架构现在受到越来越多的注意力。
对于分层控制也一样,在控制模板中也定义了哪些程序是要有加速器加速的,所以必须有加速器的范围。另外也需要有方法进行嵌套,怎么样进行合适的嵌套。最终用Spatial语言写了SGD,我们有自定义语言做加速器范围、内存分配,非常明确的内存传输方法和梯度计算。这是非常高层级的,让开发者能很容易的进行定义。
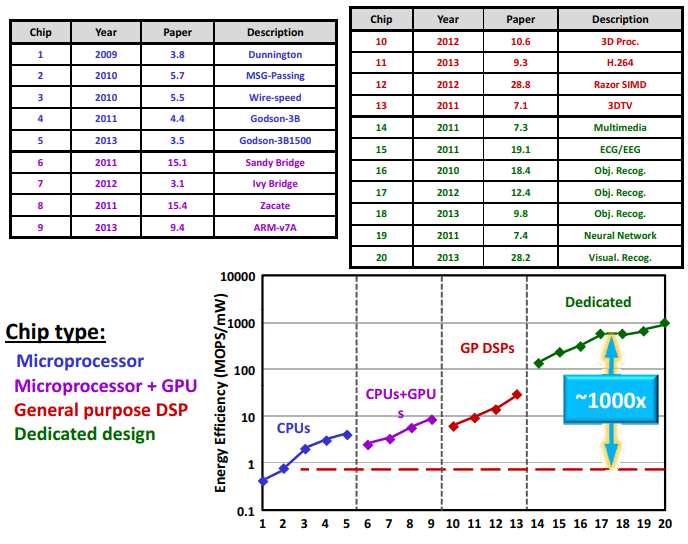
现在的问题是FPGA总的表现怎么样,这张图给大家看到了,在不同的芯片中,全部把它们标准化成28纳米,CPU在左边,能耗效率是1-10。专用的硬件是右边,有效率大概是1000-10000,CPU是最灵活和最能够编译的,专用的硬件是不可以进行编码,但我们会发现专用的硬件比一个GPU的效率高1000倍。GPU比CPU大概好10倍。
但我们看看能不能够在维持FPGA的灵活性的方法,但让编码性更加靠近CPU,能耗更加靠近GPU和FPGA。这就是一个变形模式的可重构架构,这是一个空间表示,可以关注到这个架构,以跟FPGA相似的方式进行理解。这里有PCU和PMU,模式记忆单元和模式计算单元。一个是更看带宽的,带宽能以不同方法配置满足这个程序的需要。另外可以把它们组合到一起来满足你们所需要的空间运用。
我们做了这个之后,如果跟25纳米的这个比较一下,它的性能能够改善95倍,每瓦的能耗能改善77倍。但我们能做很多事,这要看架构到底怎么做,它看起来是怎么样的,怎么样进行一个平衡。性能和能耗的取舍怎么样,还有可编程性的取舍。这是我们最关注的东西和我们现在在做的事。我们非常希望软件定义的硬件架构,能够更加节省能耗,同时也能够更加可编程,比FPGA的表现更加好一些。
总 结
我总结一下,我们的确觉得能一石二鸟,什么都能有,功率能做得很好,性能做得好,可编程性也非常高,但需要做全栈的方法,要综合整合的方法做,需要算法,比如Hogwild和HALP,在语言和编译器方面也需要进行改善,让它们更好的更有效的进行执行。原有的语言是不够的,需要高层级专门面向加速器的抽象语言,才能更好的理解这个域相关的语言和我们所需要的代表加速器的语言。我们需要一个中间的形式,就好象Spatial。
(本文来自鲲云科技微信号,多核计算芯片领域国际权威Kunle Olukotun教授在AI领域声名卓著,希望小编上传后可以分享给更多的工程师,方便大家了解国际AI技术最新发展趋势。)
-
摩尔定律
+关注
关注
4文章
632浏览量
78933 -
算法
+关注
关注
23文章
4599浏览量
92643 -
机器学习
+关注
关注
66文章
8377浏览量
132409 -
AI芯片
+关注
关注
17文章
1859浏览量
34910
发布评论请先 登录
相关推荐
击碎摩尔定律!英伟达和AMD将一年一款新品,均提及HBM和先进封装

奇异摩尔专用DSA加速解决方案重塑人工智能与高性能计算
高算力AI芯片主张“超越摩尔”,Chiplet与先进封装技术迎百家争鸣时代

“自我实现的预言”摩尔定律,如何继续引领创新
封装技术会成为摩尔定律的未来吗?

功能密度定律是否能替代摩尔定律?摩尔定律和功能密度定律比较
摩尔定律的终结:芯片产业的下一个胜者法则是什么?

中国团队公开“Big Chip”架构能终结摩尔定律?
英特尔CEO基辛格:摩尔定律放缓,仍能制造万亿晶体
英特尔CEO基辛格:摩尔定律仍具生命力,且仍在推动创新
后摩尔定律时代,Chiplet落地进展和重点企业布局
六类存内计算技术原理解析





 工商网监
工商网监
评论