 通俗易懂的方式讲解深度学习和机器学习算法
通俗易懂的方式讲解深度学习和机器学习算法
擅长用通俗易懂的方式讲解深度学习和机器学习算法,熟悉Tensorflow,PaddlePaddle等深度学习框架,负责过多个机器学习落地项目,如垃圾评论自动过滤,用户分级精准营销,分布式深度学习平台搭建等,都取了的不错的效果。
本文写作于2017年10月26日
昨天看到某位"大牛"写了篇文章,上了首页推荐,叫做"跟着弦哥学人工智能",看到标题还挺惊喜,毕竟在博客园这个以.net文章为主的技术论坛居然还有大佬愿意写AI方面的文章,于是点击去仔细看了看,发现文风浮夸,恩,没关系,有干货就行,结果翻到最后也没发现啥干货,看到了参考书目,挺有意思的。放个图在这:

当时看到这个参考书目挺迷的,数学类从高中数学推荐到数学专业学生看的数学分析,计算机算法类一上来就推荐大块头的《算法导论》和理论性偏强的《数据挖掘:概念与技术》,认为这样入门的人来说并不合适。看书应当是有阶梯型的,不能一口吃成个大胖子,基于不想"大牛"误人子弟,于是我给出了如下建议:

我的回复很平和,也给出了一些对新手比较友好的建议,并且有6个人支持我,想想算了,然而,今天,在首页中又看到了这位"大牛"在博文骂我是喷子:
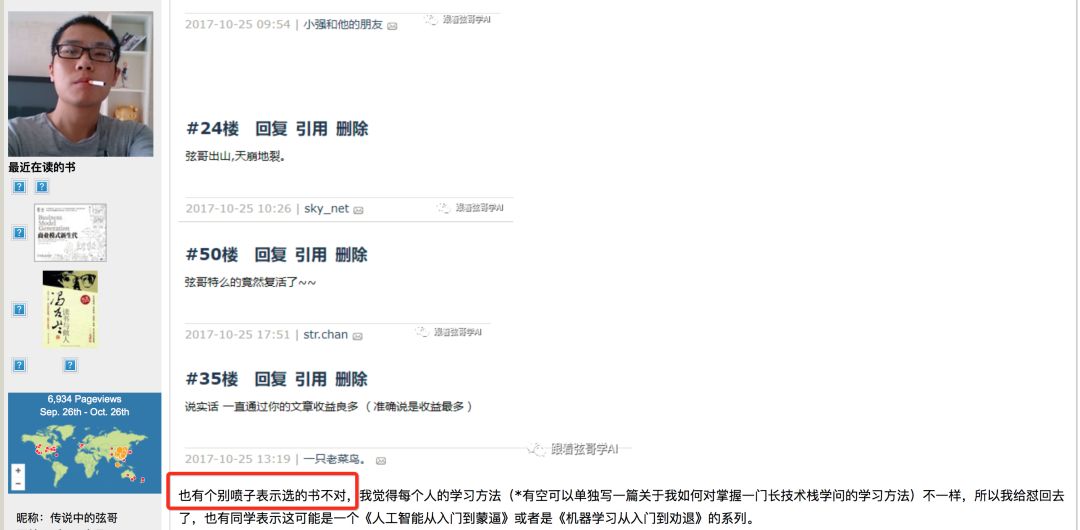
这我就不赞同而且不能忍了。对于任何人,不管你是大牛还是小白,我的原则都是,你可以反驳我的建议,有理有据就行,如果我错了,那就改,没有错,那就互相讨论,交流一下,气场合说不定还能成为个朋友呢。但是对于别人真诚的建议您回以"喷子"是一个有教养的人的表现吗?仗着自己是"大牛",这样没有素质的怼不觉得脸红吗?并且,我之所以给出这个建议,有以下三点:
1.作为一个数学系的学生,学了四年数学,对于你胡乱给的参考书目非常的不赞同。一没有阶梯式,对新手不友好,您的标题和写这个系列的目的大概都是准备给小白看的,那么请问,一个小白需要看数学分析原理??学习人工智能有必要需要看普林斯顿微积分原理??以鄙人浅薄的认识来说,数学分析与高等数学最大的区别是同一个定理,高数只要求会用即可,数学分析本着严谨性,一定会给出证明。然而对于大多数人工智能里所需要的数学,您在工作中需要证明这个定理的正确性和完备性??等你证出来恐怕项目早就结了。您回复我说这只是参考书目不是推荐书目,但是下面的评论大多数是看到书单就决定放弃。您把这些书放出来,就对看您文章的人有一定的引导性,我认为您这是在误人子弟。二是我通过您参考的数目粗略的推导您自己可能都没有对整个人工智能的数学有个框架式的梳理,不然不会有如此不负责任的推荐。但是出于对您的尊重,我并没有质疑您的能力,仅仅在评论里对于新手适合的数学书目给了一个简短的推荐。
2.作为一个从事机器学习这一行两年多的程序媛,看到您推荐的计算机系列也认为非常的不靠谱。您推荐的这些书,我大部分都看过。尤其不推荐新手看的就是《算法导论》和《数据挖掘:概念与技术》,这两本书又厚又重,虽然内容全面讲的也不错,但是等你看完都不知道猴年马月了。新手需要的是什么?是上手!其次,《Python核心编程》您真的看完了吗?这本书并不是给Python新人读的,非常厚,而且有一定的难度,对于新手非常不友好。而且如果只是想做AI,那这本书的很多地方都不需要用到,web开发,Django框架对于我们AI工程师来说真的是必须的吗?不是。小白对于一本书没有重点和非重点的区分,花了大量的时间学了不需要的知识,真是得不偿失。给出引导性,针对性的推荐才是负责任的推荐。
3.对于深度学习方面书籍的推荐我就不吐槽了。槽点太多,无力吐槽。省点力气后面推荐真正适合不同阶段的新手阅读的书籍好了。
总结:这位大牛,我认为您可能在.net方面积累非常深,做的很好,吸引了一大波粉丝,这点我很佩服您。然而对于深度学习这一块您可能并不是很了解。对于一个您并不是很了解的领域,在这里毫不谦虚,对于别人的建议充耳不闻,还很得意的骂人“喷子”,恐怕您还是要多谦虚一点,多学习学习。从从业年龄来看,我是您的后辈,但从从事深度学习这个领域来看,您可能还是个新人,您说呢?并且到目前为止,您发了两篇文章在首页,都没有任何干货,希望您赶紧拿干货来打我的脸^_^
下面,开始输出干货。
AI处于目前的风口,于是很多人想要浑水摸鱼,都来分一杯羹,然而可能很多人连AI是什么都不知道。AI,深度学习,机器学习,数据挖掘,数据分析这几点的联系和区别也搞不清楚。
我认为,深度学习这块,有几个层次:(自己胡乱起的名字,忽略吧 - -)
demo侠--->调参侠--->懂原理侠--->懂原理+能改模型细节侠--->超大数据操控侠--->模型/框架架构师
demo侠:下载了目前所有流行的框架,对不同框里的例子都跑一跑,看看结果,觉得不错就行了,进而觉得,嘛,深度学习也不过如此嘛,没有多难啊。这种人,我在面试的时候遇到了不少,很多学生或者刚转行的上来就是讲一个demo,手写数字识别,cifar10数据的图像分类等等,然而你问他这个手写数字识别的具体过程如何实现的?现在效果是不是目前做好的,可以再优化一下吗?为什么激活函数要选这个,可以选别的吗?CNN的原理能简单讲讲吗?懵逼了。
调参侠:此类人可能不局限于跑了几个demo,对于模型里的参数也做了一些调整,不管调的好不好,先试了再说,每个都试一下,学习率调大了准确率下降了,那就调小一点,那个参数不知道啥意思,随便改一下值测一下准确率吧。这是大多数初级深度学习工程师的现状。当然,并不是这样不好,对于demo侠来说,已经进步了不少了,起码有思考。然而如果你问,你调整的这个参数为什么会对模型的准确率带来这些影响,这个参数调大调小对结果又会有哪些影响,就又是一问三不知了。
懂原理侠:抱歉我起了个这么蠢的名字。但是,进阶到这一步,已经可以算是入门了,可以找一份能养活自己的工作了。CNN,RNN,LSTM信手拈来,原理讲的溜的飞起,对于不同的参数对模型的影响也是说的有理有据,然而,如果你要问,你可以手动写一个CNN吗?不用调包,实现一个最基础的网络结构即可,又gg了。
懂原理+能改模型细节侠:如果你到了这一步,恭喜你,入门了。对于任何一个做机器学习/深度学习的人来说,只懂原理是远远不够的,因为公司不是招你来做研究员的,来了就要干活,干活就要落地。既然要落地,那就对于每一个你熟悉的,常见的模型能够自己手动写代码运行出来,这样对于公司的一些业务,可以对模型进行适当的调整和改动,来适应不同的业务场景。这也是大多数一二线公司的工程师们的现状。然而,对于模型的整体架构能力,超大数据的分布式运行能力,方案设计可能还有所欠缺,本人也一直在这个阶段不停努力,希望能够更进一步。
超大数据操控侠:到这一阶段,基本上开始考虑超大数据的分布式运行方案,对整体架构有一个宏观的了解,对不同的框架也能指点一二。海量数据的分布式运行如何避免网络通信的延迟,如何更高效更迅速的训练都有一定经验。这类人,一般就是我这种虾米的领导了。
模型/框架架构师:前面说了一堆都是对现有的框架/模型处理的经验,这个阶段的大侠,哦,不对,是大师可以独立设计开发一套新框架/算法来应对现有的业务场景,或者解决一直未解决的历史遗留问题。没啥好说了,膜拜!
说了这么多,希望大家对自己找个清洗准确的定位,这样才能针对性的学习。下面基于我个人的经验对不同阶段的学习者做一些推荐:
demo侠+调参侠:这两个放在一起说,毕竟五十步笑百步,谁也没有比谁强多少。当然也不要妄自菲薄,大家都是从这个阶段过来的。这个阶段编程不好的就好好练编程,原理不懂的就好好看书理解原理。动手做是第一位,然后不断改一些模型的参数,看效果变化,再看背后的数学推导,理解原因,这样比先看一大堆数学公式的推导,把自己绕的晕晕乎乎在开始写代码要好得多。
推荐书目:
数学类:
高等数学(同济第七版):没错我说的就是考研的那本参考书,真心不错,难易适中,配合相应的视频或者国外的一些基础课程的视频看,高数理解极限,导数,微分,积分就差不多了
高等数学(北大第三版):线性代数的书我看的不多,原来上学的时候学的是高等数学,不过不要紧,看前五章就行了。配合相应的视频,掌握矩阵,行列式相关知识即可。
概率论:这个没有特别推荐的,因为学的并是不很好,所以不做推荐误人子弟。大家不管看什么书,只要掌握关键知识就行了。不能到时候问个贝叶斯你都不知道咋推吧 = =!
信息论:忘记是哪个出版社了的,很薄的一本,讲的非常不错。里面关于信息的度量,熵的理解,马尔科夫过程都讲的不错(现在公司里没有,我回去找找再补上来)。掌握这个知识,那么对于你理解交叉熵,相对熵这一大堆名字看起来差不多但是又容易弄混的东东还是不错的。起码你知道了为啥很多机器学习算法喜欢用交叉熵来做cost function~
编程类:
笨方法学Python(Learn Python the Hard Way)这本书对于完全没有接触过Python,或者说完全没有接触过编程的人来说非常适合。虽然很多人说Python这么简单,一天/周/月就学会了,但是每个人的基础是不一样的,所以不要认为自己一天没学会就很认为自己很蠢,你应该想这样说的人很坏!不管怎么样,这是一本真正的从零开始学Python的书
利用Python进行数据分析:这本书是Python的pandas这个包的详细说明版。学习这个可以掌握一些pandas的基本命令。然而这不是重点,因为pandas出来大量数据实在太慢了,还可能会崩溃(不知道现在有没有改善 - -!)重点是,通过学习这本书,对数据的操作有点感觉,熟悉基本的数据操作流程,里面所有的操作都可以用原生python来替代,不需要用到pandas这个包。找感觉,非常重要。
Python参考手册:这本书只是作为一个工具书,当你遇到不会的时候翻翻书,巩固一下(当然,事实可能是直接去google了),此类书不用全部从头到尾刷完,查漏补缺即可(电子书就行)
算法类:
Deep Learning with Python:别看这又是一本英文书,但其实非常简单易读。这本书其实主要是一个demo例子的集合,用keras写的,没有什么深度,主要是消除你对深度学习的畏难情绪,可以开始上手做,对整体能够做的事做一些宏观的展现。可以说,这本书是demo侠的最爱啦!
Deep Learning:中文有翻译版的出来了,不过我其实不太想放在这里,因为这本书其实很偏理论。有些章节讲的是真不错,有些地方你完了又会觉得,这是啥?这玩意有啥用?会把新手绕来绕去的。大家就先买一本镇场子,有不懂的翻翻看,看不懂的就google,直接看论文,看别人总结的不错的博客,等等。总之只要你能把不懂的弄懂就行了。
懂原理侠:很不错,你的经验值已经提升了不少了。然而还不能开始打怪,毕竟没有那个怪物可以直接被喷死的。你缺少工具。那么这个阶段,就需要多多加强编程能力。先找一个框架下下来,阅读源码,什么?你说你不会阅读源码,没关系,网上一大堆阅读源码的经验。当然,这些经验的基础无一例外都是:多读多写。在此基础上再找trick。下好框架的源码后,改动一些代码在运行,debug一下,再不断的找原因,看看每个api是怎么写的,自己试着写一写。多谢多练,死磕coding三十年,你一定会有收获的。
懂原理+能改模型细节侠:看论文看论文看论文!读源码读源码读源码!这里的读源码不仅仅局限于读一个框架的源码了,可以多看看其他优秀的框架,对于同一个层,同一个功能的实现机制,多比较多思考多总结多写。时间长了,肯定会有收获的。看论文是为了直接获得原作者的思想,避免了从博客解读论文里获得二手思想,毕竟每个人的理解都不一样,而且也不一定对,自己先看一遍,再看看别的理解,多和大牛讨论,思路就开阔了。
超大数据操控侠:这个阶段我也还在摸索,给不了太多建议,只能给出目前总结的一点点经验:尽量扩大数据,看如何更快更好的处理。更快--采用分布式机制应该如何训练?模型并行还是数据并行?多机多卡之间如何减少机器之间的网络延迟和IO时间等等都是要思考的问题。更好--如何保证在提升速度的同时尽量减少精度的损失?如何改动可以提高模型的准确率、mAP等,也都是值得思考的问题。
模型/框架架构师:抱歉,我不懂,不写了。
总结:
其实大家从我上面的推荐来看,打好基础是非常重要的,后续都是不断的多读优秀的论文/框架,多比较/实践和debug,就能一点点进步。打基础的阶段一定不能浮躁。扎扎实实把基础打好,后面会少走很多弯路。不要跟风盲目崇拜,经典永远不会过时,自己多看书/视频/优秀的博客,比无脑跟风要强得多。最后,我之所以今天这么生气,是因为这个行业目前太浮躁了,很多人太浮夸,误人子弟,有人说真话还被人骂喷子,真是气死我了!大家一定要擦亮双眼,多靠自己多努力。
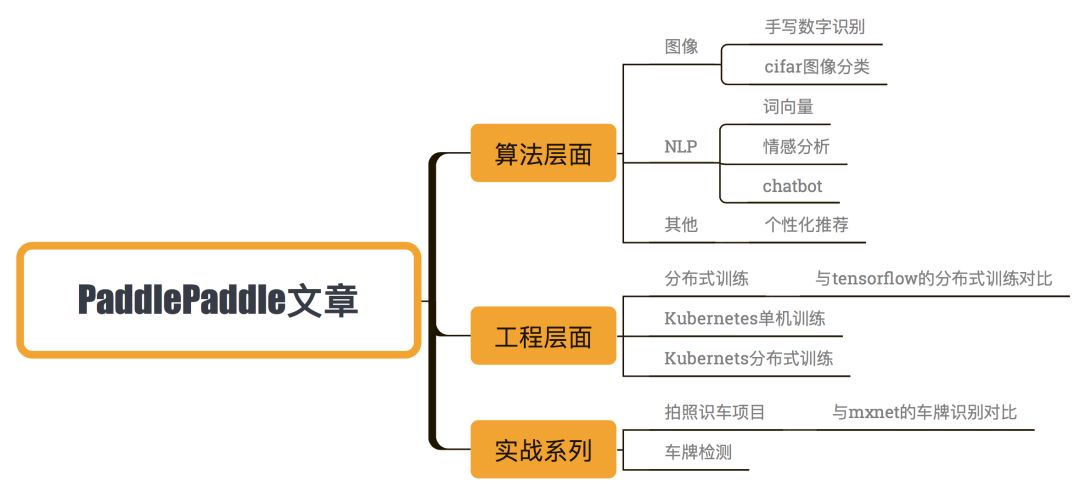
不好意思强行鸡汤了一波。本来去年打算写一个机器学习系列,但是因为工作和身体的原因写了三篇就没有更了。今年上半年做了一个大项目又累得要死,下半年才刚刚缓口气,所以之前欠的后续一定会继续更。为了不让大家盲目崇拜,我决定写一个深度学习系列,每周固定一篇,大概三个月完结。教小白如何入门。并且完!全!免!费!!不是简单的写写网上都有的demo和调参。拒绝demo侠从我做起!有不懂的欢迎大家在我的文章下留言,我看到了会尽量回复的。这个系列主要会采取PaddlaPaddle这个深度学习框架,同时会对比keras,tensorflow和mxnet这三个框架的优劣(因为我只用过这四个,写tensorflow的人太多了,paddlepaddle我目前用的还不错,就决定从这个入手),所有代码会放在github上(链接:https://github.com/huxiaoman7/PaddlePaddle_code),欢迎大家提issue和star。目前只写了第一篇(【深度学习系列】PaddlePaddle之手写数字识别),后面会有更深入的讲解和代码。目前做了个简单的大纲,大家如果有感兴趣的方向可以给我留言,我会参考加进去的~
最后一句,低调做人,好好学习,大家下期再会^_^!
-
python
+关注
关注
56文章
4811浏览量
85124 -
大数据
+关注
关注
64文章
8915浏览量
137920 -
深度学习
+关注
关注
73文章
5521浏览量
121679
原文标题:【好书推荐&学习阶段】三个月教你从零入门深度学习
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器学习和深度学习的区别在哪?看完就知道了
通俗易懂的PID教程
通俗易懂系列整合—电源基础知识讲解
FPGA通俗易懂入门书籍教程


通俗易懂的讲解FFT的让你快速了解FFT
关于机器学习通俗易懂的讲解






 工商网监
工商网监
评论